
Top 13 GAN Use Cases
{kind=link}
While GANs pioneered many early generative AI applications, particularly in image synthesis and style transfer, most consumer-facing generative AI tools today rely on diffusion-based architectures or related approaches such as flow matching and diffusion transformers (DiT).
However, GANs remain important in specific domains, such as super-resolution, face restoration, the generation of synthetic tabular or healthcare data, and applications requiring low-latency real-time inference.
In addition, architectural ideas introduced by GAN research continue to influence newer generative modeling approaches.
Top 13 GAN Use Cases
While diffusion models, flow matching models, and autoregressive transformers now dominate most consumer-facing generative AI tools, GANs remain useful in applications where speed, synthetic data generation, or adversarial training provides a practical advantage.
1. Synthetic healthcare/medical data
GANs can generate synthetic medical images and signals that resemble real patient data, including:
- MRI scans
- CT scans
- X-rays
- ECG signals
- Histopathology images
For example, a rare disease model may not have enough real examples to train a reliable classifier. GAN-generated samples can help augment the minority class and improve downstream model performance.
However, synthetic medical data should not be treated as a direct replacement for clinical data. It should be validated with domain experts and tested on downstream diagnostic tasks.
2. Synthetic tabular data
GANs can also generate synthetic tabular data, such as rows in a database. For example, GAN-based tabular data generators can create synthetic:
- Financial transactions
- Customer records
- Insurance claims
- Credit risk data
- Healthcare records
- Test datasets for software teams
Models such as CTGAN are designed to handle mixed data types, including categorical and continuous variables. This makes them more practical for enterprise datasets than image-focused GAN architectures.1
Synthetic tabular data can help organizations share data internally, test analytics workflows, or train machine learning models while reducing exposure of sensitive customer or patient information. Privacy tests should still be used because poorly trained models can memorize real records.
3. Fraud detection and anomaly detection
GANs are useful in fraud detection because fraud datasets are usually highly imbalanced: most transactions are legitimate, while fraudulent transactions are rare. GANs can help in two ways:
- The generator creates realistic synthetic fraud examples to improve classifier training.
- The discriminator can support anomaly detection by learning the difference between normal and abnormal patterns.
This makes GANs useful in:
- Credit card fraud detection
- Anti-money laundering systems
- Insurance fraud detection
- Network intrusion detection
- Cybersecurity anomaly detection
For example, banks and cybersecurity teams can use GAN-based augmentation to create more examples of rare attacks or fraud patterns, improving model recall on minority classes.
4. Image generation
Generative adversarial networks allow users to generate photorealistic images based on specific text descriptions (see Figure 1), such as:
- Setting
- Subject
- Style
- Location.
This process can be tested with various adversarial inputs to see how image generation is against slight perturbations in the input.
5. Image-to-image translation
GAN creates fake images from input images by transforming the external features, such as its color, medium, or form, while preserving its internal components (see Figure 2). This can be used as a general image editing method. Understanding how GANs handle adversarial inputs in image translation is crucial for maintaining the integrity and quality of the output.
Figure 1: An example of facial attribute manipulation.2
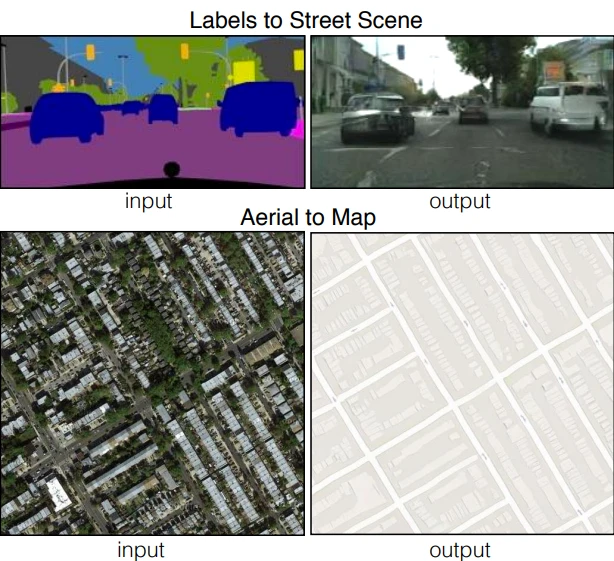
6. Semantic image-to-photo translation
GANs can transform one image domain into another while preserving important structure. Examples include:
- Day-to-night image conversion
- Sketch-to-image generation
- Satellite-to-map translation
- Low-light image enhancement
- Medical modality translation
- Facial attribute editing
For paired datasets, pix2pix is a common conditional GAN approach. For unpaired datasets, CycleGAN can learn domain translation without requiring exact input-output image pairs.
Figure 2: An example of a semantic image-to-photo translation.3
7. Super resolution and face restoration
GANs can improve the quality of low-resolution images and videos by generating missing details. This is used for:
- Image upscaling
- Video restoration
- Old photo restoration
- Face restoration
- Noise removal
- Colorization
- 4K or higher resolution enhancement
GAN-based super-resolution models are often faster than diffusion-based enhancement methods because they can generate outputs in a single forward pass.
For example, ESRGAN4 and Real-ESRGAN5 are used for image and video upscaling, while face restoration models such as GFPGAN6 use GAN-based priors to restore degraded facial images.
Figure 3: GAN-based restoration of images.7
8. Video prediction
A video prediction system with generative adversarial networks is able to:
- Understand the temporal and spatial elements of a video
- Generate the next sequence based on that understanding (as shown in Figure 5)
- Differentiate between probable and non-probable sequences
Figure 4: Prediction results for an action test split. a: Input, b: Ground Truth, c: FutureGAN.8
9. Text-to-speech conversion
Generative adversarial networks facilitate the generation of lifelike speech sounds. The discriminators act as trainers that refine the voice by emphasizing, adjusting, and modifying the tone.
Text-to-speech conversion technology has various commercial applications, including:
For instance, an educator can turn their lecture notes into an audio format to make them more engaging, and this same approach can be used to create educational resources for those with visual impairments.
10. Style transfer
GANs can be used to transfer style from one image to another, such as generating a painting in the style of Vincent van Gogh from a photograph of a landscape (see Figure 6).
Figure 5: The cycleGAN generates designs in the style of different artists and artistic genres, such as Monet, van Gogh, Cezanne and Ukiyo-e.9
11. 3D object generation
GAN-based shape generation allows for the creation of shapes that more closely resemble the original source. Also, it is possible to generate and modify detailed shapes to achieve the desired result. See the GANs-generated 3D objects in Figure 7 below.
Figure 6: Shapes synthesized by 3D-GAN.10
The video below shows this process of object generation.
12. Video generation
GANs can be used to generate videos, such as synthesizing new scenes in a movie or generating new advertisements. However, such GAN-generated content, called deepfakes, can be difficult or impossible to distinguish from real media, posing serious ethical implications for generative AI (see the video below).
13. Text generation
With the large language models, generative AI based on GAN model has a range of applications in text generation, including:
- Articles
- Blog posts
- Product descriptions
These AI-generated texts can be used for a variety of purposes, such as social media content, advertising, research, and communication.
In addition, it can be used to summarize written content, making it a useful tool for quickly digesting and synthesizing large amounts of information.
GAN tools
GANs’ architecture
GANs operate on a two-model architecture locked in a continuous competition: the generator and the discriminator.
- Generator (The Forger): This neural network creates new data (e.g., images, text, audio) from random noise, aiming to produce content indistinguishable from real-world data.
- Discriminator (The Detective): This is a binary classifier network that examines a sample and decides if it is real(from the original dataset) or fake (produced by the Generator).
The training process
The two models are trained simultaneously in a minimax game. The generator tries to minimize the discriminator’s ability to spot fakes, while the discriminator tries to maximize its accuracy.
This adversarial process forces the Generator to continuously improve its output quality until the discriminator can guess with 50% accuracy, meaning the generated content is highly realistic.
Why GANs are fast at inference
GANs are fast because the trained generator can usually create a sample in a single forward pass.
Diffusion models work differently. They typically start with noise and iteratively denoise it over multiple steps. This process often improves quality and diversity, but it also increases inference time.
This is the main reason GANs remain useful in real-time and latency-sensitive applications, even though diffusion models dominate many consumer-facing generation tasks.
GANs evaluation metrics
GAN output quality is usually measured with both quantitative metrics and human evaluation. Common metrics include:
- Fréchet Inception Distance (FID): Compares the feature distribution of generated images with real images. Lower FID usually indicates that generated samples are closer to real images.
- Inception Score (IS): Measures whether generated images are both recognizable and diverse. Higher scores are generally better, but IS is less reliable than FID because it does not compare generated images directly with a real dataset.
- Downstream task performance: Measures whether synthetic data improves a classifier, detector, segmenter, or anomaly detection model.
- Expert review: Especially important in domains such as healthcare, finance, and cybersecurity.
For medical and enterprise use cases, FID alone is not enough. The generated data should also be tested for privacy leakage, bias, statistical similarity, and usefulness in downstream models.
{kind=link}
Add as preferred source
GAN limitations and ethical implications
While powerful, GANs have critical drawbacks and ethical considerations:
Technical limitations
Training instability
GANs can be challenging to train and configure since they often fail to converge. A common issue is vanishing gradients, where one model learns too quickly and the other stops improving.
Mode collapse
Mode collapse occurs when the Generator network produces a limited variety of outputs, focusing on a few specific “modes” of the data distribution while failing to capture its full diversity.
For example, GAN trained on celebrity faces might generate one or two similar-looking people.
Ethical implications
Deepfake technology
Deepfake technology powered by GANs can create hyper-realistic fabricated videos and audio recordings of individuals saying or doing things they never did.
For example, deepfakes can be weaponized for political manipulation, social unrest, and defamation, with misinformation spreading faster than the truth can be verified. This capability may undermine public trust in media and undermine the credibility of digital evidence.
Bias reinforcement
If the training data is biased, the GAN will reinforce that bias, making it difficult or impossible to generate diverse, representative outputs. This can perpetuate societal biases in generated content.
For example, if a dataset includes mainly male faces for certain jobs, this will be reproduced in image generation.
To mitigate generative AI risks, address AI ethics issues, and align with AI compliance, consider implementing responsible AI principles, adapting responsible AI platforms, and adopting AI governance tools.
Cost and resources for deployment
Developing and deploying a GAN application is resource-intensive due to the demanding training process.
- Hardware: Training requires high-end GPUs (e.g., NVIDIA Blackwell B200 or H100/H200, with the next-generation Rubin platform arriving in 2026) with significant VRAM. Training an advanced model like StyleGAN can take weeks on powerful hardware.
- Cloud costs: Running these models on cloud platforms (AWS, Azure, GCP) can cost hundreds of dollars per day during intensive training periods.
- Expertise: A major cost factor is the requirement for highly specialized ML engineers to manage the complex training process and mitigate.
Future of GANs
This rapid expansion is driven by the increasing demand for high-quality synthetic data to augment training sets for other AI models. Due to data scarcity issues, GANs can provide a means to protect sensitive information, particularly in fields like healthcare and finance, where privacy is paramount.
Advancements in architecture
Ongoing research continues to push the boundaries of GAN capabilities, with the development of more stable and versatile architectures. Beyond the foundational Vanilla GAN, several notable variants have emerged to solve specific problems:
- StyleGAN: This architecture is renowned for its ability to generate highly detailed and controllable photorealistic images, particularly human faces that do not belong to real people.
- CycleGAN: A groundbreaking architecture for unpaired image-to-image translation, which can convert images from one domain to another (e.g., turning a photo of a horse into a zebra) without requiring matched training pairs.
- Conditional GANs (cGANs): These architectures introduce the concept of “conditionality,” allowing for targeted data generation by providing class labels or other auxiliary information to both the generator and discriminator. This enables a user to specify the type of output they want to generate, such as an image of a specific object.
- Hybrid model: A key emerging research direction involves the integration of GANs with other advanced AI architectures. This hybrid model approach is a strategic frontier to combine the unique strengths of different architectures to tackle more complex, multi-modal problems.
- For example, combining the generative power of GANs with the sequential intelligence of Long Short-Term Memory (LSTM) networks can enable the generation of realistic sequential data, such as stock price movements or human dialogue.
Compare generative models
The choice of a generative model for a specific application is governed by a fundamental trade-off among output quality, training stability, and generation speed. No single architecture excels in all three domains, forcing a strategic decision based on the requirements of the task.
GANs vs. VAEs
Variational Autoencoders (VAEs) are another prominent class of generative models that differ fundamentally from GANs in their architecture and training objective.
Architectural differences
- VAEs: VAEs consist of an encoder network and a decoder network. The encoder compresses an input into a probabilistic latent representation. The decoder then reconstructs a new data sample from this latent space. The model’s objective is to maximize the likelihood of the input data while ensuring the latent variables conform to a prior distribution.
Strengths and weaknesses
- Benefits: VAEs are known for their training stability and are easier to train than GANs. Their explicit, meaningful latent space is well-suited for tasks like reconstruction and data interpolation.
- Drawbacks: A significant drawback is their tendency to produce blurry, less sharp images.
GANs vs. diffusion models
Diffusion models, a more recent class of generative models, have rapidly gained prominence for their exceptional output quality and training stability.
Architectural differences
- Diffusion models: Diffusion models operate through a multi-step process involving a forward diffusion process and a reverse denoising process. In the forward process, noise is progressively added to an image until pure noise remains. A neural network then learns to perform the reverse process, gradually denoising the image to reconstruct the original data.
Strengths and weaknesses
- Benefits: They exhibit superior training stability compared to GANs because their training objective doesn’t involve a dynamic adversarial game. They are less prone to mode collapse and can generate highly diverse and high-quality outputs.
- Drawbacks: The iterative denoising process makes them significantly slower at inference time compared to GANs, which can generate a sample in a single forward pass.
GANs vs. Flow Matching Models
Flow Matching (FM) is a newer generative modeling framework that has gained attention as a scalable alternative to diffusion models and GANs. Introduced to train continuous normalizing flows efficiently, flow matching learns a vector field that transports samples from a simple distribution (e.g., Gaussian noise) to the target data distribution.
Architectural differences
- Flow matching models train a neural network to learn a continuous vector field that gradually transforms noise into real data along a predefined probability path. This framework generalizes diffusion models and continuous normalizing flows while allowing flexible path choices such as optimal transport trajectories.
Strengths
- Simpler training: No adversarial game, which avoids instability and mode collapse common in GAN training.
- Efficient sampling: Flow matching can use optimal transport paths, which create straighter trajectories from noise to data and require fewer inference steps than diffusion models.
- Unified framework: Diffusion models can be viewed as a special case of flow matching with a specific probability path.
- State-of-the-art performance: Flow-based generative models have achieved strong results across domains, including images, video, speech, and biological structures.
Weaknesses
- Higher implementation complexity: Training continuous flow models typically requires solving differential equations during inference.
- Less mature ecosystem: Compared with GANs and diffusion models, tooling and production deployment frameworks are still evolving.
Position in the generative model landscape
Flow matching models are increasingly used in modern generative systems because they combine the training stability of diffusion models with faster inference paths. As a result, they are emerging as a strong candidate for next-generation generative AI architectures.
At the same time, other paradigms continue to evolve. For example, autoregressive image generation models, such as GPT Image 1, generate images token-by-token similarly to large language models. These models demonstrate that sequential autoregressive generation can also achieve high-quality image synthesis, providing another alternative to GANs and diffusion-based approaches.
Cite this research
Pick the format that matches where you're publishing. Pasting the link version into your CMS preserves the backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Top 13 GAN Use Cases}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/gan-use-cases}},
note = {AIMultiple. Retrieved June 24, 2026}
}Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
Be the first to comment
Your email address will not be published. All fields are required. Comments are left in their original language.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}