
{kind=link}
Claude Code Builds a Multi-Model Odds Alert Router: claude-fable-5 vs GPT-5.5 vs Qwen#
The previous project in this series built a World Cup odds movement monitor with Claude Code and claude-fable-5.
That project answered one question:
Can Claude Code build a monitoring pipeline and use
claude-fable-5to summarize odds alerts as valid JSON?
The next question is more important for production:
What happens when the model fails?
So this third project turns the odds monitor into a multi-model alert router.
Instead of trusting one model, we send the same structured task through several routes on Crazyrouter:
claude-fable-5gpt-5.5qwen-plusgemini-2.5-flash
Then we measure:
- HTTP status;
- latency;
- token usage;
- valid JSON;
- required schema keys;
- fallback order.
This is still an analytics engineering demo. It is not betting advice.
Why this topic matters#
Most AI examples stop at a successful single model call.
That is not enough for real systems.
If your application depends on structured output, the real question is not:
Which model sounds smartest?
The real question is:
Which model returns a usable object for this exact workflow?
For an odds alert dashboard, the output must be machine-readable. A beautiful paragraph is not enough. The application needs valid JSON with expected keys.
So the router treats these as failures:
- HTTP error;
- invalid JSON;
- missing required keys;
- timeout;
- output wrapped in a format the parser cannot handle;
- truncated JSON.
That is the difference between a demo and a production workflow.
Input: the same odds alerts as before#
The input comes from the previous odds movement monitor.
The Python script converted decimal odds into implied probability changes and flagged movements above a threshold.
Example alerts:
[
{
"match": "USA vs Paraguay",
"market": "USA win",
"direction": "shortened",
"delta_pp": 2.62
},
{
"match": "Qatar vs Canada",
"market": "Canada win",
"direction": "shortened",
"delta_pp": 4.01
},
{
"match": "Germany vs Curaçao",
"market": "Germany win",
"direction": "shortened",
"delta_pp": 2.87
}
]
The router task is not to predict match results.
The task is to summarize the alerts as a safe engineering report.
Required JSON keys:
summary
model_fit
top_movement
validation_risks
fallback_recommendation
disclaimer
Crazyrouter setup#
The test used the same OpenAI-compatible API base URL:
https://cn.crazyrouter.com/v1
The request shape was intentionally compact:
payload = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 700,
"temperature": 0.1
}
The prompt explicitly required:
Return raw valid JSON only. No markdown.
Do not provide betting advice.
The router then attempted to parse each response and check required keys.
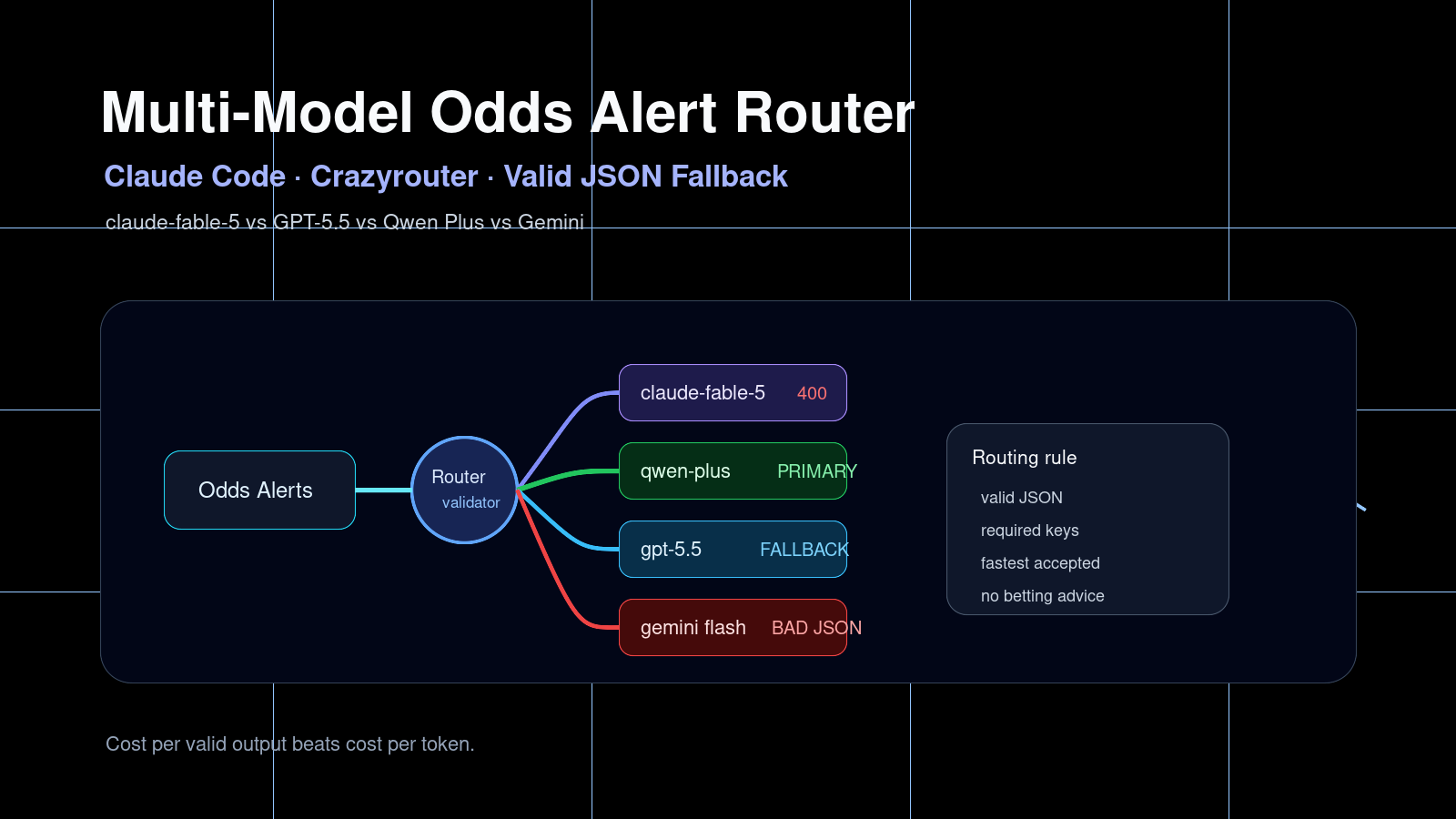
The benchmark result#
Here is the real test result:
| Model | HTTP | Latency | Total tokens | Valid JSON | Result |
|---|---|---|---|---|---|
claude-fable-5 | 400 | 1.09s | — | False | Invalid request |
gpt-5.5 | 200 | 8.07s | 950 | True | Valid fallback |
qwen-plus | 200 | 5.68s | 601 | True | Best primary |
gemini-2.5-flash | 200 | 4.70s | 1020 | False | Truncated JSON |
The router recommendation was:
{
"primary": "qwen-plus",
"fallback_order": ["gpt-5.5"],
"rule": "Pick the fastest model that returns valid JSON with all required keys; fallback on HTTP error, invalid JSON, missing keys, or timeout."
}
This is exactly why model routing matters.
The fastest HTTP response was not the best production route. Gemini responded quickly, but produced invalid JSON. claude-fable-5 had worked in the previous article with a slightly different payload, but returned HTTP 400 here.
For this exact task, qwen-plus won because it returned valid JSON faster than gpt-5.5.
What qwen-plus returned#
The qwen-plus response passed all required keys:
{
"summary": "Four significant odds movements detected across three matches, with the largest delta_pp observed in 'Qatar vs Canada' for 'Canada win' (+4.01 percentage points). Movements suggest potential market sentiment shifts or data anomalies requiring verification.",
"model_fit": "Moderate; model captures directional movement and magnitude but does not incorporate real-time news, lineup changes, or liquidity metrics—these require external validation.",
"top_movement": {
"match": "Qatar vs Canada",
"market": "Canada win",
"delta_pp": 4.01
},
"validation_risks": [
"Lack of integration with live news or official lineup announcements",
"Potential latency or sampling bias in odds ingestion pipeline",
"No liquidity or volume context to distinguish informed betting from noise",
"Implied probability conversion assumes efficient, zero-margin markets"
],
"fallback_recommendation": "Cross-reference with official team announcements, verified injury reports, and historical odds volatility benchmarks before drawing conclusions.",
"disclaimer": "This analysis is for demonstration purposes only. Odds movements reflect observed market data and do not indicate predictive accuracy, event outcome likelihood, or betting value."
}
That is not a betting recommendation. It is a data-quality and monitoring summary.
What GPT-5.5 returned#
gpt-5.5 was slower but also valid.
Its output included stronger caveats:
{
"summary": "Four odds movement alerts were detected across three matches. The largest absolute implied-probability movement was Canada win in Qatar vs Canada, which shortened by 4.01 percentage points.",
"model_fit": "Descriptive odds-movement monitoring fit: suitable for identifying unusual market shifts and prioritizing validation workflows; not sufficient on its own for causal attribution or predictive conclusions.",
"fallback_recommendation": "If validation inputs are incomplete, classify these as provisional movement alerts and defer interpretation until odds feeds, liquidity context, team news, and timestamp alignment are confirmed.",
"disclaimer": "This analysis is for sports analytics dashboard validation and monitoring purposes only and does not provide betting advice."
}
This makes gpt-5.5 a good fallback candidate.
If the primary route fails, it can provide a more conservative explanation.
Why claude-fable-5 failed here#
This is the most interesting part.
In the previous project, claude-fable-5 successfully returned valid JSON when the request was compact and tuned for that model.
In this router benchmark, the request used the same payload shape across all models.
claude-fable-5 returned:
HTTP 400
Invalid request
That does not mean the model is bad.
It means payload compatibility is part of production model quality.
A model can be useful in one request shape and fail in another. If your application routes dynamically, the router must understand those differences.
This is a very practical lesson:
Do not only benchmark models.
Benchmark model + payload + task + validator.
Why Gemini failed here#
gemini-2.5-flash returned HTTP 200, but failed JSON parsing.
The content started like valid JSON but was truncated:
JSONDecodeError: Unterminated string
That is a different failure mode from claude-fable-5.
One model failed at the request layer.
Another model failed at the output layer.
The router must treat both as failures.
This is why HTTP status alone is not enough.
Router rule#
The router rule for this demo is simple:
Use the fastest model that returns valid JSON with all required keys.
Fallback on HTTP error, invalid JSON, missing keys, or timeout.
Pseudo-code:
for model in candidate_models:
response = call_model(model, prompt)
if response.http_status != 200:
mark_failed(model, "http_error")
continue
parsed = try_parse_json(response.content)
if not parsed:
mark_failed(model, "invalid_json")
continue
if missing_required_keys(parsed):
mark_failed(model, "missing_keys")
continue
return accepted_output(model, parsed)
This is boring code, but it is what makes AI workflows usable.
Cost per valid output beats cost per token#
A pricing page tells you cost per token.
A production workflow cares about cost per valid output.
Those are not the same.
A cheap model that returns invalid JSON may trigger retries and fallback calls. A more expensive model may be cheaper for the actual workflow if it succeeds more often.
For this benchmark, the router would choose:
Primary: qwen-plus
Fallback: gpt-5.5
Blocked for this payload: claude-fable-5
Rejected output: gemini-2.5-flash
That does not mean Qwen is always better. It means Qwen was better for this exact payload and schema.
That is the point.
What Claude Code built#
Claude Code’s role here is not to pick a favorite model.
It should build the router and the evidence trail:
generated/claude_code_odds_router_20260613/
├── build_odds_alert_router.py
├── odds_alert_router_benchmark.json
├── raw_claude-fable-5.json
├── raw_gpt-5.5.json
├── raw_qwen-plus.json
└── raw_gemini-2.5-flash.json
This gives you:
- raw responses;
- latency records;
- token usage;
- parse results;
- schema validation;
- routing recommendation.
That is much more valuable than a single polished answer.
Why Crazyrouter is useful here#
Without an API gateway, this benchmark would require separate provider integrations.
With Crazyrouter, the test uses one interface:
one API key
one base URL
one chat/completions shape
multiple model routes
one validation layer
That makes it practical to route by task, not by brand loyalty.
For example:
- use
qwen-plusfor fast structured alert summaries; - fallback to
gpt-5.5when stricter explanation is needed; - tune
claude-fable-5with a compatible payload for tasks where it performs well; - reject any model output that fails validation.
This is how multi-model applications should be built.
Final takeaway#
The lesson from this project is simple:
In production AI, the best model is the one that returns an accepted output for the task.
Not the most hyped model.
Not the model with the fastest HTTP response.
Not the model you personally prefer.
For this odds alert router, the winner was qwen-plus, with gpt-5.5 as fallback. claude-fable-5 remains useful, but this payload needs tuning. gemini-2.5-flash was fast but invalid for the JSON workflow.
That is exactly why routers exist.
If you are building Claude Code projects that need structured output, model comparison, and fallback routing, try Crazyrouter:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}