
Creating Apache Kafka Topics Dynamically as Part of a DataFlow
Creating Kafka topics programmatically as part of streaming.
{kind=link}
Join the DZone community and get the full member experience.
Join For FreeApache Kafka is becoming the cornerstone for everything from event-driven microservices to IoT to CDC to log ingestion. Using Apache Kafka with proper enterprise tooling and Apache NiFi will let you do this with agility, stability, scalability, security, performance, and traceability. Using Apache NiFi's provenance/lineage will allow you to see everything going on with your pipelines from source to sinks, even if that includes 1,000 Kafka Topics.
Sometimes when you are ingesting data at scale, whether it is from a Data Warehouse, Logs, REST API, IoT, Social Media or other sources, you may need to create new Apache Kafka topics, depending on the type, variation, newness, schema, schema version, etc.
Instead of having to manually create an Apache Kafka topic with Cloudera Streams Messaging Manager or Apache Kafka command line (kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test), I would like to create it mid-stream based on names that are relevant to arriving data. This could be the name of the schema from the data, the table name of the original date, some unique name generated with the data, or another source. For my example, I am generating a unique name via Apache NiFi Expression Language:
nifi${now():format('yyyyMMddmmss')}${UUID()}
This is a Proof of Concept; there are more features I would add if I wanted this for production use cases, such as adding fields for Number Of Partitions and Number of Replicas. If this processor looks useful to you, or if you just want to try it out, the full Apache-licensed source code is included at the end of this article. Enjoy, fork, enhance and deploy!
Example Run Of Our New Processor
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The processor is very easy to use; you merely enter your Kafka Broker URL, such as demo.hortonworks.com:6667. Then, you can enter the name of your Kafka topic. The processor will validate to make sure you have a valid name, which should be Alphanumeric, with only the addition of periods, dashes, and underscores. It will run quickly. When completed, you can check out the results. Your flowfile will be unchanged, but you will get new attributes as seen below.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You will get kafka.bootstrap (your Broker URL), kafka.client.id (a generate one time use client id), kafka.topic.<TOPIC_NAME> — with one for each Kafka topic that exists, kafka.topic.creation.success, a status of flag, kafka.topic.message — a message, kafka.topic.YourNewNamed one.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In IntelliJ I quickly developed this program using the Apache Kafka Admin API and some JUnit tests. For a production use case, I would probably just use the Cloudera SMM REST API to create topics.
See: https://www.datainmotion.dev/2019/04/streams-messaging-manager-smm-rest-api.html
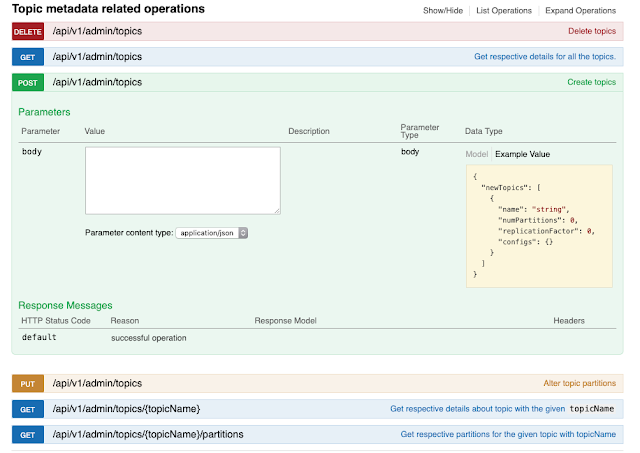
👁 Topic metadata related operations
{kind=link}
{kind=link}
It is trivial to call a REST API from Apache NiFi, so I can use an Apache NiFi flow to orchestrate an entire Kafka lifecycle with management and monitoring for real-time interaction.
Source Code for Custom Apache NiFi Processor
https://github.com/tspannhw/kafkaadmin-processor
Source Code for Apache Kafka Shell Scripts
Opinions expressed by DZone contributors are their own.
Related
-
NiFi In-Memory Processing
-
Real-Time Analytics: All Data, Any Data, Any Scale, at Any Time
-
Parallel Kafka Batch Processing With Kotlin Coroutines in Spring Boot
-
Combining Temporal and Kafka for Resilient Distributed Systems