
- DZone
- Data Engineering
- Databases
- Kafka Technical Overview
Kafka Technical Overview
In this post, we take a high-level look at the architecture of Apache Kafka, the role ZooKeeper plays, and more.
Join the DZone community and get the full member experience.
Join For FreeObjective
In this article series, we will learn Kafka basics, Kafka delivery semantics, and configuration to achieve different semantics, Spark Kafka integration, and optimization. In Part 1 of this series let’s understand Kafka basics. In Part 2 of this series, we'll learn more about Kafka producer and it's configuration.
Problem Statement
The following could be some of the problem statements:
- Many sources and target systems to integrate. Generally, the integration of many systems involves complexities like dealing with many protocols, messaging formats, etc.
- Message systems handle high volume streams.
👁 Integration of multiple source and target systems
Use Cases
Some of the use cases include:
- Streaming processing
- Tracking user activity, log aggregation, etc.
- De-coupling systems
👁 Integration of multiple source and target systems using Kafka
What Is Kafka?
Kafka is a horizontally scalable, fault tolerant, and fast messaging system. It’s a pub-sub model in which various producers and consumers can write and read. It decouples source and target systems. Some of the key features are:
- Scale to hundreds of nodes.
- Can handle millions of messages per second.
- Real-time processing (~10ms).
👁 Kafka producer consumer integration
Key Terminologies
Topic, Partitions, and Offsets
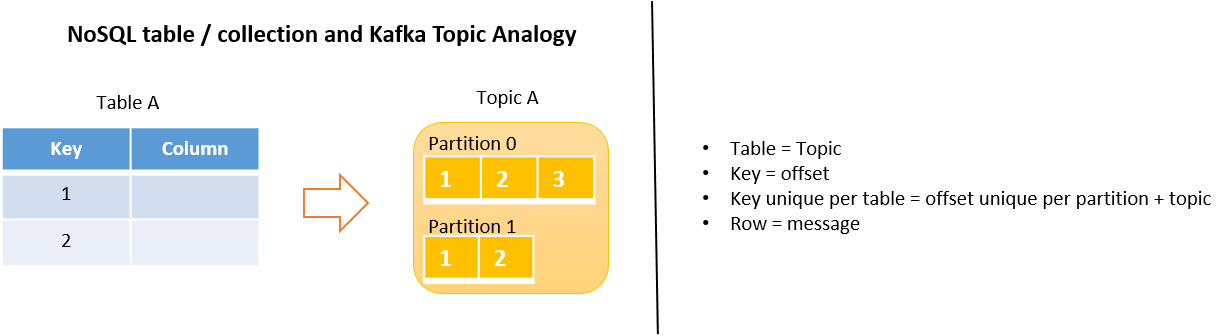
A topic is a specific stream of data. It is very similar to a table in a NoSQL database. Like tables in a NoSQL database, the topic is split into partitions that enable topics to be distributed across various nodes. Like primary keys in tables, topics have offsets per partitions. You can uniquely identify a message using its topic, partition, and offset.
👁 NoSQL table & Kafka topic analogy
{kind=link}
Partitions
Partitions enable topics to be distributed across the cluster. Partitions are a unit of parallelism for horizontal scalability. One topic can have more than one partition scaling across nodes.
👁 Kafka topic distribution across brokers
Messages are assigned to partitions based on partition keys; if there are no partition keys then the partition is randomly assigned. It’s important to use the correct key to avoid hotspots.
👁 Kafka partitions & offsets in a topic
Each message in a partition is assigned an incremental id called an offset. Offsets are unique per partition and messages are ordered only within a partition. Messages written to partitions are immutable.
Kafka Architecture
The diagram below shows the architecture of Kafka.
ZooKeeper
ZooKeeper is a centralized service for managing distributed systems. It offers hierarchical key-value store, configuration, synchronization, and name registry services to the distributed system it manages. ZooKeeper acts as ensemble layer (ties things together) and ensures high availability of the Kafka cluster. Kafka nodes are also called brokers. It’s important to understand that Kafka cannot work without ZooKeeper.
From the list of ZooKeeper nodes, one of the nodes is elected as a leader and the rest of the nodes follow the leader. In the case of a ZooKeeper node failure, one of the followers is elected as leader. More than one node is strongly recommended for high availability and more than 7 is not recommended.
ZooKeeper stores metadata and the current state of the Kafka cluster. For example, details like topic name, the number of partitions, replication, leader details of petitions, and consumer group details are stored in ZooKeeper. You can think of ZooKeeper like a project manager who manages resources in the project and remembers the state of the project.
👁 Zookeeper leader and follower in a Kafka cluster
Key things to remember:
- Manages list of brokers.
- Elects broker leaders when a broker goes down.
- Sends notifications on a new broker, new topic, deleted topic, lost brokers, etc.
- From Kafka 0.10 on, consumer offsets are not stored in ZooKeeper, only the metadata of the cluster is stored in ZooKeepr.
- The leader in ZooKeepr handles all writes and follower ZooKeepr handle only reads.
Broker
A broker is a single Kafka node that is managed by ZooKeeper. A set of brokers form a Kafka cluster. Topics that are created in Kaka are distributed across brokers based on the partition, replication, and other factors. When a broker node fails based on the state stored in ZooKeeper it automatically rebalances the cluster and if a leader partition is lost then one of the follower petitions is elected as the leader.
👁 Broker and topic in a Kafka cluster
You can think of a broker as a team leader who takes care of the assigned tasks. If a team lead isn’t available then the manager takes care of assigning tasks to other team members.
Replication
👁 Partition replication in a Kafka cluster
A replication is making a copy of a partition available in another broker. Replication enables Kafka to be fault tolerant. When a partition of the topic is available in multiple brokers then one of the partitions in a broker is elected as the leader and the rest of the replications of the partition are followers.
👁 Partition replication by followers in a Kafka cluster
Replication enables Kafka to be fault tolerant even when a broker is down. For example, Topic B partition 0 is stored in both broker 0 and broker 1. Both producers and consumers are served only by the leader. In case of a broker failure the partition from another broker is elected as a leader and it starts serving the producers and consumer groups. Replica partitions that are in sync with the leader are flagged as ISR (In Sync Replica).
👁 Broker failure and partition leader election in a Kafka cluster
IT Team and Kafka Cluster Analogy
The diagram below depicts an analogy of an IT team and Kafka cluster.
👁 IT Team and Kafka cluster analogy
Summary
Below is the summary of core components in Kafka.
👁 Kafka component relationship
- ZooKeeper manages Kafka brokers and their metadata.
- Brokers are horizontally scalable Kafka nodes that contain topics and it's replications.
- Topics are message streams with one or more partitions.
- Partitions contains messages with unique offsets per partition.
- Replication enables Kafka to be fault tolerant using follower partitions.
Refer to Kafka's Quickstart docs for Kafka setup.
You can download the presentation of this article here. In Part 2 of this series, we'll learn more about Kafka producers and their configuration.
Opinions expressed by DZone contributors are their own.
Related
-
Data Migration from AWS DocumentDB to Atlas on AWS
-
Raft in Tarantool: How It Works and How to Use It
-
Synchronous Replication in Tarantool (Part 3)
-
Next-Gen Data Pipes With Spark, Kafka and k8s