
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
7 items • Updated • 9
SauerkrautLM-ColLFM2-450M-v0.1
🏆 #1 Small Model (<1B) | Best-in-Class Efficiency
SauerkrautLM-ColLFM2-450M-v0.1 is the #1 small model for visual document retrieval, achieving 83.56 NDCG@5 on ViDoRe v1 - beating colSmol-500M (82.49) with 10% fewer parameters!
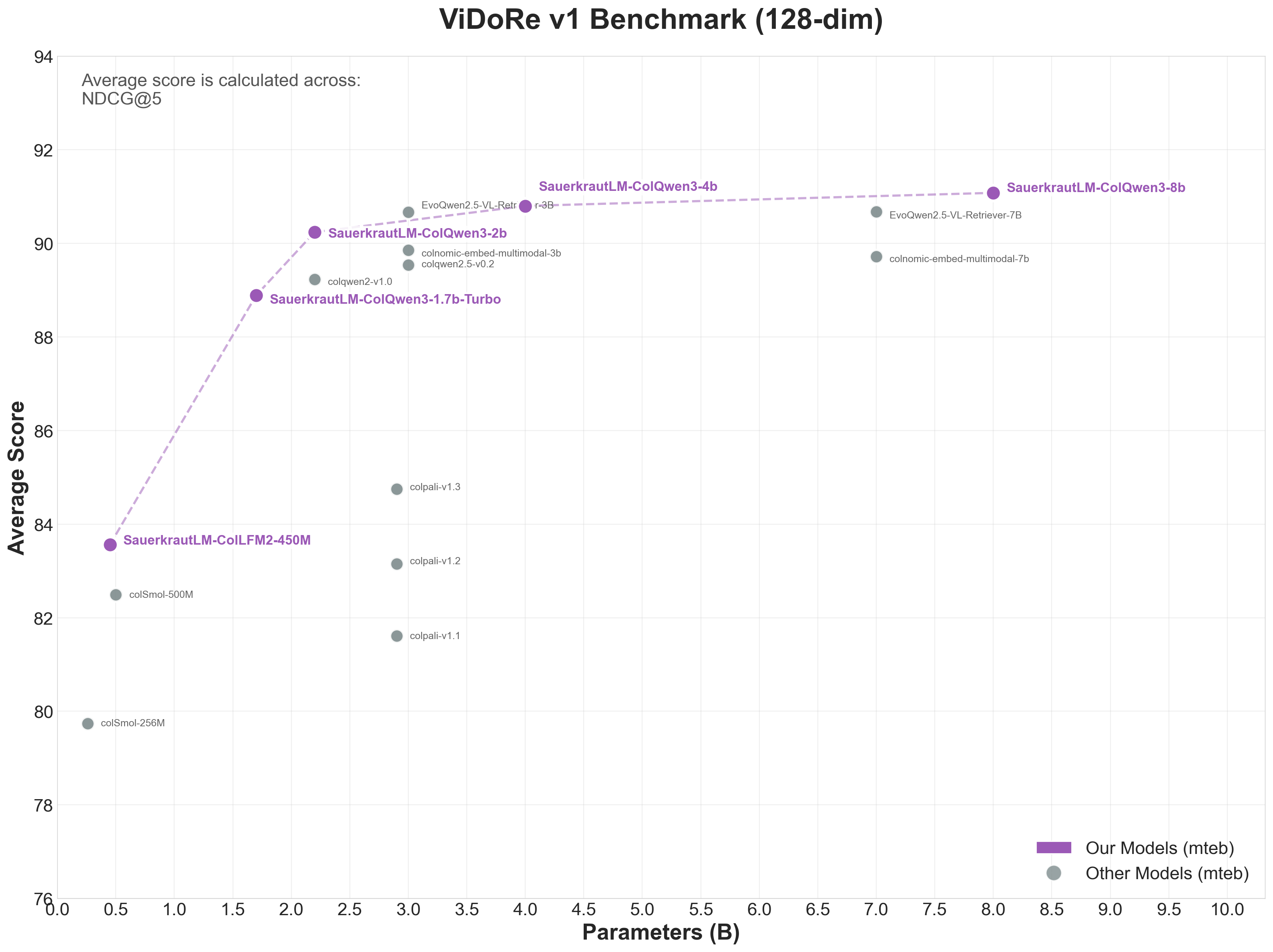
👁 ViDoRe v1 Benchmark - 128-dim Models
🎯 Why Visual Document Retrieval?
Traditional OCR-based retrieval loses layout, tables, and visual context. Our visual approach:
- ✅ No OCR errors - Direct visual understanding
- ✅ Layout-aware - Understands tables, forms, charts
- ✅ End-to-end - Single model, no pipeline complexity
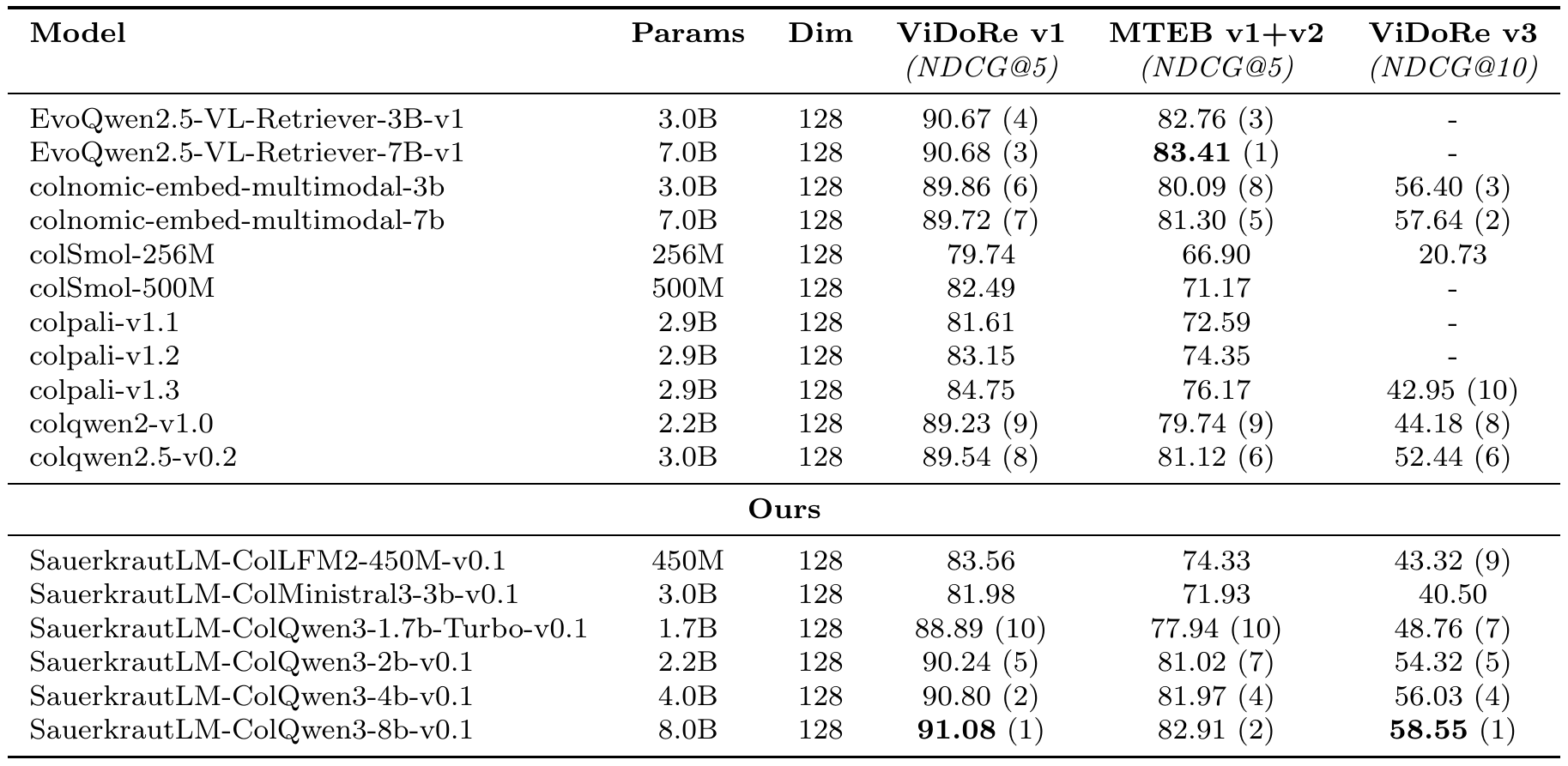
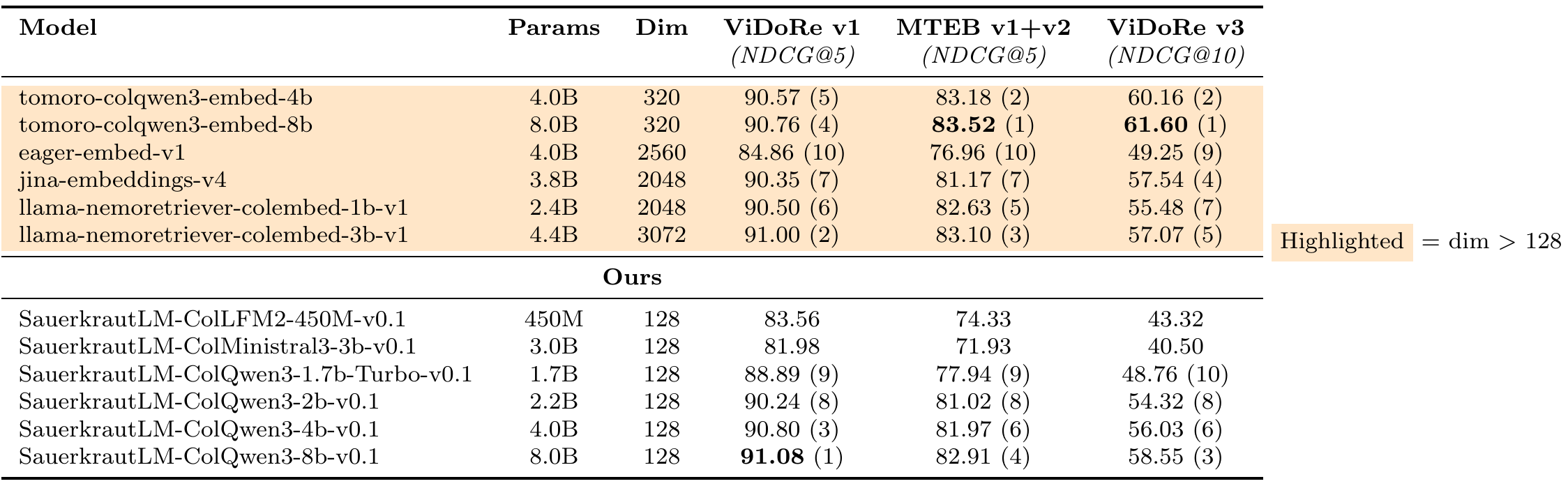
🏆 Key Achievements
| Benchmark | Score | Rank (Small <1B) |
|---|---|---|
| ViDoRe v1 | 83.56 | 🥇 #1 |
| MTEB v1+v2 | 74.33 | 🥇 #1 |
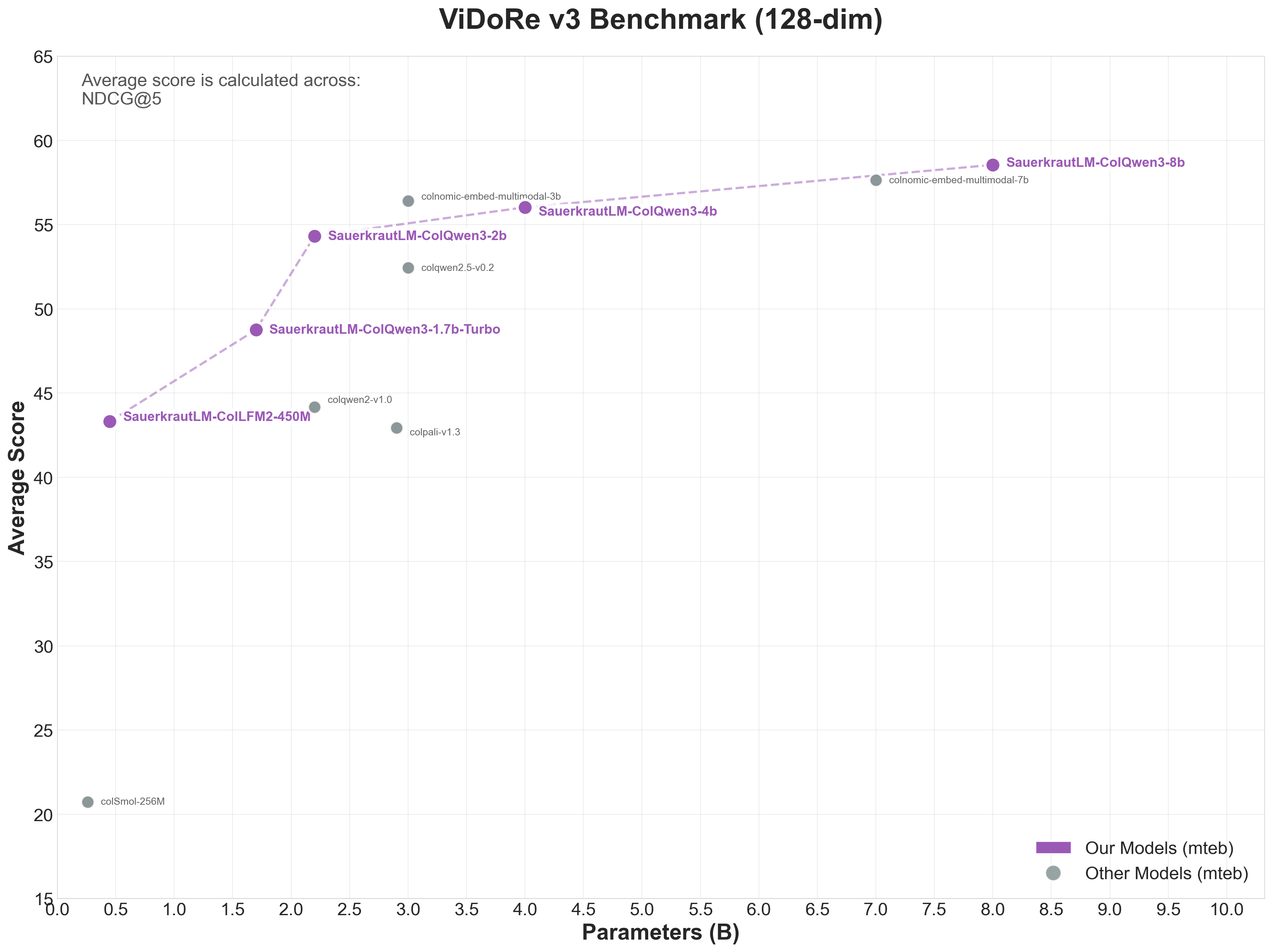
| ViDoRe v3 | 43.32 | 🥇 #1 |
Small Category Comparison (<1B, 128-dim)
| Model | Params | Dim | ViDoRe v1 | MTEB v1+v2 | ViDoRe v3 |
|---|---|---|---|---|---|
| SauerkrautLM-ColLFM2-450M-v0.1 ⭐ | 450M | 128 | 83.56 | 74.33 | 43.32 |
| colSmol-500M | 500M | 128 | 82.49 | 71.17 | - |
| colSmol-256M | 256M | 128 | 79.74 | 66.90 | 20.73 |
#1 in ALL benchmarks for small models!
Detailed Benchmark Results
Efficiency Comparison
| Metric | ColLFM2-450M | colSmol-500M | Advantage |
|---|---|---|---|
| Parameters | 450M | 500M | -10% |
| ViDoRe v1 | 83.56 | 82.49 | +1.07 |
| MTEB v1+v2 | 74.33 | 71.17 | +3.16 |
📋 Summary Tables
128-dim Models Comparison
Comparison vs High-dim Models
✨ Key Features
- 🏆 Best Small Model: #1 in ALL benchmarks for <1B models
- ⚡ Ultra Efficient: Only 450M parameters, ~0.9GB VRAM
- 🎓 Curriculum Learning: Trained with progressive difficulty
- 🔀 Hierarchical Merge: Advanced model merging for optimal performance
- 📐 Native 512x512: Optimized for document resolution
- 🌍 Multilingual: 6 languages (EN, DE, FR, ES, IT, PT)
Model Details
| Property | Value |
|---|---|
| Base Model | LiquidAI/LFM2-VL-450M |
| Parameters | 450M |
| Embedding Dimension | 128 |
| VRAM (bfloat16) | ~0.9 GB |
| Max Context Length | 32,768 tokens |
| Image Resolution | 512×512 native |
| Image Tokens | 64-256 (dynamic) |
| Vision Encoder | SigLIP2 (86M) |
| License | LFM 1.0 |
🎓 Advanced Training Methodology
1. Curriculum Learning
Unlike standard training, ColLFM2 was trained with curriculum learning:
Stage 1: Easy examples (high-quality, clear documents)
↓
Stage 2: Medium examples (mixed quality)
↓
Stage 3: Hard examples (complex layouts, noisy scans)
↓
Stage 4: Full mixture with hard negatives
2. Hierarchical Model Merging
Base LFM2-VL-450M
↓
┌───┴───┐
↓ ↓
mMARCO Retrieval
Specialist Model
↓ ↓
└───┬───┘
↓
Hierarchical Merge
↓
Final Model
- mMARCO Specialist: Sub-model trained on mMARCO for retrieval fundamentals
- Retrieval Model: Trained on document retrieval datasets
- Hierarchical Merge: Combined using learned merge weights
Hardware & Configuration
| Setting | Value |
|---|---|
| GPUs | 4x NVIDIA RTX 6000 Ada (48GB) |
| Effective Batch Size | 256 |
| Precision | bfloat16 |
| Curriculum Stages | 4 |
Datasets
| Dataset | Description |
|---|---|
| vidore/colpali_train_set | ColPali training data |
| openbmb/VisRAG-Ret-Train-In-domain-data | Visual RAG training data |
| llamaindex/vdr-multilingual-train | Multilingual retrieval (with curriculum) |
| unicamp-dl/mmarco | mMARCO for specialist model |
| VAGO Multilingual Datasets | Proprietary multilingual data |
Installation & Usage
⚠️ Important: Install our package first before loading the model:
pip install git+https://github.com/VAGOsolutions/sauerkrautlm-colpali
import torch
from PIL import Image
from sauerkrautlm_colpali.models import ColLFM2, ColLFM2Processor
model_name = "VAGOsolutions/SauerkrautLM-ColLFM2-450M-v0.1"
model = ColLFM2.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="cuda:0",
).eval()
processor = ColLFM2Processor.from_pretrained(model_name)
images = [Image.open("document.png")]
queries = ["What is the main topic?"]
batch_images = processor.process_images(images).to(model.device)
batch_queries = processor.process_queries(queries).to(model.device)
with torch.no_grad():
image_embeddings = model(**batch_images)
query_embeddings = model(**batch_queries)
scores = processor.score(query_embeddings, image_embeddings)
Use Cases
✅ Perfect for:
- Edge deployment (Raspberry Pi, Jetson)
- Mobile applications
- High-throughput batch processing
- Cost-sensitive deployments
- Real-time retrieval systems
📊 Additional Benchmark Visualizations
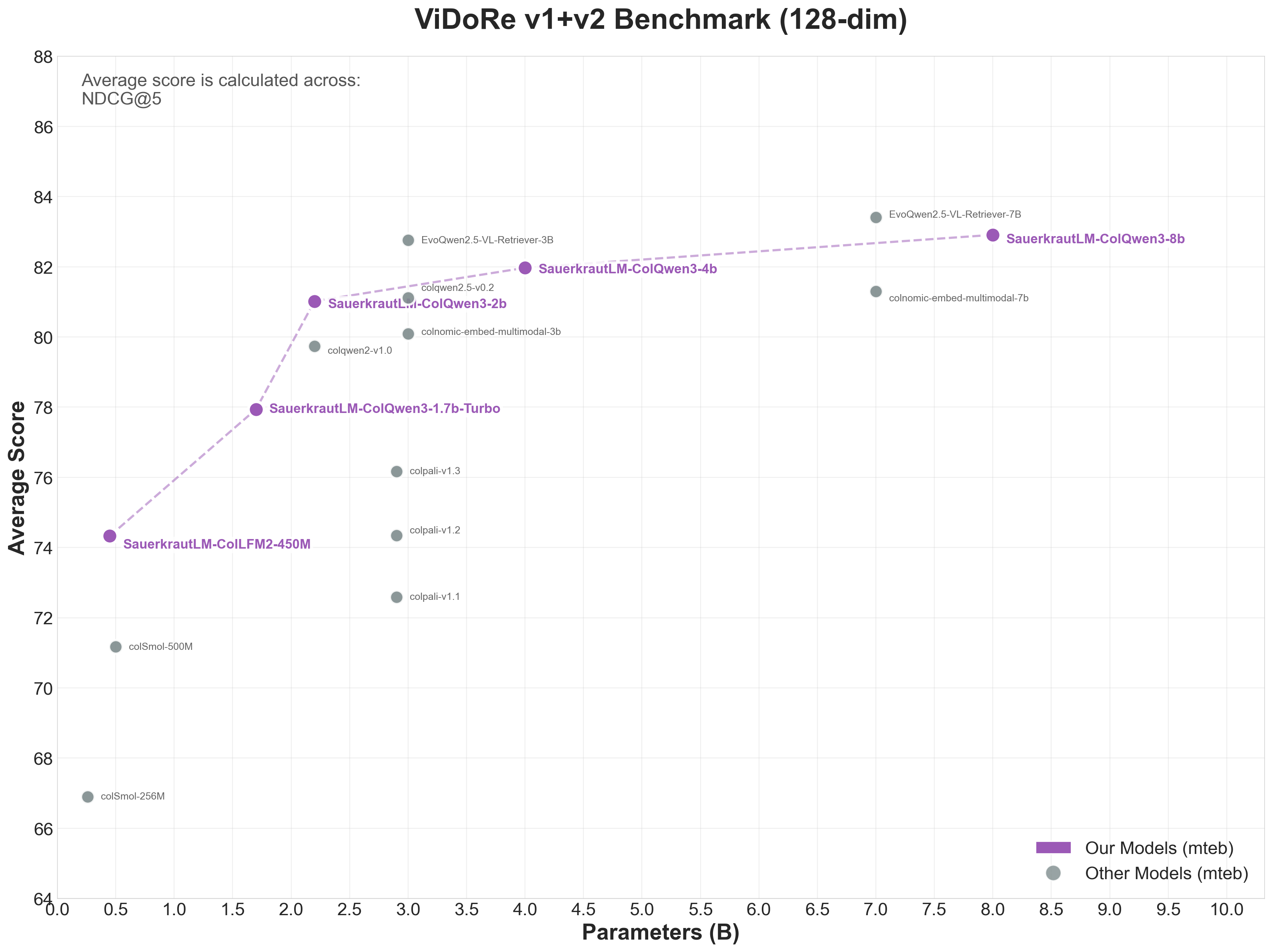
MTEB v1+v2 Benchmark (128-dim Models)
👁 MTEB v1+v2 Benchmark - 128-dim Models
ViDoRe v3 Benchmark (128-dim Models)
👁 ViDoRe v3 Benchmark - 128-dim Models
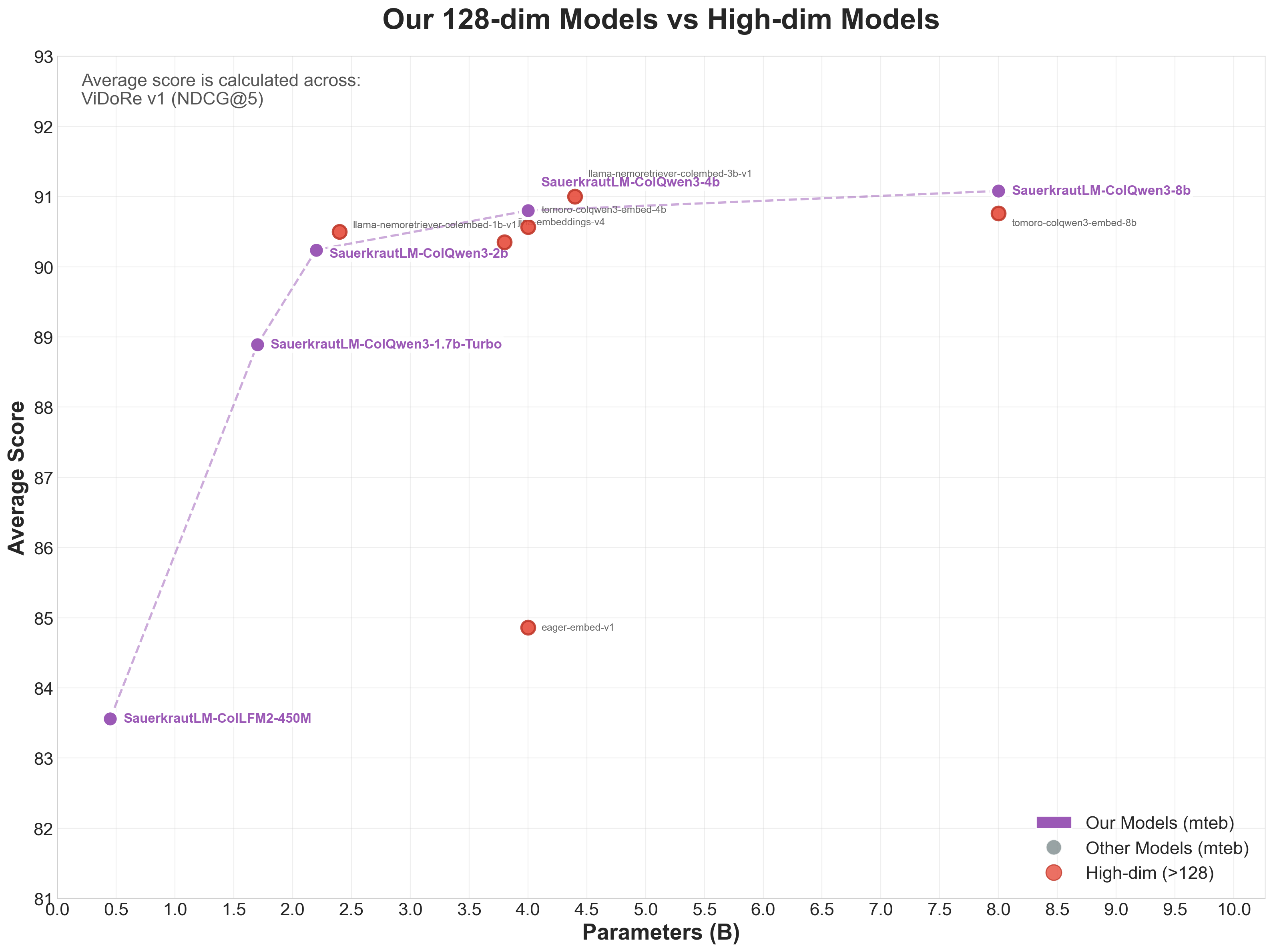
Our Models vs High-dim Models
👁 ViDoRe v1 - Our Models vs High-dim
License
This model is licensed under the LFM 1.0 License from LiquidAI. Please review the full license before commercial use.
Citation
@misc{sauerkrautlm-colpali-2025,
title={SauerkrautLM-ColPali: Multi-Vector Vision Retrieval Models},
author={David Golchinfar},
organization={VAGO Solutions},
year={2025},
url={https://github.com/VAGOsolutions/sauerkrautlm-colpali}
}
Contact
- VAGO Solutions: https://vago-solutions.ai
- GitHub: https://github.com/VAGOsolutions
- Downloads last month
- 349
Inference Providers NEW
This model isn't deployed by any Inference Provider. 🙋 Ask for provider support
Model tree for VAGOsolutions/SauerkrautLM-ColLFM2-450M-v0.1
Base model
LiquidAI/LFM2-VL-450M