
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Paper • 2606.09770 • Published
Topo-Omni
👁 arXiv
👁 Project Page
👁 GitHub
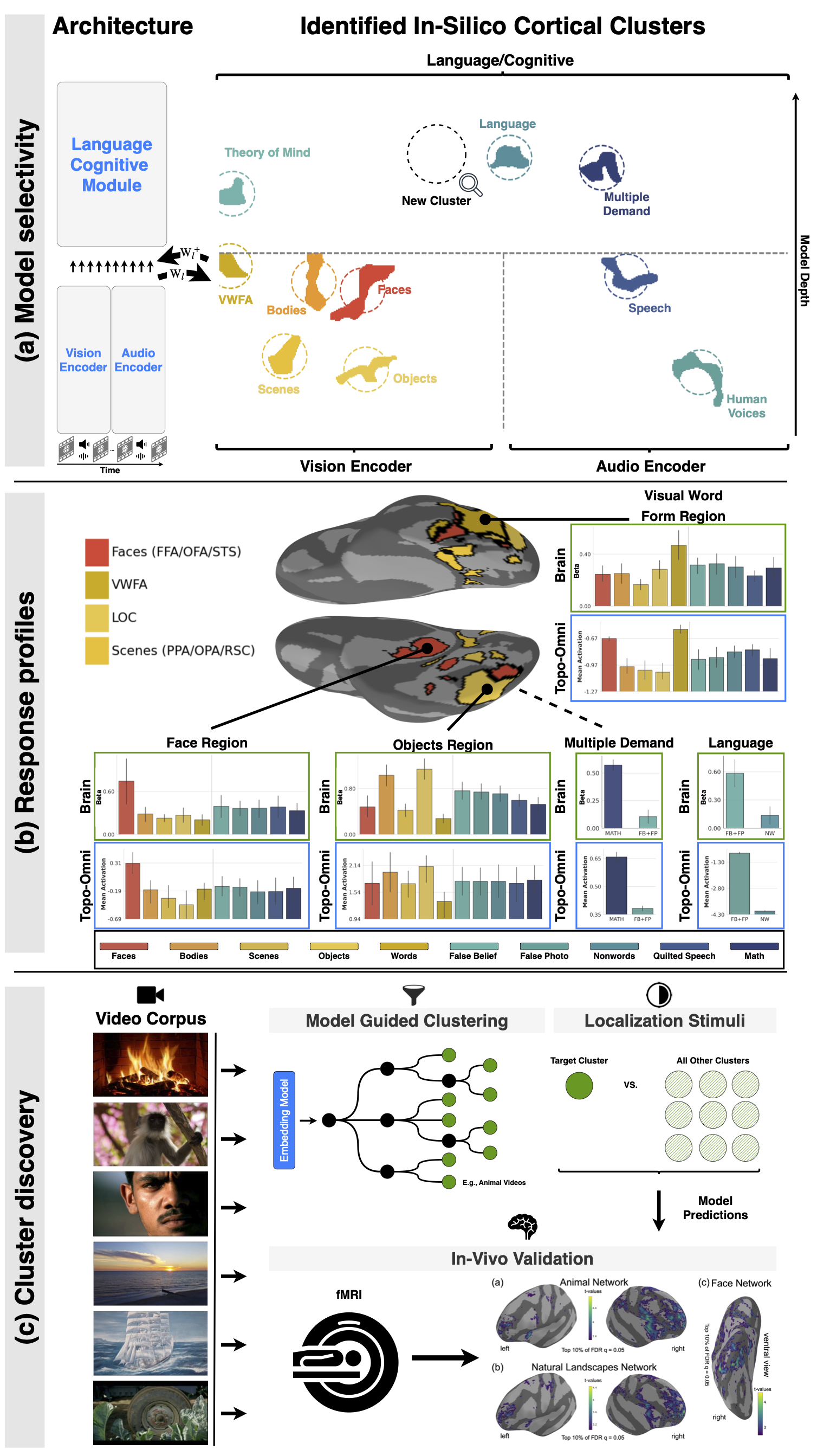
Topo-Omni is Qwen2.5-Omni-3B fine-tuned with a spatial smoothness loss that induces a brain-like topographic organization across its vision, audio, and language layers. Every unit in the network is assigned a fixed 2-D coordinate on a shared cortical sheet, and training encourages units that are close on the sheet to respond similarly — mirroring how functionally similar neurons cluster together in the cortex. The result is emergent, spatially clustered functional regions (face-, scene-, object-, and speech-selective areas) that can be localized, ablated, stimulated, and compared against human fMRI data.
Code, evaluation scripts, and further documentation: github.com/epflneuroailab/topo-omni
Model Details
Base model: Qwen/Qwen2.5-Omni-3B (Thinker module — vision encoder, audio encoder, and language model)
Architecture:
Qwen2_5OmniThinkerForConditionalGenerationwith aCorticalAdaptorprojection inserted at each layer that maps hidden activations onto a shared cortical sheet and back (via a learned, near-identity linear map and its pseudo-inverse), so the underlying computation is preserved while exposing a spatially organized representationCortical sheet: a single 304 × 512 2-D grid spanning the entire model
Rows Component 0 – 159, cols 0–255 Vision encoder layers 0 – 159, cols 256–511 Audio encoder layers 160 – 303 Thinker (language model) layers Spatial loss: computes pairwise response similarity within local neighborhoods (Chebyshev distance) on the sheet and penalizes dissimilarity between nearby units; weighted by
alpha = 20relative to the task lossModalities: text, image, video, and audio in; text out
How It Works
Standard transformer networks have no notion of spatial layout: any unit can interact with any other regardless of "position." Topo-Omni injects a topographic inductive bias, inspired by TDANN and TopoLM, by:
- Assigning every unit in the vision encoder, audio encoder, and language model a fixed coordinate on a shared 2-D cortical sheet.
- Adding a spatial smoothness loss during fine-tuning that penalizes nearby units on the sheet for responding dissimilarly to the same input.
- Letting functionally selective regions (e.g., for faces, scenes, objects, bodies, speech) emerge and spatially cluster, much like functional maps in the human brain.
The learned sheet can then be probed with the same tools used in visual/auditory neuroscience: localizer-based selectivity mapping, ablation/stimulation, cluster overlap (IoU), and alignment to human fMRI recordings (NSD, SpaceTop).
Usage
Note: This checkpoint requires the custom
Qwen2_5OmniThinkerForConditionalGenerationimplementation (with theCorticalAdaptormodules) from the topo-omni repository — loading it with the stocktransformersclass will not reconstruct the cortical sheet projections correctly.
git clone https://github.com/epflneuroailab/topo-omni.git
cd topo-omni
pip install -r requirements.txt
from transformers import Qwen2_5OmniThinkerConfig, Qwen2_5OmniProcessor
from src.models.qwen2_5_omni import Qwen2_5OmniThinkerForConditionalGeneration
repo_id = "epfl-neuroai/topo-omni"
config = Qwen2_5OmniThinkerConfig.from_pretrained(repo_id)
config.audio_config.is_training = False
config.vision_config.is_training = False
config.text_config.is_training = False
model = Qwen2_5OmniThinkerForConditionalGeneration.from_pretrained(
repo_id, dtype="auto", device_map="auto", config=config,
).eval()
processor = Qwen2_5OmniProcessor.from_pretrained(repo_id)
conversation = [
{"role": "user", "content": [
{"type": "image", "image": "path/or/url/to/image.jpg"},
]},
]
text = processor.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = processor(text=text, images=[...], return_tensors="pt").to(model.device)
output_ids = model.generate(**inputs, max_new_tokens=128)
print(processor.batch_decode(output_ids, skip_special_tokens=True)[0])
To inspect or intervene on the cortical sheet representations directly (selectivity mapping, ablation, stimulation), see the evaluation scripts under src/eval/ in the repository.
Training
Fine-tuned from Qwen/Qwen2.5-Omni-3B with TRL's SFTTrainer plus an additional spatial smoothness loss term.
| Hyperparameter | Value |
|---|---|
| Epochs | 5 |
| Per-device batch size | 4 |
| Gradient accumulation | 4 |
| Learning rate | 5e-5 (cosine schedule, 3% warmup) |
| Weight decay | 0.01 |
Spatial loss weight (alpha) |
20 |
| Spatial loss accumulation | mean |
| Cortical projection init | near-identity (scale 1e-3) |
Framework versions
- TRL: 0.25.1
- Transformers: 4.57.3
- PyTorch: 2.9.1
- Datasets: 4.4.1
- Tokenizers: 0.22.1
Evaluation
The cortical sheet learned by this model is evaluated for:
- Selectivity — ON-vs-OFF contrasts (faces, bodies, objects, scenes, speech, etc.) with FDR-corrected t-tests
- Spatial clustering — Island Moran's I spatial autocorrelation of selectivity maps
- Brain alignment — correlation of model topography with human fMRI t-maps (NSD, SpaceTop)
- Causal relevance — ablation and stimulation of localizer-defined regions
- Cluster overlap — IoU of thresholded activation masks across stimulus categories, against a random-sampling null
See src/eval/ and the project README for scripts and metric definitions.
Citation
If you use this model, please cite the Topo-Omni repository and the works it builds on:
TODO
This model is built on Qwen2.5-Omni and the topographic-DNN approaches introduced by TDANN and TopoLM.
License
Released under the same license as the base model, Qwen2.5-Omni-3B (Apache 2.0). Please review the base model's license terms before use.
- Downloads last month
- 50
Safetensors
Model size
5B params
Tensor type
BF16
·
Model tree for epfl-neuroai/topo-omni
Base model
Qwen/Qwen2.5-Omni-3B