
{kind=link}
{kind=link}
Paper • 2310.08491 • Published • 57
YAML Metadata Warning:The pipeline tag "text2text-generation" is not in the official list: text-classification, token-classification, table-question-answering, question-answering, zero-shot-classification, translation, summarization, feature-extraction, text-generation, fill-mask, sentence-similarity, text-to-speech, text-to-audio, automatic-speech-recognition, audio-to-audio, audio-classification, audio-text-to-text, voice-activity-detection, depth-estimation, image-classification, object-detection, image-segmentation, text-to-image, image-to-text, image-to-image, image-to-video, unconditional-image-generation, video-classification, reinforcement-learning, robotics, tabular-classification, tabular-regression, tabular-to-text, table-to-text, multiple-choice, text-ranking, text-retrieval, time-series-forecasting, text-to-video, image-text-to-text, image-text-to-image, image-text-to-video, visual-question-answering, document-question-answering, zero-shot-image-classification, graph-ml, mask-generation, zero-shot-object-detection, text-to-3d, image-to-3d, image-feature-extraction, video-text-to-text, keypoint-detection, visual-document-retrieval, any-to-any, video-to-video, other
Links for Reference
- Homepage:https://github.com/kaistAI/Prometheus
- Repository:https://github.com/kaistAI/Prometheus
- Paper:https://arxiv.org/abs/2310.08491
- Point of Contact:seungone@kaist.ac.kr
TL;DR
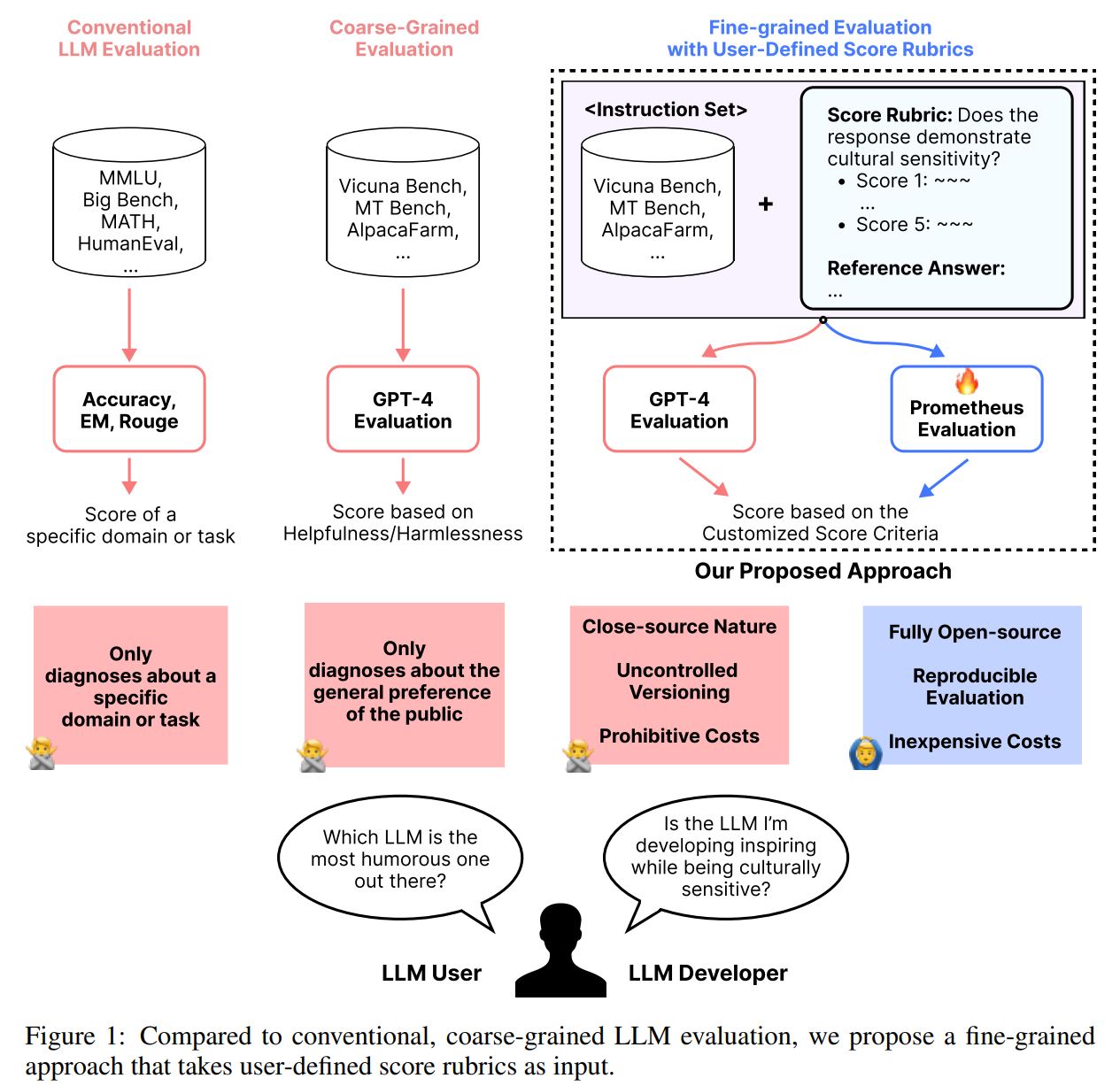
Prometheus is an alternative of GPT-4 evaluation when doing fine-grained evaluation of an underlying LLM & a Reward model for Reinforcement Learning from Human Feedback (RLHF).
👁 plot
Prometheus is a language model using Llama-2-Chat as a base model and fine-tuned on 100K feedback within the Feedback Collection. Since it was fine-tuned on a large amount of feedback, it is specialized at evaluating long-form responses, outperforming GPT-3.5-Turbo, Llama-2-Chat 70B, and on par with GPT-4 on various benchmarks. Most importantly, this was possible since we appended 2 reference materials (reference answer, and customized score rubric). Prometheus is a cheap and powerful alternative to GPT-4 evaluation, which one could use to evaluate LLMs with customized criteria (e.g., Child readability, Cultural Sensitivity, Creativity). Also, it could be used as a reward model for Reinforcement Learning from Human Feedback (RLHF).
Model Details
Model Description
- Model type: Language model
- Language(s) (NLP): English
- License: Apache 2.0
- Related Models: All Prometheus Checkpoints
- Resources for more information:
Prometheus is trained with two different sizes (7B and 13B). You could check the 13B sized LM on this page. Also, check out our dataset as well on this page.
Prompt Format
Prometheus requires 4 components in the input: An instruction, a response to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below. You should fill in the instruction, response, reference answer, criteria description, and score description for score in range of 1 to 5.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference_answer}
###Score Rubrics:
[{criteria_description}]
Score 1: {score1_description}
Score 2: {score2_description}
Score 3: {score3_description}
Score 4: {score4_description}
Score 5: {score5_description}
###Feedback:
After this, you should apply the conversation template of Llama-2-Chat (not applying it might lead to unexpected behaviors). You can find the conversation class at this link.
conv = get_conv_template("llama-2")
conv.set_system_message("You are a fair evaluator language model.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
As a result, a feedback and score decision will be generated, divided by a separating phrase [RESULT]
License
Feedback Collection and Prometheus is subject to OpenAI's Terms of Use for the generated data. If you suspect any violations, please reach out to us.
Usage
Find below some example scripts on how to use the model in transformers:
Using the Pytorch model
Running the model on a CPU
Running the model on a GPU
Running the model on a GPU using different precisions
FP16
INT8
Citation
If you find the following model helpful, please consider citing our paper!
BibTeX:
@misc{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Seungone Kim and Jamin Shin and Yejin Cho and Joel Jang and Shayne Longpre and Hwaran Lee and Sangdoo Yun and Seongjin Shin and Sungdong Kim and James Thorne and Minjoon Seo},
year={2023},
eprint={2310.08491},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 810