
Anime Whisper 🤗🎤📝
Anime Whisper は、特に日本語のアニメ調演技セリフのドメインに特化した日本語音声認識モデルです。 このモデルは kotoba-whisper-v2.0 をベースモデルとして、約5,300時間373万ファイルのアニメ調の音声・台本データセット Galgame_Speech_ASR_16kHz でファインチューニングしたものです。 特にアニメ演技音声ドメインに特化していますが、それ以外の音声でも、他のモデルにはない特徴や高い性能を持っています。
気軽にお試しできるデモはこちらから: https://huggingface.co/spaces/litagin/anime-whisper-demo
注意❗
このモデルは初期プロンプト(initial prompt) との相性が悪いようで、設定をするとハルシネーションが起きて質が極めて劣化します。初期プロンプトを設定せずにご使用ください。
Using an initial prompt causes a decline in quality, with the model exhibiting hallucinations and significantly degraded performance. Please avoid using an initial prompt.
特徴 🌟
Anime Whisperは、他モデルに比べて一般的に次のような傾向があります。
- ハルシネーションが少ない
- 他のモデルでスキップされがちな言い淀みや、笑い声や叫びや吐息などの非言語発話も忠実に書き起こす
- 「。、!?…」の句読点が音声のリズムや感情に合わせて適切に付き、セリフ台本として違和感がない自然な文体で書き起こされる
- アニメ調な演技セリフに対しては特に精度が高い
- kotoba-whisper (whisper-large-v3の蒸留モデル) ベースなので軽量で高速
- 他モデルでは書き起こしがほぼ不可能なNSFW音声もきちんとした文体で文字起こし可能
使い方例 🚀
import torch
from transformers import pipeline
generate_kwargs = {
"language": "Japanese",
"no_repeat_ngram_size": 0,
"repetition_penalty": 1.0,
}
pipe = pipeline(
"automatic-speech-recognition",
model="litagin/anime-whisper",
device="cuda",
torch_dtype=torch.float16,
chunk_length_s=30.0,
batch_size=64,
)
audio_path = "test.wav"
result = pipe(audio_path, generate_kwargs=generate_kwargs)
print(result["text"])
- 複数ファイルを一気に推論する場合は
pipeに単にファイルパスのリストを渡せばよいです。 - 繰り返しハルシネーションが目立つ場合は、上記の
no_repeat_ngram_size: intを 5 - 10 程度に設定したり、repetition_penaltyを1より上に設定することで抑制できます。
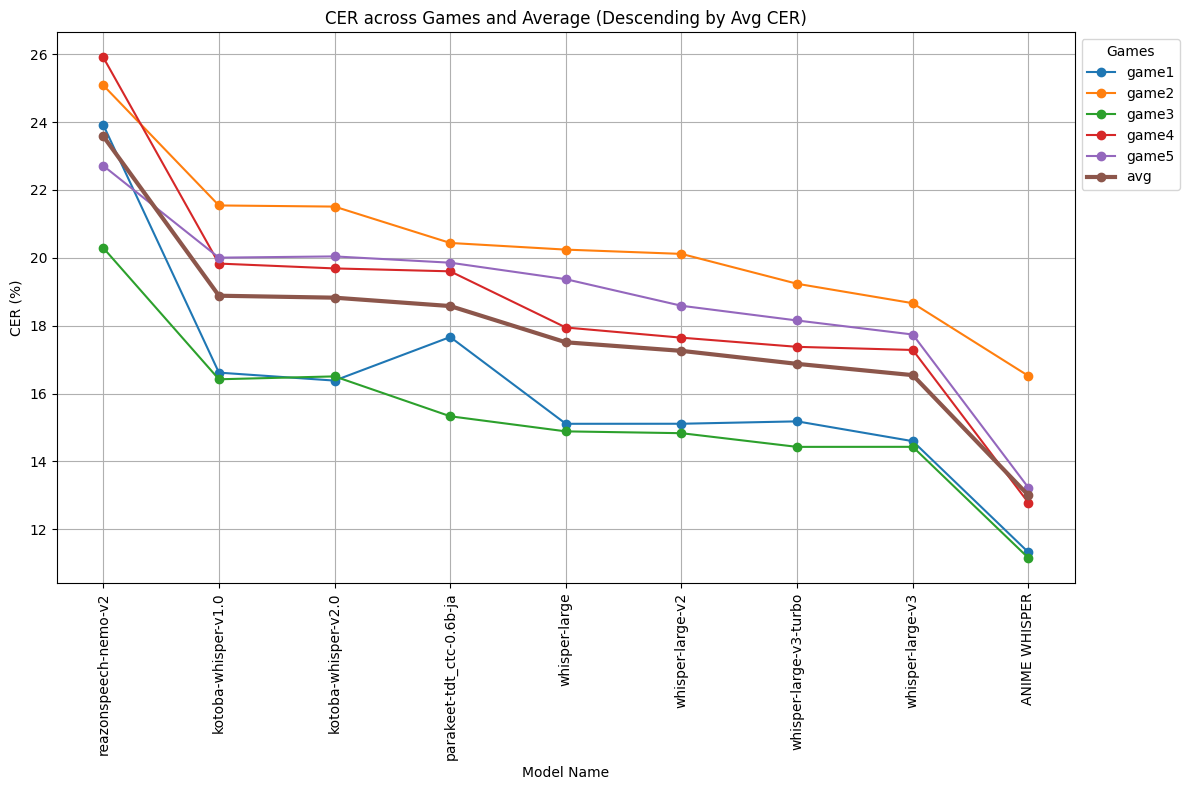
評価 📊
詳しい評価・観察レポートや評価コードはGitHubリポジトリで公開予定です。
CER (Character Error Rate, 文字誤り率)
- 「学習データと同じアニメ調セリフのドメインではあるが、学習データには含まれていない個人的に所持している5本ノベルゲーム(合計約75kファイル)」で評価
- OpenAIのWhisper系の繰り返しハルシネーション抑止のため
no_repeat_ngram_size=5のパラメータで生成 - CERは適切な正規化を行った結果に対するCER
{kind=link}
{kind=link}
バイアス等 🚨
- 人名等の固有名詞が学習データのビジュアルノベルに存在する場合、そのゲーム内の漢字で書き起こされることが多い
- 他にもデータセットに存在する一部特定の単語が通常とは異なる書き起こしになることがある(例:
からだ→身体等や、その他固有名詞等) - データセットの正規化 により、以下のものは出力結果にほぼ現れない:
- 母音や長音符の連続:
ああああーーーー - 同じ感嘆符の連続:
こらーっ!!!!なにそれ!?!?!?!? - 三点リーダーの連続:
……(日本語表記としては2個用いる……が正しいが、ほぼ常に1個のみ…で出力される)
- 母音や長音符の連続:
- 数字とアルファベットと感嘆符は半角で書き起こされる
- 文末の「。」はほぼ常に省略される
- 一部卑語の書き起こしに伏せ字「○」が含まれることがある
例 👀
上記評価と同じ、学習元には入っていないノベルゲームのセリフの書き起こし比較です(同様にno_repeat_ngram_size=5での生成)。
結果を見ると、だいたいwhisper-large-v3程度の良い性能が出ており、以下では他モデルとの差が顕著な例(特に非言語発話や感情的な音声等)のみいくつか抜粋しています。
| 正解テキスト | Anime Whisper | whisper-large-v3 | kotoba-whisper-v2.0 | reazonspeech-nemo |
|---|---|---|---|---|
| あわわわっ!わわわわっ! | はわわっ、わわわわっ…! | ああああああああああ | うわうわ | うわ! |
| そっ、そっか……。………。……そうなんだ。 | そっ…そっか…そうなんだ… | そっか…そうなんだ… | そっか…そうなんだ | そっそっかあっそうなんだ。 |
| たぶん、ぼくが勝つ、はず | たぶん、ボクが勝つ、はず | 多分、僕が勝つはず。 | 多分僕が勝つはず | 僕が勝つはず。 |
| げ、げほっ……なんだこいつ! | げほっ、げほっ…なんだ、こいつ… | なんだ、こいつ… | なんだこいつ | フッ何だこいつ。 |
| はっ、はい。そうです。……その、えっと。へっ、変だったでしょうか? | は、はい、そうです…その、えと…へ、変だったでしょうか…? | あ、はい、そうです。そ、えっと、へ、変だったでしょうか。 | はいそうですそういと変だったでしょうか | あっはいそうですうすえっとへ変だったでしょうか? |
| ぶぶぶぶ豚クソがァァァ!待てコルァァァ! | ぶぶぶぶぶ、ぶたくそがー!待てごらぁぁ! | 待てこらー | 待てこそか | 待てこら! |
| 地面が揺れるとかありえ……ぎゃっ! | 地面が揺れるとかありえ…ひゃっ!? | 地面が揺れるとかありえ? | 地面が揺れるとかありえ | やっ! |
| きゃっほう!い、いたっ、いただきまーす! | きゃっほう!い、いた、いただきまーす! | キャッホー!い、いただきます! | キャホー!いただきます! | いいたいただきます! |
| ……っ、はぁ……わ、わたし、今日は…… | んっ、はぁ…わ、私、今日は… | 私、今日は… | 私今日は | えっと私今日。 |
| ……ぷふっ、ンッ。かっ、かっ、かっ……ぷふっ。かっ。んふふっ。かっ、価値観 | うふふっ…か、かはっ…ぷっ…はぁっ…か、価値観っ… | 価値観! | 価値観 | ハッかちかん! |
| か、痒くもねぇ……こんなんんん……! | か、痒くもねえ…こんな、んんっ…! | か、回復もねぇ、こんな、うぬぅ | かかゆくもねえこんな | かゆくもねえこんなうう。 |
| ひゃっ!や、やだ、くすぐった……や、やっ、あは、あははっ | ひゃうっ!やっ、やだっ…くすぐったっ…やっ、やっ、はんっ、あははっ! | やだ!すぐだ! | やだ | やっほ! |
| ふえぇ、急に止まらないでよう…… | ふえぇ、急に止まらないでよぉ | おへぇ、急に止まらないでよ | おへえ急に止まらないでよ | 急に止まらないでよ。 |
| ごごご50キロもないです私ー! | ごごご50キロもないです私ー! | 50キロもないです私! | 550キロもないです私 | 50キロもないですわたし! |
| いいい、すびばぜん、すびばぜーんっ | いいずびばぜんずびばぜーん! | いいいい! ズビバル10! ズビブル10! | いいズビバーテン! | すみませんすみません。 |
| 間抜けか貴様ァァァ! | 間抜けか貴様ぁぁっ! | マヌケカキ様! | まぬけかきさま | 抜けか貴様! |
| ぷ、くく……ひっ、ひいっ…… | くっ…くくくっ…ぷっ…くくっ… | ご視聴ありがとうございました | フッ | フフフフ。フフフフフ。 |
| キミは……。あっ、はっ……。最初から……あんっ、あっ、容赦がないな | 君はぁ…はぁっ、はぁっ…最初から…あんっ、あっ、容赦がないなぁ… | 君は……最初から容赦がないな | 君は最初からあんあ容赦がないな | 君は最初からうっうん容赦がないなあ。 |
| 望んでるわけ……。のっ、のっ、のっ……望んでるんです。世界が終わればいいって……強く、強くっ。はぁっ、はぁっ | 望んでるわけ…の、の、の…望んでるんです…世界が終わればいいって、強く、強く…はぁっ | 望んでるわけ…望んでるんです…世界が終わればいいって…強く…強く… | 望んでるわけ…ののぞんでるんです世界が終わればいいって強く強く | ん?望んでるんです。世界が終わればいいって強く強く。 |
NSFW例 🫣
成人向けの表現が含まれるため、閲覧にはご注意ください。
学習手順 📚
詳しい学習手順やハイパーパラメータや学習コードはそのうちGitHubで公開予定です。
- 全データのうち1番最後のtarファイルをtestデータとして残し、それ以外の3,735,363ファイルで学習
- まずはベースモデルからEncoderを凍結してDecoderのみで数エポックを学習
- その後Encoderの凍結を解除し、全体で数エポックを学習
- 学習打ち切り後に、「ある時点から別の時点までのモデルの平均(マージ)」を取る操作で性能向上を試み、Optunaを使ってベンチマークデータに対するCERで最適化し、その結果を最終モデルとした
環境 🖥
- 自腹でvast.aiで H100 NVL (VRAM 96GB) を借りて合計3週間弱、試行錯誤しながら学習をした(当初はベースモデルをwhisper-large-v3-turboにしていたので、その分も含まれる)
- 実際にこのモデルに使われた学習時間は、H100 NVL * 11.2日 程度(ただし後半の方はおそらく過学習によりテストデータに対する性能が悪かったため、最終マージには用いなかった)
- Downloads last month
- 31,938