
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Paper • 2401.06591 • Published • 4
Links for Reference
- Homepage: https://kaistai.github.io/prometheus-vision/
- Repository: https://github.com/kaistAI/prometheus-vision
- Paper: https://arxiv.org/abs/2401.06591
- Point of Contact: seongyun@kaist.ac.kr
TL;DR
Prometheus-Vision is the first open-source VLM specialized for evaluation purposes. Prometheus-Vision shows a high correlation with both GPT-4V and human evaluators, indicating its potential to be used as a cheap alternative for GPT-4V evaluation.
👁 image/png
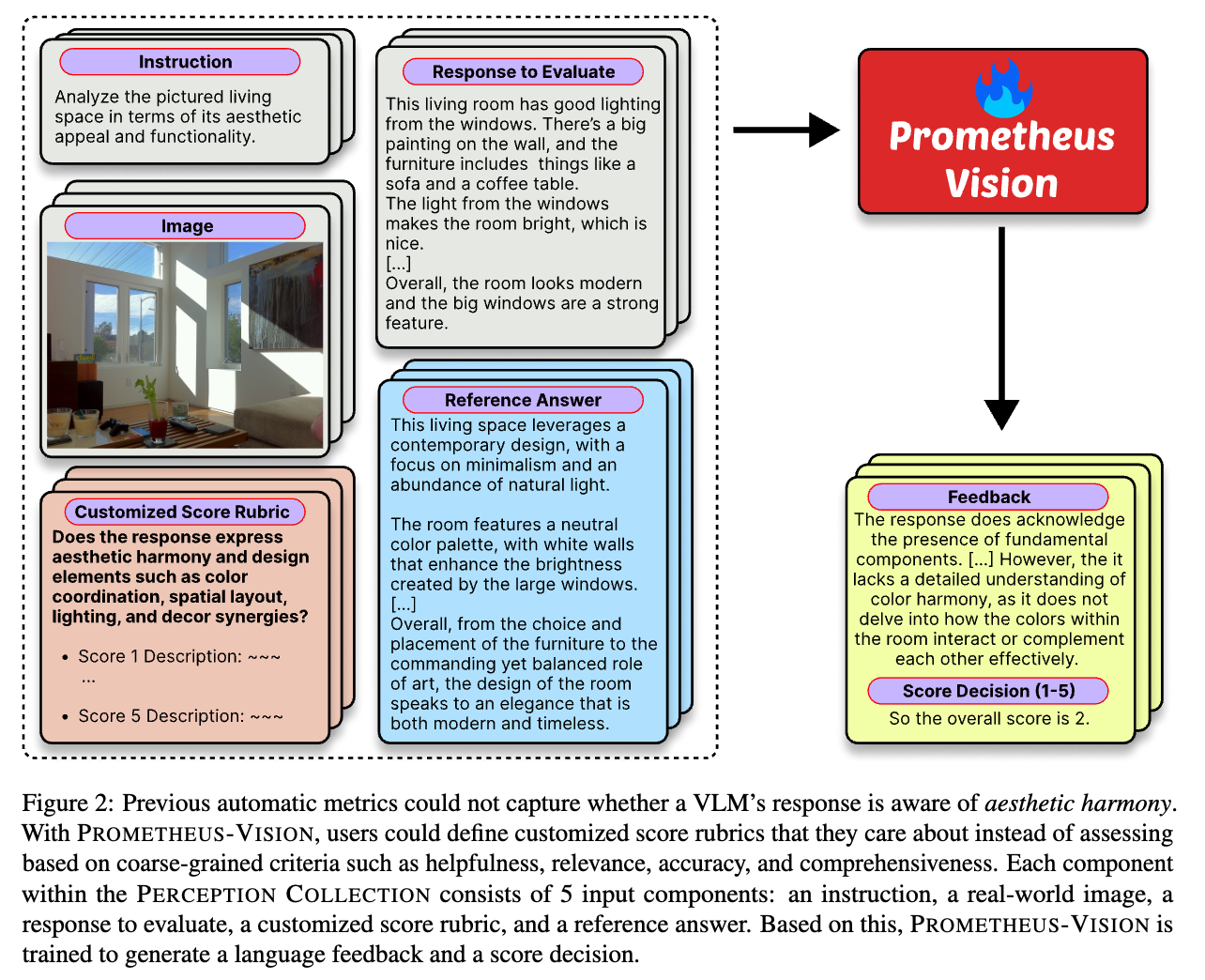
Prometheus-Vision have five input components (image, instruction, response to evaluate, customized score rubric, reference answer) and two output components (language feedback and score decision).
👁 image/png
Model Details
Model Description
- Model type: Vision-Language Model
- Language(s) (NLP): English
- License: Apache 2.0
- Related Models: All Prometheus Checkpoints
- Resources for more information:
Prometheu-Vision is trained with two different sizes (7B and 13B). You could check the 7B sized VLM on this page. Also, check out our dataset as well on this page.
Prompt Format
Prometheus-Vision requires 5 components in the input: An image, an instruction, a response to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below. You should fill in the instruction, response, reference answer, criteria description, and score description for score in range of 1 to 5.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, an image and a score rubric representing an evaluation criterion is given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference_answer}
###Score Rubrics:
[{criteria_description}]
Score 1: {score1_description}
Score 2: {score2_description}
Score 3: {score3_description}
Score 4: {score4_description}
Score 5: {score5_description}
###Feedback:
License
Perception Collection and Prometheus-Vision are subject to OpenAI's Terms of Use for the generated data. If you suspect any violations, please reach out to us.
Usage
Find below some example scripts on how to use the model in transformers:
Using the Pytorch model
Running the model on a GPU
Citation
If you find the following model helpful, please consider citing our paper!
BibTeX:
@misc{lee2024prometheusvision,
title={Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation},
author={Seongyun Lee and Seungone Kim and Sue Hyun Park and Geewook Kim and Minjoon Seo},
year={2024},
eprint={2401.06591},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 25