
{kind=link}
こんにちは、クロガネです。
この記事はLLM・LLM活用 Advent Calendar 2024の参加記事です。
本当はVLM関連を書こうとしていましたが頓挫したのでEQ-benchを回してみます。
EQ-bench, Creative Writingの概要
今回扱うEQ-benchはLLM as a judgeの一種です。
創作などに必要な「話者の感情状態の強度」と「執筆能力の評価」のためのベンチマークです。
ベンチマーク一覧は以下のページに公開されています。
EQ-Bench Leaderboard
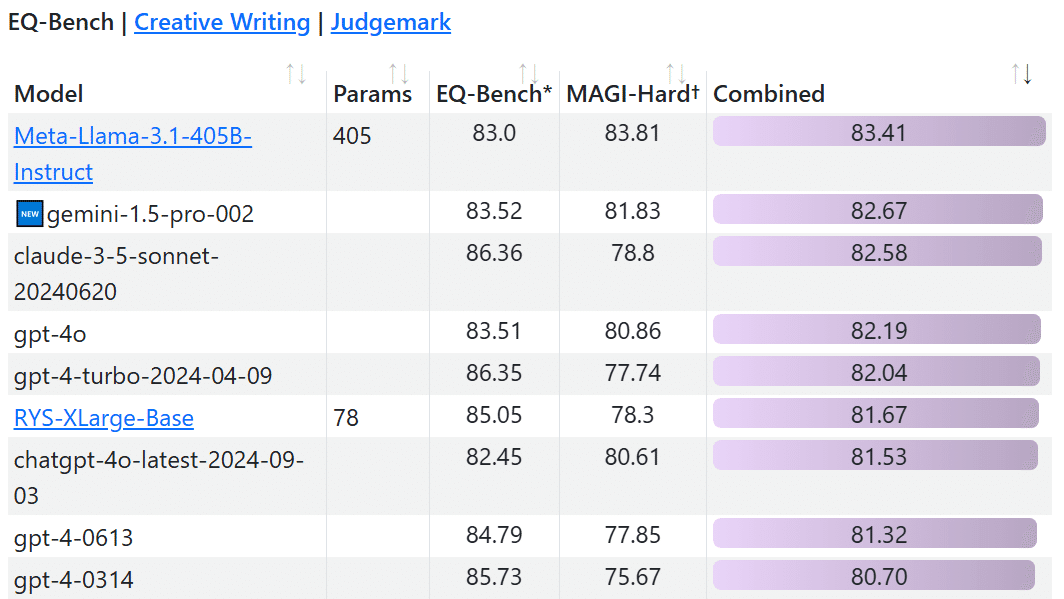{kind=link}
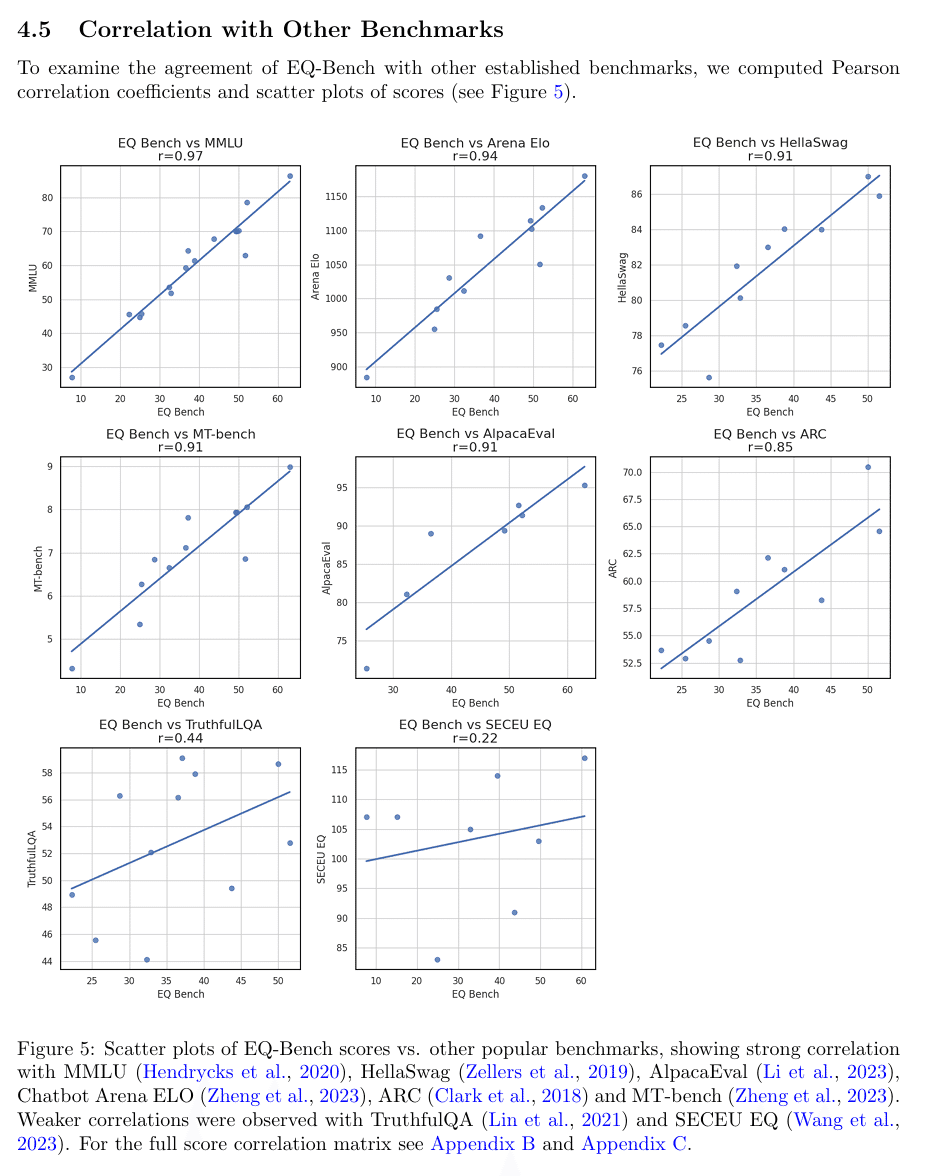
EQ-Benchはいろんなベンチマークとも相関があるらしいです。
{kind=link}
ただし、人手評価との相関の記述はありませんでした。
EQ-benchについて
EQ-benchはLLMの感情知能を評価するためのベンチマークです。
以下のように対話内のキャラクターの感情状態の強度を予測させます。
Your task is to predict the likely emotional responses of a character in this dialogue:
Cecilia: You know, your words have power, Brandon. More than you might think.
Brandon: I’m well aware, Cecilia. It’s a critic’s job to wield them.
Cecilia: But do you understand the weight of them? The lives they can shatter?
Brandon: Art is not for the faint-hearted. If you can’t handle the critique, you’re in the wrong industry.
Cecilia: It’s not about handling criticism, Brandon. It’s about understanding the soul of the art. You dissect it like a cold, lifeless body on an autopsy table.
[End dialogue]
At the end of this dialogue, Brandon would feel…
Offended
Empathetic
Confident
Dismissive
Give each of these possible emotions a score from 0-10 for the relative intensity that they are likely to be feeling each. Then critique your answer by thinking it through step by step. Finally, give your revised scores.
You must output in the following format, including headings (of course, you should give your own scores), with no additional commentary:
First pass scores:
Offended: <score>
Empathetic: <score>
Confident: <score>
Dismissive: <score>
Critique:
<your critique here>
Revised scores:
Offended: <revised score>
Empathetic: <revised score>
Confident: <revised score>
Dismissive: <revised score>
[End of answer]
Remember: zero is a valid score, meaning they are likely not feeling that emotion. You must score at least one emotion >0.採点基準が無いのでMT-Bench的な感じですね。
そのせいか、複数回の実行オプションがあります。
今回は3回の設定ですが、本当は10回くらい、ちゃんとするなら20回くらいは実行しておいた方がいいかもしれません。
Creative Writingについて
Creative WritingはEQ-benchとは別途作成されたベンチマークです。
執筆能力の評価のために設計されたベンチだそうです。
promptはcreative_writing_utils_v2.pyで再構築されているのでわかりづらいですが、以下のような感じです。
Your task is to predict the likely emotional responses of a character in this dialogue:
Robert: Claudia, you've always been the idealist. But let's be practical for once, shall we?
Claudia: Practicality, according to you, means bulldozing everything in sight.
Robert: It's called progress, Claudia. It's how the world works.
Claudia: Not my world, Robert.
Robert: Your world? You mean this...this sanctuary of yours?
Claudia: It's more than a sanctuary. It's a testament to our parents' love for nature.
[End dialogue]
At the end of this dialogue, Robert would feel...
Remorseful
Indifferent
Affectionate
Annoyed
Give each of these possible emotions a score from 0-10 for the relative intensity that they are likely to be feeling each. Then critique your answer by thinking it through step by step. Finally, give your revised scores.
You must output in the following format, including headings (of course, you should give your own scores), with no additional commentary:
First pass scores:
Remorseful: <score>
Indifferent: <score>
Affectionate: <score>
Annoyed: <score>
Critique: <your critique here>
Revised scores:
Remorseful: <revised score>
Indifferent: <revised score>
Affectionate: <revised score>
Annoyed: <revised score>
[End of answer]
Remember: zero is a valid score, meaning they are likely not feeling that emotion. You must score at least one emotion > 0.
回答もデータセットに入っています。
"1": {
"prompt": "上の内容",
"reference_answer": {
"emotion1": "Remorseful",
"emotion2": "Indifferent",
"emotion3": "Affectionate",
"emotion4": "Annoyed",
"emotion1_score": 2,
"emotion2_score": 3,
"emotion3_score": 0,
"emotion4_score": 5
},
"reference_answer_fullscale": {
"emotion1": "Remorseful",
"emotion2": "Indifferent",
"emotion3": "Affectionate",
"emotion4": "Annoyed",
"emotion1_score": 0,
"emotion2_score": "6",
"emotion3_score": 0,
"emotion4_score": "7"
}
},EQ-Benchを回してみよう
それではベンチを回してみましょう。
今回はこのリポジトリをColabノートブックにしてきました。
EQ-Bench-jp/ER-Bench.ipynb at japanized · kuroganegames/EQ-Bench-jp
Colabで動きますが、フリープランだとCreative Writingを実行するだけで2時間くらいかかりました。
インスタンスが切れる前に結果が書いてあるファイルは保存しましょう。また、Claude 3.5 Sonnetで評価すると一回あたり大体$1-2くらいかかりました。
EQ-benchのセットアップ
EQ-Benchのリポジトリ内のコードは実行のためのセットアップが必要です。
config.cfgファイルを編集
モデル設定やベンチマーク自体の設定はここに書きます。
[Creative Writing Benchmark]と[Benchmarks to run]の追記が必要です。
また、LLMのエンジンとして基本はoobaboogaを使用しているので、transformersを指定してあげます。
[OpenAI]
api_key =
[Huggingface]
access_token =
cache_dir =
[Results upload]
google_spreadsheet_url =
[Creative Writing Benchmark]
judge_model_api = anthropic
judge_model = claude-3-5-sonnet-20241022
judge_model_api_key = your_api_key
[Options]
trust_remote_code = true
[Oobabooga config]
ooba_launch_script =
ooba_params_global =
automatically_launch_ooba = false
ooba_request_timeout = 600
[Benchmarks to run]
myrun1,llama3,unsloth/Meta-Llama-3.1-8B-Instruct,,None,3,transformers,,対応するchat templateファイルがinstruction-templatesフォルダ内に無ければ別途作成・保存が必要です。
後述のノートブック内ではllama3用のchat template(下記内容のllama3.yaml)を保存するコードを追加しています。
user: "user"
bot: "assistant"
turn_template: "<|start_header_id|><|user|><|end_header_id|>\n\n<|user-message|><|eot_id|><|start_header_id|><|bot|><|end_header_id|>\n\n<|bot-message|><|eot_id|>"
context: "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 26 Jul 2024\n\n<|system-message|><|eot_id|>"
ノートブック内でも書いてあるので重複しますが、以下のように作ります。
user: {name_template_user} # テンプレート上のuser名
bot: {name_template_assistant} # テンプレート上のLLM側の名前
turn_template: # userとassistantだけの文のchat template
context: # system templateのみ
llama3のchat_tempalteは以下の通りです。
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|system-message|><|eot_id|><|start_header_id|>user<|end_header_id|>
<|user-message|><|eot_id|><|start_header_id|>assistant<|end_header_id|>
<|bot-message|><|eot_id|>このうち、以下の5か所を修正します。
<|system-message|>: システムプロンプト部分
<|user|>: 通常はuserと記載
<|user-message|>: userのprompt
<|bot|>: 通常はassistantと記載
<|bot-message|>: llama3の返答部分
※ Cutting Knowledge Date: December 2023 Today Date: 26 Jul 2024はllama3.1のchat templateに埋め込まれているのでこのままにしました。
EQ-benchの実行
上記設定が終わったらコマンドを実行するだけです。
python eq-bench.py --benchmarks eq-benchEQ-benchの結果
EQ-benchの実行結果は以下です
--------------
Running benchmark 1 of 1
unsloth/Meta-Llama-3.1-8B-Instruct
--------------
Iteration 1 of 3
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:03<00:00, 1.06it/s]
100%|█████████████████████████████████████████| 171/171 [02:50<00:00, 1.00it/s]
Iteration 2 of 3
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:03<00:00, 1.05it/s]
100%|█████████████████████████████████████████| 171/171 [02:51<00:00, 1.00s/it]
Iteration 3 of 3
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:03<00:00, 1.07it/s]
100%|█████████████████████████████████████████| 171/171 [02:51<00:00, 1.00s/it]
----eq-bench Benchmark Complete----
2024-12-20 02:45:43
Time taken: 9.1 mins
Prompt Format: llama3
Model: unsloth/Meta-Llama-3.1-8B-Instruct
v2
Score (v2): 66.22
Parseable: 171.0
---------------
Batch completed
Time taken: 9.1 mins
---------------サイト上のllama3の66.36とほぼ同じ数値でした。
{kind=link}
Creative Writingベンチを回してみよう
EQ-bench用の設定ができていたらこちらもコマンドを実行するだけです。
python eq-bench.py --benchmarks creative-writing結果は以下の通りでした。
100%|███████████████████████████████████████████| 24/24 [29:45<00:00, 74.41s/it]
Iteration 2 of 3
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:04<00:00, 1.01s/it]
100%|███████████████████████████████████████████| 24/24 [29:56<00:00, 74.84s/it]
Iteration 3 of 3
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:03<00:00, 1.06it/s]
100%|███████████████████████████████████████████| 24/24 [30:35<00:00, 76.49s/it]
----creative-writing Benchmark Complete----
2024-12-20 02:06:41
Time taken: 97.6 mins
Prompt Format: llama3
Model: unsloth/Meta-Llama-3.1-8B-Instruct
Creative Writing Score: 60.82
Judge: claude-3-5-sonnet-20241022
---------------
Batch completed
Time taken: 97.6 mins
---------------2GPU環境(a6000+a2000)だったため、CUDA_VISIBLE_DEVICES=0を追加して実行したところ、実行スピードは段違いでした。
こちらもllama3とほぼ同じくらいのスコアでした。
{kind=link}
はい。
とはいえ、ベンチ回しただけでは味気が無いので日本語化していきます。
あんまりうまくいってないので折衷案を採用しています。
EQ-benchの半日本語化
日本語化フォークを作っておきました。
※ 注意!以下に書いている通り、日本語化が不十分です。日本語ダイアログについて、英語の質問やテンプレートで評価させる不完全な内容となっています。だれか~バグ取りしてくれ~。
このリポジトリ内には、以下の変更が含まれています。
eq-bench.pyへの日本語設定の追加
eq_bench_v2_questions_171.jsonをClaudeで翻訳したeq_bench_v2_questions_171_ja.jsonの作成
ただし、llama3.1では完走しませんでした。日本語のフォーマットをあんまり守ってくれないようです。
そのため、jahalfというモードを追加しました。これは上記のデータ例でいうと、ダイアログ部分のみを日本語訳したものです。eq_bench_v2_questions_171_jahalf.jsonがデータセットです。
問題点は[End dialogue]にあるように、日本語ダイアログに記載されている人名と対応が取れるかが怪しい点です。
スコア部分が英語なので、スコア評価は英語用のparse_answers()を使用しています(EQ-Bench-jp\lib\eq_bench_utils.py)。
eq_bench_v2_questions_171_jahalf.jsonについて
翻訳のため、translate_anthropic.pyをChatGPTに作ってもらいました。これでeq_bench_v2_questions_171_ja.jsonのほとんどは作れましたがた、バグ取りしてないため、170件目でバグりました。JSONは随時保存してくれてるので、171だけは手動でclaudeで作成しました。
>python translate_anthropic.py
Progress: 99%|███████████████████████████████████████████████████████████████████▌| 170/171 [40:42<00:15, 15.64s/item]Error decoding JSON from translated text: Unterminated string starting at: line 13 column 1 (char 2388)
Progress: 99%|███████████████████████████████████████████████████████████████████▌| 170/171 [41:14<00:14, 14.55s/item]
Traceback (most recent call last):
File "I:\dev\eqbench\EQ-Bench-jp\data\translate_anthropic.py", line 159, in <module>
process_file(input_file_path, output_file_path, raw_file_path, api_key, start_index)
File "I:\dev\eqbench\EQ-Bench-jp\data\translate_anthropic.py", line 128, in process_file
raise ValueError(f"Translation failed for item {key}.")
ValueError: Translation failed for item 171.また、手動の編集作業として、eq_bench_v2_questions_171_ja.jsonに以下の変更を加えたうえで、下記コードにて自動置換しました。
:"を": "に置き換えています。
[End dialogue]の翻訳にぶれがあったので[対話終了]に統一(4件くらい)
冒頭のYour task is to predict the likely emotional responses of a character in this dialogue:の翻訳にぶれがあったのであなたの課題は、この対話における登場人物の感情的な反応を予測することです:に統一(4件くらい)
import json
dir_json_jahalf = r"I:\dev\eqbench\新しいフォルダー\eq_bench_v2_questions_171_jahalf.json"
with open(dir_json_jahalf, 'r', encoding="utf-8") as f:
data_jahalf = json.load(f)
dir_json_en = r"I:\dev\eqbench\新しいフォルダー\eq_bench_v2_questions_171.json"
with open(dir_json_en, 'r', encoding="utf-8") as f:
data_en = json.load(f)
s_ref = "reference_answer"
s_ref_fill = "reference_answer_fullscale"
l_emotion = ["emotion1","emotion2","emotion3","emotion4"]
# 冒頭のダイアログを日本語から英語に置き換え
s_initiate_ja = "\nあなたの課題は、この対話における登場人物の感情的な反応を予測することです: \n\n"
s_initiate_en = "\nYour task is to predict the likely emotional responses of a character in this dialogue:\n\n"
# この部分以降である評価フォーマット部分を英語に置き換え
s_seach_ward_ja = "[対話終了]\n\n"
s_seach_ward_en = "[End dialogue]\n\n"
for i in range(170):
data_jahalf[str(i+1)]["prompt"] = data_jahalf[str(i+1)]["prompt"].split(s_seach_ward_ja)[0] + s_seach_ward_en + data_en[str(i+1)]["prompt"].split(s_seach_ward_en)[1]
data_jahalf[str(i+1)]["prompt"] = data_jahalf[str(i+1)]["prompt"].replace(s_initiate_ja, s_initiate_en)
for i_emotion in l_emotion:
# 翻訳済みのemotion部分を置き換えます。
data_jahalf[str(i+1)]["reference_answer"][i_emotion] = data_en[str(i+1)]["reference_answer"][i_emotion]
data_jahalf[str(i+1)]["reference_answer_fullscale"][i_emotion] = data_en[str(i+1)]["reference_answer_fullscale"][i_emotion]
# 保存部分
with open(dir_json_jahalf.replace(".json", "_reconst.json"), 'w', encoding='utf-8') as f:
json.dump(data_jahalf, f, ensure_ascii=False, indent=4)半日本語版EQ-bench(jahalf)の実行
以下のコマンドで日本語版を実行できます。
CUDA_VISIBLE_DEVICES=0 python eq-bench.py --benchmarks eq-bench -l jahalf22番目のデータセットだけリトライが発生していますが、リトライ3回の設定で一応完走しました。
----eq-bench Benchmark Complete----
2024-12-20 22:28:01
Time taken: 17.4 mins
Prompt Format: llama3
Model: unsloth/Meta-Llama-3.1-8B-Instruct
v2
Score (v2_jahalf): 68.09
Parseable: 171.0
---------------
Batch completed
Time taken: 17.4 mins
---------------
いくつかのモデルをjahalfで評価してみる
というわけでいくつかのLLMを評価してあげましょう。
最初と同じくconfig.cfgの[Benchmarks to run]部分にそれぞれの設定を書き足します。
[Benchmarks to run]
myrun1,llama3,unsloth/Meta-Llama-3.1-8B-Instruct,,None,3,transformers,,
myrun2,llama3swallow,tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.2,,None,3,transformers,,
myrun3,llama3swallow,rinna/llama-3-youko-8b-instruct,,None,3,transformers,,
myrun4, openai_api, gpt-4o, , , 1, openai, ,
myrun5, openai_api, gpt-4o-mini, , , 1, openai, ,
myrun6, Mistral, unsloth/mistral-7b-instruct-v0.3,,None,3,transformers,,
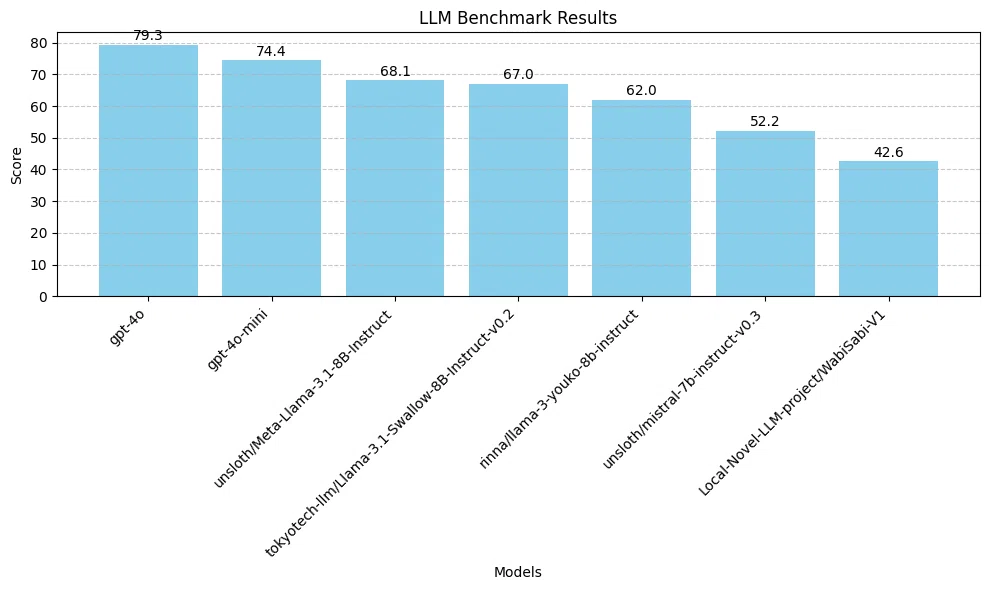
myrun7, Vicuna-v1.1, Local-Novel-LLM-project/WabiSabi-V1,,None,3,transformers,,結果
{kind=link}
まあ、それっぽく並んでるんじゃないでしょうか。
質問やパラメータ名周りが英語になっているので、日本語に強い小型LLMだと逆に苦手になってしまうのかもしれません。
まあ、この数で判断できるものではないですが。
最後に
お疲れさまでした。
一番便利そうなCreative Writing日本語化については後々更新します。
まあ、やっといてあれですが、明確な基準がなく感情の数値を推定する作業って結構感覚の違いとかが出る気がするので、だいぶ厳密ではないかもしれません。
もう少し、数値ごとの基準などが明確に記述されているようなベンチに改良したほうがいいのかもしれません。
もともとVLM関連の記事を上げようとしていましたが、学習が完走せず断念しました。ロスが0.005とかになっててモデル出力が壊れてました。
それでは!クロガネでした!
いいねと感じたら、記事のいいねやnoteのフォローもお願いします!
note → 鐵火卷|note
良ければXのフォローもお願いします!
X → @Kurogane_8_Gk