
{kind=link}
日本語検索向けテキスト埋め込みモデル「AMBER」を公開しました!
こんにちは!リサーチャーの勝又(@katsumata420)です!私はレトリバで自然言語処理に関する研究の最新動向調査やキャッチアップなどを行っております。
今回の記事では、先日弊社が公開した日本語検索向けテキスト埋め込みモデル「AMBER」について、簡単な紹介や既存モデルとの性能比較を紹介します!
なお、本モデルはHuggingface Hubにて公開しております。実際にモデルを試してみたい方は[baseサイズリンク]または[largeサイズリンク]からご利用ください!
AMBERの概要
先日我々は日本語検索向けテキスト埋め込みモデル「RetrievaEmbedding-01: AMBER(Adaptive Multitask Bilingual Embedding Representation)」を公開しました。本モデルはbase/largeサイズの2種類を公開しております。
これらのモデルは名前の通り、「2言語(日本語と英語)について」「様々な自然言語処理タスク」で学習を行っております。学習に使用した工夫の一部につきましては、先日開催されました、言語処理学会第31回年次大会(NLP2025)にて「インストラクションと複数タスクを利用した日本語向け分散表現モデルの構築」という題で発表いたしました。発表予稿も公開されておりますので、ご興味のある方はこちらの予稿をご確認いただけますと幸いです。
既存モデルとのスコア比較
こちらのニュースリリースに記載されておりますように、本モデルは日本語検索について、パラメータ数が500M以下のモデルの中では(公開時点では)最高性能となっておりました。本記事ではその点についてもう少し踏み込んで報告いたします。
また、合わせて日本語テキスト埋め込みベンチマークJMTEBや英語テキスト埋め込みベンチマークMTEB (eng, v2)での評価結果についても報告いたします。
日本語タスクに関して、以下の既存モデルと比較を実施します。これらのモデルはAMBER公開当時または本記事公開時点で特に高い精度を報告している日本語向けテキスト埋め込みモデルです。
cl-nagoya/ruri-base-v2(AMBER公開後に公開されたモデル)
cl-nagoya/ruri-large-v2(AMBER公開後に公開されたモデル)
また、英語タスクに関しては、 以下の既存モデルと比較を実施します。これらのモデルはAMBERと同様に、日本語や英語で高い精度で動作することを報告したテキスト埋め込みモデルです。
日本語検索タスクでの性能比較
公開モデルについて、日本語検索タスクでどの程度の性能が出るか検証を実施しました。
検証に使用したデータは次の通りです(なお、1-6のデータはJMTEBを通して評価を行い、7と8の評価は公式実装を通して評価を行い、9はMTEBを通して評価を行いました。)
JAQKET [JMTEBリンク]
Mr.TyDi-ja [JMTEBリンク]
JaGovFaqs-22k [JMTEBリンク]
NLP Journal title-abs [JMTEBリンク]
NLP Journal title-intro [JMTEBリンク]
NLP Journal abs-intro [JMTEBリンク]
JQaRA [公式実装リンク]
JaCWIR [公式実装リンク]
MLDR-ja [MTEBリンク]
評価結果は以下の表の通りです。
{kind=link}
この結果から、平均するとAMBER公開時点では、AMBERのlargeモデルが日本語検索タスクで最高精度を達成していることがわかります。一方で、先日公開されたcl-nagoya/ruri-large-v2と比較すると性能にまだまだ差があることがわかります。
日本語テキスト埋め込みモデルベンチマークでの性能比較
公開モデルについて、検索だけでなく、分類やクラスタリング、Semantic Textual Similarity(STS)といった様々なタスクでどの程度の性能が出るか、日本語テキスト埋め込みモデルベンチマークJMTEBを用いて検証を実施しました。
JMTEBは日本語の埋め込み表現に関する様々な評価データセットを集めたベンチマークです。詳細は公開した方々から解説記事も出ておりますのでそちらをご確認ください。
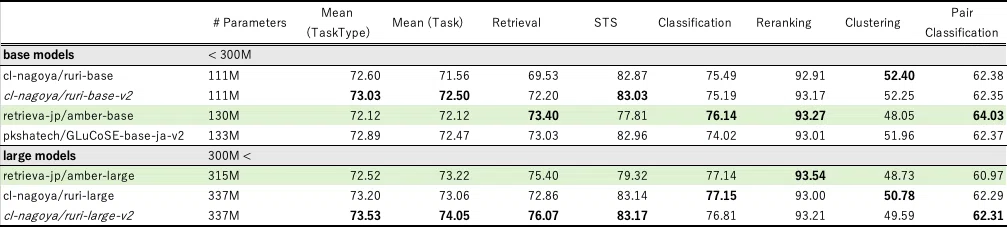
JMTEBに関する評価結果は以下の表の通りです。ただし注意点としまして、平均の値として2種類の算出方法を実施しております。具体的には、「各評価データセットのスコアを等しく扱い平均を行ったMean (Task)」と、「各評価データセットのスコアを一度各タスク種別で平均し、そのタスク種別の平均を平均したMean (TaskType)」を記載しております。
{kind=link}
平均スコアの結果から、平均の算出方法やモデルサイズによって多少前後しますが、公開モデルAMBERは既存モデルと遜色ない性能であることがわかります。また、タスク種別を確認すると、Retrievalタスクでは公開時点では最も高い精度でした。
英語テキスト埋め込みモデルベンチマークでの性能比較
AMBERは学習データに日本語データだけでなく、英語データも含めております。そのため、理屈の上では英語テキスト埋め込みついてもある程度機能すると考えられますので、ここでは英語テキスト埋め込みモデルベンチマークMTEB (eng, v2)を用いて検証を実施しました。
MTEB (eng, v2)は英語の埋め込み表現に関する様々な評価データセットを集めたベンチマークです。詳細は、解説記事や論文、公式の実装などをご確認ください。
MTEB (eng, v2)に関する評価結果は以下の表の通りです。なお、「各評価データの平均」や「各評価タスク種別の平均」として、日本語テキスト埋め込みベンチマークと同様にMean (Task)とMean (TaskType)を記載しております。
{kind=link}
この結果から平均スコアの上では既存モデルに対して低いものとなっていますが、一部タスク種別では優れた結果となっていることがわかります。
おわりに
日本語検索向けテキスト埋め込みモデル「AMBER」を構築し公開いたしました。本モデルは商用利用可として公開しておりますので、ぜひお気軽にご利用いただければと思います。ご不明な点などございましたら、 pr@retrieva.jpやHuggingface HubのDiscussionへご連絡ください。