
More than 5 years have passed since last update.
{kind=link}
2chのスレッドをWordCloudで可視化してみる ~形態素解析・WordCloud編~
はじめに
2chはスレッドのレス一つ一つに目を通すのに時間がかかってしまうので、
スレッド情報をWordCloudで可視化し、簡単に全体像をつかめないかと試みた。
👁 Image
前回のスクレイピング編では所望のスレッド群のレス内容を抽出してきた。
今回は後編として、前回収集したレス内容を形態素解析し、WordCloudでの出力までを行なう。
{kind=link}
{kind=link}
全体の流れ
- 「ログ速」をスクレイピングして対象スレッドのURLを抽出
- 2chスレッドをスクレイピングしてレスを抽出
- 抽出したレス内容をMecabで形態素解析 ← 今回説明
- WordCloudで出力する ← 今回説明
{kind=link}
{kind=link}
環境
前回同様、GoogleColaboratoryを使用する。
GoogleColaboratoryは、ブラウザ上で動作するPythonの実行環境。Googleアカウントさえあれば、誰でも使える。
Mecabは追加インストールが必要(後述)だが、WordCloudはGoogleColaboratoryにデフォルトで入っているためインストール不要。
コード全文
説明
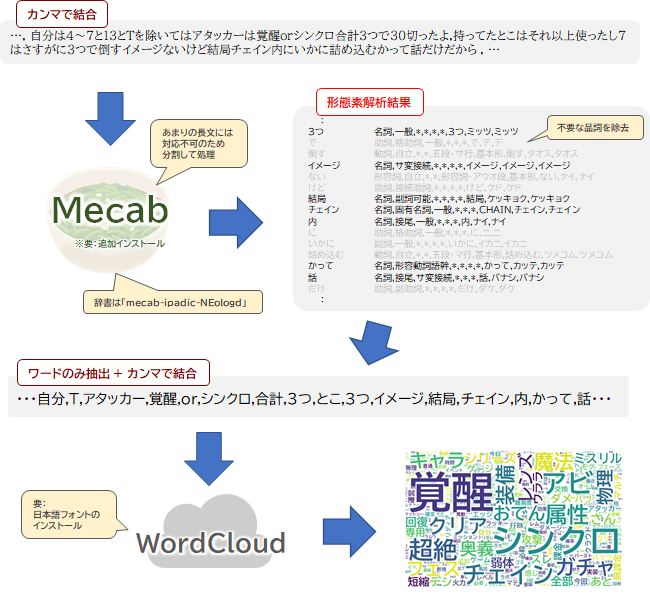
Mecabによる形態素解析
形態素解析は、自然言語の文章を単語(正確に言えば単語よりさらに細かい形態素と呼ばれる単位)に分解する処理。
日本語は英語のように単語と単語の間に空白を入れたりしないため、形態素解析を行なって単語同士を切り離す必要がある。
形態素解析を行うツールはいくつかあるが、今回は処理速度が速く、精度も高い「Mecab」を使用する。
Mecabのインストール
MecabはGoogleColaboratoryにデフォルトで入っていないため、都度、下記を実行してインストールする。
# Mecabのインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
辞書の指定(mecab-ipadic-NEologd)
Mecabのデフォルト辞書「mecab-ipadic」は、新語に対してそれほど精度が高くない。
そこでオススメするのが**「mecab-ipadic-NEologd」という辞書の仕様。
「mecab-ipadic-NEologd」はMecabで使えるシステム辞書の一つで、更新頻度が高いため新語に強いのが特徴**。
例えば、「エアリス」というキーワードを形態素解析したとき。デフォルトの辞書だと「エア / リス」と分割された形態素としてしまうが、「mecab-ipadic-NEologd」だとちゃんと「エアリス」を一つの単語だと判断してくれる。
2chのような新語が跋扈するような環境では「mecab-ipadic-NEologd」を用いたほうが解析の精度が上がるはず。
インストール方法については、下記のように行なう。
# 辞書(mecab-ipadic-NEologd)のインストール
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
後ほどMecabで呼び出す際にmecab-ipadic-neologd辞書が格納されたパスを指定する必要があるので、定義しておく。
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
形態素解析のデータ前処理
Mecabにテキストデータを渡す際のポイントは2つ
・Mecabは一つのstr型のデータを渡す(今回の場合カンマで結合した文字列)
・上記str型があまりにも**
# レスをn(=10000)レス毎に区切り、カンマで結合
# 区切る目的はのちのmecabが多すぎる文字量に対応できないため
sentences_sep = []
n = 10000
for i in range(0, len(res_df["comment"]), n):
sentences_sep.append(",".join(res_df["comment"][i: i + n]))
形態素解析の実行
Mecabは ① Mecab.Taggerインスタンスの生成 → ② インスタンスに対象のテキストを渡してparse(解析) の流れで行なう。
①のインスタンスを生成する際に、解析のオプションを指定する。
前述のシステム辞書「mecab-ipadic-NEologd」を使用したいので、事前に取得しておいたパスを指定する。
②の解析結果はTaggerインスタンス.parse(str型)で取得する。
今回のケースでは、前述の通りレス群を分割してリスト型にしたので、pythonっぽく内包表記を用いて処理を行なってみた。
import MeCab
# インスタンスの生成
mecab = MeCab.Tagger(path)
# 区切ったレス群ごとに形態素解析を実行
chasen_list = [mecab.parse(sentence) for sentence in sentences_sep]
出力は下記のような改行とタブ区切りの混じったstr型となる。
👁 Image
{kind=link}
{kind=link}
ノイズの除去
切り出した単語のうち「助詞」「助動詞」や「副詞」など単体で意味をなさない言葉はノイズになりうるので、除外する。
今回はシンプルに「名詞」のみを抽出するようにした。ただし、名詞のなかでも非自立、代名詞、数 などはノイズになりそうなので除外した。
処理として、Mecab出力結果のstr型を.splitlines()で一行ずつに分解 → さらに.split()で単語と品詞情報に分解
→ 品詞情報が条件に合致した場合、単語部分をword_listに加えていくようにした。
# ノイズ(不要品詞)の除去
for chasen in chasen_list:
for line in chasen.splitlines():
if len(line) <= 1: break
speech = line.split()[-1] ## 品詞情報を抽出
if "名詞" in speech:
if (not "非自立" in speech) and (not "代名詞" in speech) and (not "数" in speech):
word_list.append(line.split()[0])
途中のif len(line) <= 1: breakはエラー(多分EOS起因)対策。
最後にlist型を一つのstr型に連結する。
# 単語の連結
word_line = ",".join(word_list)
WordCloudで出力
(事前準備)日本語対応フォントのインストール
日本語をWordCloudにかける場合、フォントを日本語対応のものに指定する必要がある。
ローカルならば所望のフォントのパスを指定するだけで良いのだろうが、
GoogleColaboratoryの場合、少しだけ面倒。
↓
まず事前に、自分のGoogleDrive上に所望のフォントファイルをコピーしておく(TrueTypeフォントのみ対応)。
場所は任意だが、参考にした記事になぞらえて、マイドライブTopに「font」フォルダを作成し、その中にファイルを格納した。
👁 Image
Colaboratory上でGoogleDriveをマウントする。
{kind=link}
{kind=link}
# フォントをColabローカルにインストール
from google.colab import drive
drive.mount("/content/gdrive")
上記を実行するとGoogleDriveをマウントするためのリンクが表示されるので、クリックしてアカウントを選択 → 許可 → 表示されるコードを、GoogleColaboratory上で入力することでマウントできる。
コマンドで先ほどのフォントファイルをフォルダごとColaboratoryローカルの指定フォルダにコピーする。
!cp -a "gdrive/My Drive/font/" "/usr/share/fonts/"
WordCloudの実行
WordCloudライブラリをインポートし、WordCloud()でインスタンスを生成する。
この()の中に引数を与えることで、様々な出力パラメータを設定することができる。
from wordcloud import WordCloud
f_path = "BIZ-UDGothicB.ttc" # Colabローカルのfontsフォルダにコピーしておく必要あり
stop_words = ["https","imgur","net","jpg","com","そう"]
# インスタンスの生成(パラメータ設定)
wordcloud = WordCloud(
font_path=f_path, # フォントの指定
width=1024, height=640, # 生成画像のサイズの指定
background_color="white", # 背景色の指定
stopwords=set(stop_words), # 意図的に表示しない単語
max_words=350, # 最大単語数
max_font_size=200, min_font_size=5, # フォントサイズの範囲
collocations = False # 複合語の表示
)
各パラメータの内容は以下のような感じ。
| パラメータ | 説明 | 設定値 |
|---|---|---|
| font_path | フォントの指定 | 前述したフォントのパス(f_path) |
| colormap | フォントのカラーセット (matplotlibのカラーマップで指定) |
未設定(既定値:viridis) |
| width | 生成画像の幅 | 1024 |
| height | 生成画像の高さ | 640 |
| background_color | 背景色 | white |
| stopwords | 意図的に表示しない単語(set) | ["https","imgur","net","jpg","com","そう"] |
| max_words | 表示する単語の最大数 | 350 |
| max_font_size | 最も多い単語のフォントサイズ | 200 |
| min_font_size | 最も少ない単語のフォントサイズ | 5 |
| collocations | つながった単語を表示するか否か | False |
上記以外のパラメータについては最後述の記事の記事を参考にする。
上記で生成したwordcloudインスタンスのメソッド.generate(連結した単語群:str型)で対象の文字列から図を生成する。
# 文字列を与えてWordCloud画像を生成
output_img = wordcloud.generate(word_line)
matplotlibで表示
import matplotlib.pyplot as plt
plt.figure(figsize=(18,15)) # figsizeで表示する大きさを指定
plt.imshow(output_img)
plt.axis("off") # 目盛りを非表示にする
plt.show()
無事表示することができた。
所感・今後
とりあえず、何とか可視化することはできたにはできたのだが、何だかぼやけてしまっている気がする。
その理由として「時間軸」「単語同士の相関」などが見えなくなってしまったことが一因であると思う。
そのため、時間があるときに
・時間軸との相関表示(グラフ)
・共起ネットワーク などいじってみたい。
記事を書くかは未定。
参考記事
Google Colabの使い方まとめ
Google ColabにMeCabとipadic-NEologdをインストールする
Google Colaboratoryに好きなフォントを入れてmatplotlibとかで使う方法
PythonでWord Cloudを作ってみた ← 今回触れていないwordcloudパラメータの説明あり
Register as a new user and use Qiita more conveniently
- You get articles that match your needs
- You can efficiently read back useful information
- You can use dark theme