
More than 5 years have passed since last update.
R超入門 - Rのインストールから決定木とランダムフォレストによる分析まで
概要
Rは対話的にデータ分析をおこなうことに適したプログラミング言語であり、それに加えてデータの可視化などのパッケージも含むデータ分析の「スイート」と言えます。
この記事ではまだRに触れたことがないユーザーが、Rの基本を解説しつつ、決定木およびランダムフォレストと呼ばれるアルゴリズムを用いた予測モデルを作成する手順までをチュートリアル形式でカバーしていきます。
このチュートリアルを終えると、構造化データの統計を瞬時に算出できるようになり、かつ、その分析モデルをつかって予測をおこなうことができるようになります。
環境
OSはMacOS X Yosemiteを利用しますが、Macの他のバージョン、およびWindowsでもほとんどの手順はそのまま適用できるはずです。
インストール
下記URLよりお使いのOSに合ったRをダウロードします。
https://cran.ism.ac.jp
インストーラーを実行します。
これでインストールは完了です。次にRを起動します。
Rはターミナルから利用する方法と、専用のコンソールから利用する方法の2通りあります。今回は専用のコンソールを利用します。
アプリケーションランチャーからRアプリを起動します。
👁 launch R app.png
{kind=link}
{kind=link}
基本的な文法
Rでは言うまでもなくデータを操作するのが最も重要な作業です。Rではデータを格納する構造体のことを「オブジェクト」と呼んでおり、いくつかのタイプがあります。
まずは数値をオブジェクトに保存する方法を見てみます。
>x=2>これでxというオブジェクトが作成され、2という数値がセットされました。
オブジェクト:xの中身を確認するには下記のように単にxとうちます。
>x[1]2>あるいはprint()コマンドを使うこともできます。結果は同じです。
>print(x)[1]2>この例では「=」を使ってオブジェクトに値をセットしましたが、これは下記のようにも記述できます。結果は全く同じです。
>x<-2>x[1]2>そしてこの矢印の方向を逆にすることで、値とオブジェクトを反対に記述することもできます。
>2->x>x[1]2>世にあるRのサンプルコードは「<-」を使って代入を記述しているものが多いようですが、この記事では一文字節約できる「=」を使っています。
Rには型宣言というものはありません。セットした値によって自動的に型が判断され、たとえ最初に数値を入れていたオブジェクトでも、文字列で上書きすることもできます。
>x="に">print(x)[1]"に">今現在セットされているオブジェクトはls()コマンドで確認できます。
>ls()[1]"x">オブジェクトはrm()コマンドで削除できます。
>rm(x)>ls()character(0)>一般的な記法で演算をおこなうこともできます。
>1+2*3[1]7>特に重要なオブジェクト:ベクトル
次にベクトル(Vector)をみていきましょう。
ベクトルとはオブジェクトのタイプの一つで、順序付けられた複数の値を保持するオブジェクトです。他の言語でいう配列に極めて近しいものだと言えます。
例えば1, 3, 8という3つの数値からなるベクトルは下記のように作成します。
>x=c(1,3,8)>x[1]138>これはc()という関数を用いて複数の数値から一つのベクトルを作成しています。
数値が連続する値であれば下記のようにベクトルを作成することもできます。
>x=1:8>x[1]12345678>length()コマンドによってベクトル内の要素数を確認できます。
>x=1:8>length(x)[1]8>特に重要なオブジェクト:データフレーム
データフレームとは表のようなデータ構造を持つオブジェクトです。各列は異なるデータ・タイプをとることができます。例えば下記のような文字列型と数値型が混在するデータを一つのデータフレームとしてオブジェクトに収めることができます。
| id | name | age |
| --:|--:|--:|--:|
| 1 | Kazuki Nakajima | 16 |
| 2 | Umi Tanaka | 22 |
| 3 | Natsu Yamada | 24 |
| 4 | Sora Ito | 26|
実際に上記の表形式データをデータフレームにセットしてみます。
>x=data.frame(id=1:4,name=c("Kazuki Nakajima","Umi Tanaka","Natsu Yamada","Sora Ito"),age=c(16,22,24,26))>data.frame()関数によってデータフレームを作成しています。
データフレームには必ず列名を指定します。上記の例では、id, name, ageが列名となります。各列名に対してベクトルを代入することで表形式のデータを作成する形です。
オブジェクト:xの中身を確認してみます。
>xidnameage11KazukiNakajima1622UmiTanaka2233NatsuYamada2444SoraIto26>データが表形式で格納されているのがわかります。
データフレームの行数を確認するにはnrow()コマンドを利用します。
>nrow(x)[1]4データフレームの列数を確認するにはlength()コマンドを利用します。
length()コマンドはベクトルに対してい実行すると要素数を返しますが、データフレームの場合は列数を返します。
>length(x)[1]3>dim()コマンドを使うとデータフレームの行数と列数を両方同時に確認できます。
>dim(x)[1]43>データフレームに収まったデータは任意の部分を取り出すことができます。
例えば先ほどのデータフレームで、2行目だけ取り出すには下記のように指定します。
>x[2,]idnameage22UmiTanaka22>特定の列だけ取得することも可能です。
下記の例では2列目だけを取得しています。
>x[,2][1]KazukiNakajimaUmiTanakaNatsuYamadaSoraItoLevels:KazukiNakajimaNatsuYamadaSoraItoUmiTanaka>特定の列を取得する場合、列名を指定することもできます。下記のようにオブジェクト$列名と指定します。
>x$name[1]KazukiNakajimaUmiTanakaNatsuYamadaSoraItoLevels:KazukiNakajimaNatsuYamadaSoraItoUmiTanaka>1行目から3行目までを取得した場合、下記のように書けます。
>x[1:3,]idnameage11KazukiNakajima1622UmiTanaka2233NatsuYamada24>1から3行目、というのを1:3で表しています。
このデータフレームに関して言えば、上記結果は下記のようにも書けます。
>x[-4,]idnameage11KazukiNakajima1622UmiTanaka2233NatsuYamada24>-4によって「4行目以外」を表しています。
当然行の指定と列の指定を組み合わせることもできます。
>x[1:3,3][1]162224>これでデータフレームの基本的な操作が理解できました。
データをファイルからロードする
本格的なデータを扱うためにファイルからデータをロードする方法をみていきます。サンプルデータとして下記のファイルをまずダウンロードしてください。
このデータは保険商品を販売する会社の顧客リストです。一行が一人の顧客となっており、名前、年齢、未婚・既婚、貯金、収入などといった情報が格納されています。
ダウンロードしたファイルを作業ディレクトリ(Working Directory)に保存します。作業ディレクトリとはRが必ず保持しているセッション情報で、デフォルトではユーザーのホームディレクトリになっています。
現在の作業ディレクトリはgetwd()コマンドで確認できます。
>getwd()[1]"/Users/nkjm">上記の例では/Users/nkjmが作業ディレクトリということになります。ここにダウンロードしたcsvファイルを保存してください。この後read.csv()関数でファイルをロードしますが、この関数はデフォルトでは作業ディレクトリ直下のファイルをロードします。
ちなみに、作業ディレクトリはsetwd()コマンドで変更できます。また、実際にはファイルは作業ディレクトリ直下におかずとも、read.csv()関数でパスを指定することでファイルを指定できます。
ではread.csv()関数でファイルをロードします。read.csv()関数はファイルからデータを読み込んでデータフレームに格納してくれます。
>customers=read.csv("sample_customers.csv")>read.csv()関数はread.table()関数のラッパー関数で、セパレーターが,(カンマ)であるという設定でファイルを読み込みます。
今回はcustomersというオブジェクトにデータフレームでデータが格納されています。dim()関数で行数、列数を確認しておきましょう。
>dim(customers)[1]101531>今回のデータは1015行、31列で構成されていることがわかります。
オブジェクトの中身をそのまま出力することもできますが、データ量がそれなりにあるので、とりあえずどんなデータが読み込まれたか確認するのであればhead()関数が便利です。データの先頭6行だけ表示してくれます。下記は表示上一部の列しか転記していませんが、列については全列表示されます。
>head(customers)CUSTOMER_IDLASTFIRSTSTATEREGIONSEXPROFESSIONBUY_INSURANCEAGE1CU6117BERNADINEPRITCHETTNYNorthEastFAuthorNo02CU15015RANDOLPHMCMANUSNYNorthEastMPROF-18No393CU9590WILBEREMERYNYNorthEastMPROF-17No244CU2507RUSTYHILLMANCAWestMAdministrativeAssistantNo05CU13551BRANDONFOSSFLSouthMProgrammer/DeveloperNo216CU7788BRYANGARCIAMIMidwestMPROF-12No22>さて、ここでRのパワーが発揮されます。customersオブジェクトをsummary()関数にかけてみます。summary()は一瞬にしてデータフレームから統計情報をまとめてくれる関数です。
*この出力も表示の関係で一部の列だけ転記しています。
>summary(customers)CUSTOMER_IDLASTFIRSTSTATEREGIONSEXPROFESSIONBUY_INSURANCEAGECU100:1JUDE:4BRYSON:4NY:343Midwest:220F:344Programmer/Developer:137No:742Min.:0.00CU10006:1VAL:4COYLE:4CA:235NorthEast:375M:671ITStaff:89Yes:2731stQu.:27.00CU10011:1ALVA:3HOGUE:4MI:168South:69Nurse:54Median:36.00CU10012:1BOYCE:3BRANCH:3FL:36Southwest:57Clerical:35Mean:38.19CU10020:1CALEB:3CASH:3DC:32West:294Notspecified:343rdQu.:48.00CU10025:1CAMERON:3DICKENS:3MN:26Cashier:32Max.:84.00(Other):1009(Other):995(Other):994(Other):175(Other):634データの特性に応じて、文字列型の場合はカテゴリーであると仮定して値の出現回数がカウントされ、数値型については最小値、最大値、平均値などが計算されています。
一瞬にしてデータから統計を算出する機能が備わっているところからRの本領が少しづつ垣間みえます。
決定木でデータを分析する
まず仕組みが理解しやすい分析手法である決定木を使ったデータ分析を実施してみます。
最初に決定木の実装であるrpartライブラリをロードします。
>library(rpart)>では早速分析を実行してみましょう。
先ほどロードした保険商品の顧客データは、すべて営業アプローチ済みで、保険を契約してくれたかどうかの結果がYes/NoでBUY_INSURANCE列に格納されています。この実績データを元に、どのような顧客が保険を契約する可能性が高いのかという顧客プロファイルの傾向分析をおこなっていきます。
分析はrpart()関数を実行することでおこないます。
この関数に必要なのは下記3つのパラメーターです。
- 学習データ(今回はcustomers)
- 予測する列(今回はBUY_INSURANCE)
- 傾向を分析する列(今回はBUY_INSURANCE以外の列)
上記を踏まえ、rpart()関数を実行します。rpart()関数は第一引数に予測する列および傾向を分析する列を下記のフォーマットで指定します。
予測する列 ~ 傾向を分析する列
今回傾向を分析する列には.(ドット)を指定しています。これは予測する列以外すべての列を意味しています。
そしてdataオプションに学習データを指定します。(今回はcustomers)
>model=rpart(BUY_INSURANCE~.,data=customers)>するとほぼ一瞬で分析が完了します。
結果がmodelオブジェクトに入っていますので確認してみます。
>modeln=1015node),split,n,loss,yval,(yprob)*denotesterminalnode1)root1015273No(0.73103450.2689655)2)CUSTOMER_ID=CU100,CU10006,CU10011,CU10012,CU10020,CU10025,CU10044,CU1015,CU10180,CU10208,CU10218,CU10228,CU10236,CU10308,CU10339,CU10361,CU1037,CU10370,CU10375,CU10377,CU10410,CU10411,CU10447,CU10473,CU10477,CU10505,CU10508,CU10518,CU10540,CU1055,CU10565,CU10566,CU10597,CU1065,CU10653,CU10655,CU10680,CU1069,CU10706,CU10707,CU10745,CU10784,CU10801,CU10813,CU10831,CU10855,CU10856,CU1091,CU10961,CU10989,CU11006,CU11020,CU11028,CU11032,CU11034,CU11048,CU11086,CU11108,CU11113,CU11130,CU11143,CU11171,CU11201,CU11209,CU11231,CU11246,CU11260,CU11319,CU11324,CU11325,CU1134,CU11341,CU11347,CU11355,CU11392,CU1140,CU1141,CU11429,CU11501,CU11516,CU11574,CU1161,CU11615,CU11680,CU11683,CU11693,CU11694,CU11717,CU11849,CU11850,CU11854,CU11877,CU11886,CU11917,CU11941,CU11958,CU11983,CU1202,CU12026,CU12070,CU12107,CU12112,CU12127,CU12128,CU12168,CU12175,CU12180,CU12208,CU12216,CU12217,CU12228,CU12235,CU1228,CU12283,CU12325,CU12331,CU12337,CU12361,CU12367,CU12404,CU12406,CU12409,CU1245,CU12451,CU12515,CU12517,CU12518,CU12527,CU12528,CU12567,CU12581,CU12595,CU12603,CU12638,CU12641,CU12663,CU12672,CU12702,CU12777,CU12821,CU12859,CU129,CU12921,CU12982,CU12993,CU13028,CU13042,CU13087,CU13111,CU13120,CU13133,CU13184,CU13188,CU13221,CU13235,CU13245,CU13263,CU13265,CU13297,CU1330,CU13322,CU13357,CU13369,CU13386,CU13388,CU13390,CU13411,CU13442,CU13483,CU13492,CU135,CU13503,CU13508,CU13515,CU13543,CU13551,CU13562,CU13624,CU13653,CU13664,CU13678,CU1371,CU13713,CU13730,CU13737,CU13739,CU13795,CU13847,CU13885,CU13887,CU13889,CU13908,CU13956,CU13966,CU13980,CU14011,CU14018,CU14034,CU14045,CU14068,CU14108,CU14140,CU14153,CU14215,CU14235,CU14250,CU14254,CU1427,CU14284,CU14291,CU14302,CU14304,CU14308,CU14309,CU14310,CU14334,CU14336,CU14470,CU14487,CU14493,CU14507,CU14514,CU14537,CU14553,CU14560,CU14620,CU14631,CU14664,CU14670,CU14690,CU14708,CU14713,CU14733,CU14743,CU14746,CU14750,CU14768,CU14770,CU14800,CU14806,CU14833,CU14851,CU14893,CU14938,CU14941,CU14965,CU14974,CU14975,CU14991,CU14993,CU15015,CU15033,CU15069,CU15084,CU15116,CU15133,CU15141,CU15148,CU1516,CU15161,CU15175,CU15186,CU15198,CU15231,CU15240,CU1527,CU15289,CU153,CU1531,CU15400,CU15421,CU15455,CU1547,CU15471,CU15532,CU15559,CU15599,CU15635,CU15671,CU15694,CU15745,CU15766,CU15780,CU15782,CU15784,CU15798,CU15800,CU15809,CU15821,CU15828,CU15839,CU15852,CU15853,CU15866,CU15879,CU15886,CU15889,CU15927,CU15942,CU15957,CU15960,CU15979,CU1600,CU1612,CU165,CU1653,CU1655,CU1704,CU172,CU1720,CU1722,CU1731,CU1745,CU1815,CU1829,CU1832,CU1840,CU1851,CU1861,CU1881,CU1891,CU1901,CU1915,CU1935,CU1954,CU197,CU2,CU2005,CU2055,CU2088,CU2100,CU2108,CU2129,CU2144,CU216,CU2185,CU2206,CU2235,CU2245,CU2269,CU2313,CU2320,CU2332,CU2366,CU2410,CU2417,CU2491,CU2507,CU2533,CU2536,CU2555,CU2570,CU2587,CU259,CU2604,CU2605,CU2611,CU2620,CU2624,CU2639,CU2654,CU2669,CU27,CU2703,CU2713,CU2714,CU2769,CU2788,CU2798,CU2799,CU2804,CU2806,CU2855,CU2866,CU2870,CU2880,CU289,CU2941,CU2943,CU2956,CU2966,CU3003,CU3039,CU3040,CU3044,CU3065,CU3070,CU3084,CU3091,CU3093,CU3095,CU3113,CU3147,CU3167,CU3193,CU3197,CU3229,CU3239,CU3243,CU3265,CU3296,CU3323,CU3376,CU339,CU34,CU3421,CU3433,CU3441,CU3461,CU3486,CU3526,CU3537,CU3569,CU3587,CU3646,CU3715,CU3742,CU3751,CU3777,CU3799,CU3835,CU385,CU3852,CU3889,CU3892,CU391,CU3913,CU3918,CU3921,CU3935,CU3969,CU3971,CU3976,CU3996,CU400,CU4009,CU4020,CU4087,CU4090,CU4101,CU4102,CU4105,CU4113,CU4116,CU4118,CU4125,CU4140,CU4143,CU4147,CU4153,CU4165,CU4171,CU4172,CU4176,CU4188,CU4195,CU4215,CU4245,CU4252,CU4291,CU4292,CU4309,CU4321,CU4344,CU4371,CU4385,CU4395,CU4410,CU4470,CU4544,CU4549,CU4584,CU4598,CU4603,CU4641,CU4663,CU4668,CU4715,CU475,CU4758,CU476,CU4775,CU4808,CU4828,CU4843,CU4845,CU4871,CU4877,CU4884,CU491,CU4914,CU4923,CU493,CU4932,CU497,CU4983,CU4985,CU4994,CU5056,CU5065,CU5090,CU5110,CU5114,CU513,CU5144,CU5151,CU5165,CU5177,CU5201,CU5206,CU5246,CU5248,CU5262,CU5289,CU5310,CU5319,CU534,CU5351,CU544,CU5442,CU5458,CU5460,CU55,CU5511,CU5548,CU557,CU5589,CU5600,CU5632,CU5643,CU5662,CU5676,CU5679,CU5698,CU5700,CU5704,CU5712,CU5726,CU5739,CU5759,CU577,CU5795,CU5852,CU5854,CU5859,CU5916,CU5928,CU5938,CU6027,CU6028,CU6040,CU6061,CU608,CU6097,CU6117,CU6227,CU6243,CU6250,CU6275,CU6286,CU6291,CU6293,CU6304,CU6308,CU6315,CU6365,CU6389,CU6439,CU6461,CU6466,CU6469,CU6476,CU6501,CU6522,CU6523,CU654,CU6543,CU6556,CU6575,CU6607,CU6620,CU6623,CU6641,CU6674,CU6691,CU672,CU6752,CU6758,CU6769,CU6781,CU6791,CU6818,CU6825,CU6846,CU6859,CU6871,CU692,CU6927,CU6928,CU6932,CU6957,CU6965,CU6993,CU7014,CU7028,CU7040,CU7070,CU7079,CU7107,CU7148,CU7171,CU7187,CU72,CU7200,CU7218,CU7244,CU726,CU7291,CU7296,CU73,CU7331,CU7381,CU7394,CU740,CU7412,CU7416,CU7426,CU7472,CU7481,CU749,CU7522,CU7666,CU7681,CU7694,CU7701,CU7733,CU7744,CU7767,CU7788,CU7791,CU7814,CU7837,CU7839,CU7846,CU7854,CU7866,CU790,CU7922,CU7924,CU7949,CU7970,CU7974,CU8014,CU8064,CU8169,CU8180,CU8196,CU8212,CU8218,CU8238,CU8286,CU8359,CU845,CU8450,CU8452,CU847,CU8478,CU848,CU8506,CU8512,CU8520,CU8530,CU8536,CU8559,CU8583,CU8589,CU860,CU8617,CU8630,CU8633,CU8653,CU8662,CU8696,CU8716,CU8726,CU8734,CU876,CU8819,CU8826,CU8831,CU885,CU8880,CU8908,CU8915,CU8916,CU8920,CU8921,CU895,CU8955,CU8983,CU9024,CU9038,CU9102,CU9110,CU9125,CU9138,CU9143,CU9156,CU9217,CU929,CU9290,CU9313,CU9328,CU9347,CU9374,CU938,CU9385,CU9404,CU9437,CU945,CU9461,CU9515,CU9544,CU9555,CU9590,CU9594,CU9648,CU9663,CU9729,CU9746,CU9766,CU9789,CU9791,CU9798,CU9823,CU9839,CU9863,CU9897,CU9913,CU9964,CU998,CU99887420No(1.00000000.0000000)*3)CUSTOMER_ID=CU10041,CU1005,CU10110,CU10119,CU10148,CU10154,CU10161,CU10168,CU10303,CU10386,CU10536,CU10550,CU10728,CU10835,CU10861,CU10922,CU11100,CU11176,CU11214,CU11361,CU11391,CU11412,CU11422,CU11539,CU11541,CU11570,CU11596,CU11608,CU11632,CU11667,CU11688,CU11797,CU11959,CU11970,CU12010,CU12021,CU1229,CU12312,CU1241,CU12479,CU12512,CU12535,CU12573,CU12577,CU12586,CU12658,CU12738,CU12743,CU12786,CU12794,CU12797,CU12842,CU12915,CU1304,CU13052,CU13121,CU13172,CU13196,CU13259,CU13302,CU13368,CU13373,CU13417,CU13533,CU13565,CU13568,CU13588,CU13601,CU13712,CU13802,CU13803,CU13817,CU13831,CU14052,CU141,CU14339,CU14434,CU14500,CU14554,CU14606,CU14632,CU14704,CU14714,CU14784,CU14798,CU14853,CU14874,CU14887,CU14911,CU14912,CU14921,CU1494,CU14951,CU15002,CU15049,CU15061,CU15087,CU15131,CU15136,CU15165,CU15177,CU15325,CU15326,CU15343,CU15372,CU15411,CU15509,CU15786,CU15854,CU1590,CU1591,CU15988,CU161,CU1691,CU1732,CU1750,CU1872,CU1937,CU1941,CU1947,CU1965,CU2098,CU2107,CU2110,CU2134,CU2194,CU225,CU2361,CU2377,CU2394,CU2399,CU2473,CU2607,CU267,CU2685,CU2753,CU276,CU2885,CU293,CU2977,CU3006,CU3066,CU3134,CU3214,CU3237,CU3244,CU3269,CU3373,CU3379,CU3434,CU3592,CU3619,CU3636,CU3654,CU3801,CU3818,CU3850,CU3856,CU3894,CU3940,CU3942,CU396,CU4126,CU4152,CU4155,CU4224,CU4285,CU4299,CU4441,CU4476,CU4643,CU4645,CU4679,CU4701,CU4913,CU4955,CU5082,CU5091,CU5120,CU5282,CU5303,CU5318,CU5330,CU5376,CU5403,CU5473,CU5596,CU5599,CU5630,CU5655,CU5675,CU5758,CU5807,CU5870,CU5976,CU5992,CU6103,CU6165,CU6215,CU6234,CU6242,CU6327,CU6366,CU6380,CU6503,CU6560,CU6578,CU6614,CU6635,CU6668,CU67,CU6812,CU685,CU6950,CU6953,CU6954,CU7015,CU7169,CU7214,CU7294,CU7417,CU7502,CU7700,CU7799,CU7828,CU793,CU7943,CU7962,CU7973,CU8038,CU8076,CU8084,CU8091,CU8122,CU8144,CU8235,CU8259,CU8290,CU8296,CU8318,CU8340,CU8368,CU8369,CU8395,CU840,CU8402,CU8598,CU8599,CU8600,CU8647,CU8649,CU868,CU8687,CU8723,CU878,CU8867,CU8952,CU8976,CU9004,CU9108,CU9232,CU928,CU9383,CU9453,CU967,CU9726,CU9731,CU975,CU9790,CU9820,CU985,CU9868,CU99322730Yes(0.00000001.0000000)*これはどういうことかというと、顧客のプロファイルを分析する際に、データのプライマリキーであるCUSTOMER_IDを使ってしまったがために、「こういうCUSTOMER_IDの人は買う、こういうCUSTOMER_IDの人は買わない」という傾向抽出になってしまった状態です。これは完全に反則ですね。分析としては失敗です。
あまりにパターンが多い列は分析しても傾向を抽出し得ないので、分析対象から外した方がよいだろうと考えられます。したがってまずCUSTOMER_IDは除外する必要がありそうですが、他にも名前などパターンが多すぎる列がありますので便宜上1から7列目までをざくっと除外してみましょう。
>model=rpart(BUY_INSURANCE~.,data=customers[,-1:-7])>customers[,-1:-7]によって1-7列目を除外しているのがわかります。
これでもう一度modelを確認してみます。
>modeln=1015node),split,n,loss,yval,(yprob)*denotesterminalnode1)root1015273No(0.731034480.26896552)2)BANK_FUNDS<270.54297No(0.983682980.01631702)*3)BANK_FUNDS>=270.5586266No(0.546075090.45392491)6)CHECKING_AMOUNT>=15823546No(0.804255320.19574468)12)MONEY_MONTLY_OVERDRAWN<54.2618421No(0.885869570.11413043)*13)MONEY_MONTLY_OVERDRAWN>=54.265125No(0.509803920.49019608)26)CHECKING_AMOUNT>=1991285No(0.821428570.17857143)*27)CHECKING_AMOUNT<1991233Yes(0.130434780.86956522)*7)CHECKING_AMOUNT<158351131Yes(0.373219370.62678063)14)CREDIT_BALANCE>=999293No(0.896551720.10344828)*15)CREDIT_BALANCE<999322105Yes(0.326086960.67391304)30)MONEY_MONTLY_OVERDRAWN<53.83520392Yes(0.453201970.54679803)60)N_TRANS_WEB_BANK>=7339134No(0.626373630.37362637)120)AGE>=40408No(0.800000000.20000000)*121)AGE<405125Yes(0.490196080.50980392)242)SALARY<60515112No(0.818181820.18181818)*243)SALARY>=605154016Yes(0.400000000.60000000)486)T_AMOUNT_AUTOM_PAYMENTS>=325.52511No(0.560000000.44000000)972)MONEY_MONTLY_OVERDRAWN<53.43133No(0.769230770.23076923)*973)MONEY_MONTLY_OVERDRAWN>=53.43124Yes(0.333333330.66666667)*487)T_AMOUNT_AUTOM_PAYMENTS<325.5152Yes(0.133333330.86666667)*61)N_TRANS_WEB_BANK<73311235Yes(0.312500000.68750000)122)MONEY_MONTLY_OVERDRAWN<53.115239No(0.608695650.39130435)244)MONTHLY_CHECKS_WRITTEN>=5132No(0.846153850.15384615)*245)MONTHLY_CHECKS_WRITTEN<5103Yes(0.300000000.70000000)*123)MONEY_MONTLY_OVERDRAWN>=53.1158921Yes(0.235955060.76404494)246)T_AMOUNT_AUTOM_PAYMENTS>=615.52713No(0.518518520.48148148)492)N_TRANS_TELLER>=1.5111No(0.909090910.09090909)*493)N_TRANS_TELLER<1.5164Yes(0.250000000.75000000)*247)T_AMOUNT_AUTOM_PAYMENTS<615.5627Yes(0.112903230.88709677)*31)MONEY_MONTLY_OVERDRAWN>=53.83511913Yes(0.109243700.89075630)*>それっぽい感じになってきました。まずBANK_FUNDS(貯金)の額が270.5未満であれば98%の人が契約しない、という結果があります。BANK_FUNDSが270.5以上の人はさらに条件が分岐し、それぞれについて契約するかしないか、そのときの確率が算出されています。
もう少し結果をシンプルにするために、少しオプションを加えます。
controlオプションによって条件分岐の最大深度を4と設定して再実行してみます。
>model=rpart(BUY_INSURANCE~.,data=customers[,-1:-7],control=rpart.control(maxdepth=4))>>modeln=1015node),split,n,loss,yval,(yprob)*denotesterminalnode1)root1015273No(0.731034480.26896552)2)BANK_FUNDS<270.54297No(0.983682980.01631702)*3)BANK_FUNDS>=270.5586266No(0.546075090.45392491)6)CHECKING_AMOUNT>=15823546No(0.804255320.19574468)12)MONEY_MONTLY_OVERDRAWN<54.2618421No(0.885869570.11413043)*13)MONEY_MONTLY_OVERDRAWN>=54.265125No(0.509803920.49019608)26)CHECKING_AMOUNT>=1991285No(0.821428570.17857143)*27)CHECKING_AMOUNT<1991233Yes(0.130434780.86956522)*7)CHECKING_AMOUNT<158351131Yes(0.373219370.62678063)14)CREDIT_BALANCE>=999293No(0.896551720.10344828)*15)CREDIT_BALANCE<999322105Yes(0.326086960.67391304)*>rpart()関数のより詳しいリファレンスについてはhelp(rpart)でマニュアルを確認してみてください。
これでかなりシンプルに傾向が見えてきました。BANK_FUNDS、CHECKING_AMOUNT、MONEY_MONTHLY_OVERDRAWN、CREDIT_BALANCEあたりが重要な決定要因であると思われます。
同じ結果ですが、より視認性の高い形で分析結果を出力する方法があります。そのためのライブラリrpart.plotをinstall.packages()関数で追加インストールします。
>install.packages("rpart.plot")>インストールしたライブラリをロードします。
>library(rpart.plot)>rpart.plot()関数でmodelをのぞいてみます。
>rpart.plot(model,extra=4)>👁 スクリーンショット 2016-10-11 15.56.22.png
{kind=link}
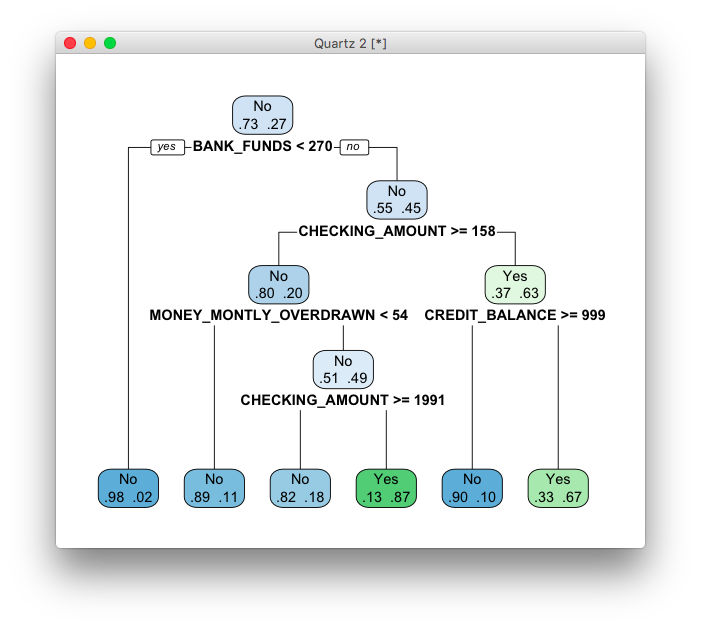{kind=link}
条件分岐がビジュアライズされ、傾向が読みやすくなりました。
分析対象の列の選定はかなりおおざっぱでしたが、データ分析の基本的な流れがカバーできました。
決定木で予測をおこなう
先ほどまでの手順で既存データから学習をおこない、保険商品を買う顧客にはどのような傾向があるのか(どの属性が重要な決定要因となっているのか)を知ることができました。同時にこの分析結果は予測モデルとして利用でき、営業がまだアプローチしていない見込み顧客について、成約可能性を予測することができます。
例えば3件ほどの見込み顧客データが手に入ったとします。下記CSVファイルにそのデータがありますのでダウンロードしてください。
https://dl.dropboxusercontent.com/u/149862/R_Bootcamp/sample_leads_for_rpart.csv
この3件の顧客レコードは見込み顧客なのでBUY_INSURANCEの列は未入力になっています。この値(買うのか、買わないのか)を予測します。
まず見込み顧客データをインポートします。
>leads=read.csv("sample_leads_for_rpart.csv")>そしてインポートした見込み顧客データの購入可能性をpredict()関数を使って予測します。predict()関数には第一引数に予測モデル、第二引数に予測対象のデータを与えます。
>prediction=predict(model,leads)NoYes10.98368300.0163170220.88586960.1141304330.32608700.67391304>3件の見込み顧客について、予測が出てきました。見込み顧客それぞれについて、契約しない可能性(No)、契約する可能性(Yes)が表示されています。この結果が正解だったかどうか、現時点では知る由はありませんが、この結果は確実に先ほどの決定木通りになっています。したがって結果を解釈する人間としてもなぜこういう結果になったのかが理解しやすい分析手法と言えます。
そして、実際のビジネスシーンではこの結果を頼りにアプローチする見込み顧客を絞り込むことができるでしょう。
ランダムフォレストでデータを分析する
さて、いよいよランダムフォレストでデータを分析します。
ランダムフォレストはデフォルトでは備わっていないアルゴリズムなのでinstall.packages()関数で追加インストールします。
>install.packages("randomForest")//出力は省略>インストールできたらライブラリをロードします。
>library(randomForest)>では早速分析を実行してみましょう。
randomForestもrpartと似た構文で実行できます。
>model=randomForest(BUY_INSURANCE~.,data=customers)randomForest.default(m,y,...)でエラー:Cannothandlecategoricalpredictorswithmorethan53categories.>どうやらエラーが出ています。
これはカテゴリー(factor)として保存されている列の値が54以上あることが原因です。
それだけ種類が多いfactor列は扱うことができませんというrandomForestパッケージの仕様です。ということで不要な列を除外した学習データを作ります。
まず不要な列を判断します。どの列がfactorとなっているかを確認します。
>sapply(customers,class)CUSTOMER_IDLASTFIRSTSTATEREGIONSEX"factor""factor""factor""factor""factor""factor"PROFESSIONBUY_INSURANCEAGEHAS_CHILDRENSALARYN_OF_DEPENDENTS"factor""factor""integer""integer""integer""integer"CAR_OWNERSHIPHOUSE_OWNERSHIPTIME_AS_CUSTOMERMARITAL_STATUSCREDIT_BALANCEBANK_FUNDS"integer""integer""integer""factor""integer""integer"CHECKING_AMOUNTMONEY_MONTLY_OVERDRAWNT_AMOUNT_AUTOM_PAYMENTSMONTHLY_CHECKS_WRITTENMORTGAGE_AMOUNTN_TRANS_ATM"integer""numeric""integer""integer""integer""integer"N_MORTGAGESN_TRANS_TELLERCREDIT_CARD_LIMITSN_TRANS_KIOSKN_TRANS_WEB_BANKLTV"integer""integer""integer""integer""integer""numeric"LTV_BIN"factor">customersのすべての列にclass()関数を適用してデータタイプを出力させました。sapply()は第一引数に指定されたデータフレームのすべての列に第二引数に指定された関数(ここではclass())を適用します。これでどの列がfactorとなっているのかを確認します。
次にsummary()関数でデータの統計を確認します。
*表示の都合上、age列までを掲載しています
>summary(customers)CUSTOMER_IDLASTFIRSTSTATEREGIONSEXPROFESSIONBUY_INSURANCEAGECU100:1JUDE:4BRYSON:4NY:343Midwest:220F:344Programmer/Developer:137No:742Min.:0.00CU10006:1VAL:4COYLE:4CA:235NorthEast:375M:671ITStaff:89Yes:2731stQu.:27.00CU10011:1ALVA:3HOGUE:4MI:168South:69Nurse:54Median:36.00CU10012:1BOYCE:3BRANCH:3FL:36Southwest:57Clerical:35Mean:38.19CU10020:1CALEB:3CASH:3DC:32West:294Notspecified:343rdQu.:48.00CU10025:1CAMERON:3DICKENS:3MN:26Cashier:32Max.:84.00(Other):1009(Other):995(Other):994(Other):175(Other):634>この結果を見て、factor列でかつその種類が54以上あるものは除外対象です。
今回の例だと、CUSTOMER_ID, LAST, FIRST, STATE, PROFESSIONは除外することになります。
ということでこれらの列を除外します。
まず除外する列の文字列ベクトルを作成します。
>exclude_cols=c("CUSTOMER_ID","LAST","FIRST","STATE","PROFESSION")>作成した除外用文字列ベクトルを利用して、学習データから不要な列を除外します。
>train=customers[!names(customers)%in%exclude_cols]>列名がexclude_colsに含まれなかったらtrainに学習データとして格納する、という形です。names()は対象データフレームの列名を列挙してくれる関数です。
不要な列が除外されているか確認します。
>names(train)[1]"REGION""SEX""BUY_INSURANCE""AGE""HAS_CHILDREN"[6]"SALARY""N_OF_DEPENDENTS""CAR_OWNERSHIP""HOUSE_OWNERSHIP""TIME_AS_CUSTOMER"[11]"MARITAL_STATUS""CREDIT_BALANCE""BANK_FUNDS""CHECKING_AMOUNT""MONEY_MONTLY_OVERDRAWN"[16]"T_AMOUNT_AUTOM_PAYMENTS""MONTHLY_CHECKS_WRITTEN""MORTGAGE_AMOUNT""N_TRANS_ATM""N_MORTGAGES"[21]"N_TRANS_TELLER""CREDIT_CARD_LIMITS""N_TRANS_KIOSK""N_TRANS_WEB_BANK""LTV"[26]"LTV_BIN">これでもう一度分析にかけてみましょう。dataに渡しているオブジェクトが今回はtrainになっていますので注意してください。
>model=randomForest(BUY_INSURANCE~.,data=train)>今度はエラーなくうまくいったようです。
分析がうまくいったら、作成した予測モデル(model)の精度をまず確認してみます。
randomForest()は与えられたデータフレームから学習データを自動的にサンプリング(ランダムに選択)して学習をおこないます。このとき、最終的に学習に使われなかったデータが残存するため、このデータを使って答え合わせをすることができます。その答え合わせの結果で簡易的に予測モデルの精度を確認することができるわけです。
modelをそのまま出力すると、答え合わせの結果と予測モデルの精度を確認できます。
>modelCall:randomForest(formula=BUY_INSURANCE~.,data=train)Typeofrandomforest:classificationNumberoftrees:500No.ofvariablestriedateachsplit:5OOBestimateoferrorrate:12.22%Confusionmatrix:NoYesclass.errorNo699430.05795148Yes811920.29670330>まず下記のOOB値:12.22%というのが今回作成した予測モデルから予測した値が答え合わせの結果間違っていた割合を示しています。
OOB estimate of error rate: 12.22%
逆に言えば、今回の予測モデルの精度は87.78%ということになります。
つまり、新規見込み顧客のデータが手に入った場合、その顧客が保険商品が買うかどうかを87.78%の精度で予測できるということになります。
また、今回の分析結果で、保険商品を買うかどうかを左右する要因は何かを知ることができます。
>importance(model)MeanDecreaseGiniREGION8.1488123SEX1.6906459AGE18.3249535HAS_CHILDREN2.4169660SALARY16.5422671N_OF_DEPENDENTS6.6106234CAR_OWNERSHIP0.5361535HOUSE_OWNERSHIP1.9058231TIME_AS_CUSTOMER5.8898506MARITAL_STATUS5.7819016CREDIT_BALANCE9.2801915BANK_FUNDS63.0864129CHECKING_AMOUNT37.1475490MONEY_MONTLY_OVERDRAWN51.8547840T_AMOUNT_AUTOM_PAYMENTS38.6544032MONTHLY_CHECKS_WRITTEN17.4563339MORTGAGE_AMOUNT14.4794974N_TRANS_ATM27.0366299N_MORTGAGES2.1569260N_TRANS_TELLER15.7906429CREDIT_CARD_LIMITS9.0071569N_TRANS_KIOSK7.3696716N_TRANS_WEB_BANK16.5318104LTV16.9078723LTV_BIN3.5432534>importance()は分析した学習データの内、各列の影響度を教えてくれます。
MeanDecreaseGiniの値が大きいほど、影響度が大きいということを示しています。今回の例ではBANK_FUNDSが63.0864129で最も影響が大きい要素であることがわかります。
結果は同じですが、より視覚に直感的に表示するのではればvarImpPlot()関数を利用できます。
>varImpPlot(mode)👁 スクリーンショット 2016-09-01 14.00.51.png
{kind=link}
{kind=link}
ランダムフォレストで予測をおこなう
決定木と同じく、ランダムフォレストでも営業がまだアプローチしていない見込み顧客について、成約可能性を予測することができます。
下記の見込み顧客データを利用しますのでダウンロードしてください。
https://dl.dropboxusercontent.com/u/149862/R_Bootcamp/sample_leads_for_randomForest.csv
まず見込み顧客データをインポートします。
>leads=read.csv("sample_leads_for_randomForest.csv")>そしてインポートした見込み顧客データの購入可能性をpredict()関数を使って予測します。
>prediction=predict(model,leads)predict.randomForest(model,leads)でエラー:Typeofpredictorsinnewdatadonotmatchthatofthetrainingdata.predict()関数には第一引数に予測モデル、第二引数に予測対象のデータを与えます。
しかしここでエラーが出ています。どうやら予測モデルの元になった学習データと、leadsでタイプが違うデータがある、と怒っているようです。
実際にclass()関数で確認してみます。
>class(leads$BUY_INSURANCE)[1]"logical">class(train$BUY_INSURANCE)[1]"factor">leadsの方はlogical、trainの方はfactorになっているので確かに違うようです。
このように予測対象のデータは、学習データと同じ構造になっていないとエラーになります。そして、上記のエラーを修正しても他の列についてもいくつか相違点があるので、予測対象のデータを一つ一つ学習データと同じ構造に合わせるのはそこそこ面倒な作業です。
もっとも簡単なやりかたとして、おおもとのデータ(customers)にleadsを結合してあげることですべての構造を合わせることができます。
ただしleadsのデータにcustomersにはないfactorの値が含まれていたりするとそれはそれで構造が変わってしまうのですが。
ということでrbind()関数を使ってleadsデータフレームをcustomersデータフレームの末尾に追加します。
>customers_and_leads=rbind(customers,leads)>結合したデータの見込み顧客データについて、再度予測を実行します。
>predition=predict(model,customers_and_leads[1016:1018,])>今度はうまく実行できました。結果をみてみましょう。
>predition101610171018NoNoYesLevels:NoYes>3件の見込み顧客について、予測が出てきました。この結果が正解だったかどうか、現時点では知る由はありませんが、この結果を頼りにアプローチする見込み顧客を絞り込むことができるでしょう。
まとめ
これでRをインストールするところから予測モデルを作成するところまで、一通り操作することができました。実際にはランダムフォレストの精度をより高めるためにいくつかのチューニングをおこなうことが一般的ですが、それはまた別の記事でカバーしたいと思います。
参考資料
Register as a new user and use Qiita more conveniently
- You get articles that match your needs
- You can efficiently read back useful information
- You can use dark theme