 |
VOOZH | about |
|
VOOZH | about |
We’re so glad you’re here. You can expect all the best TNS content to arrive Monday through Friday to keep you on top of the news and at the top of your game.
Check your inbox for a confirmation email where you can adjust your preferences and even join additional groups.
Follow TNS on your favorite social media networks.
Become a TNS follower on LinkedIn.
Check out the latest featured and trending stories while you wait for your first TNS newsletter.
In computer science, scheduling refers to a method by which work specified by some means is assigned to resources that are capable of completing that work. It is an age-old problem that existed since the time of introduction of IBM S/360 in the 1960s.
Scheduling becomes essential whenever there is a job that can potentially get fulfilled by a set of resources. In the context of an OS, the job could be a simple program while the resource could be a CPU core. Similarly, a scheduler within the OS could be responsible for associating lines of code to a thread or a semaphore.
Distributed computing expanded the realm of schedulers from internal processes and threads to a cluster of physical machines. During the 90s, distributed platforms such as CORBA, DCOM, and J2EE tackled the challenge of scheduling components within a cluster of application servers.
More recently, IaaS control planes such as Amazon EC2, Azure Fabric, and OpenStack Nova dealt with scheduling virtual machines within hypervisors running on physical hosts. Each VM had to be placed on an appropriate host based on the requested resources.
Big Data workloads based on Apache Hadoop and MapReduce algorithms heavily relied on proven scheduling algorithms. HDFS, the file system of Hadoop ensured that all the nodes of a cluster have access to the dataset. The architecture squarely focused on reliability and availability of resources.
PaaS implementations such as Cloud Foundry and Heroku have sophisticated placement logic to schedule services in isolated environments. Each service is packaged and deployed into an execution environment running within a VM or a physical host.
The rise of containers forced the industry to revisit the design of resource schedulers. Simplicity and scalability became key considerations for the new schedulers. Traditional application servers dealt with a handful of servers while the worker nodes of container management platforms can be anywhere from one to a few thousand.
Kubernetes and Mesosphere are the modern incarnations of resource scheduler. Both are designed to abstract the underlying infrastructure making the scheduling task transparent to users.
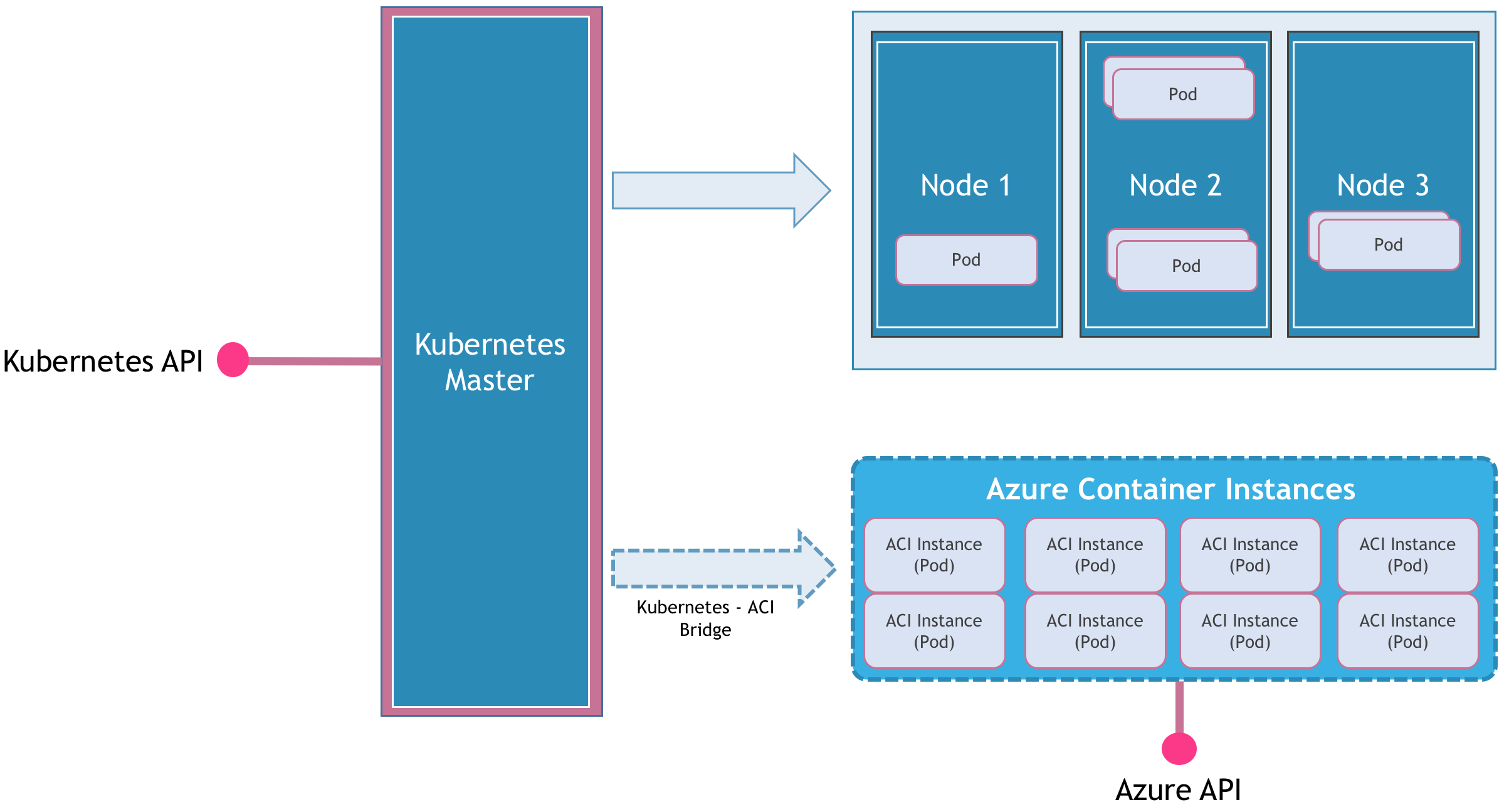
Kubernetes scheduler is one of the critical components of the platform. It runs on the master nodes working closely with the API server and controller. The scheduler is responsible for matchmaking — a pod with a node. You can get a thorough overview of in this article.
The scheduler determines an appropriate node for the pod based on multiple factors such as available resources. It is also possible to through node affinity where a pod requests for a node with specific characteristics. For example, a stateful pod running high I/O database may request the scheduler for a node with an SSD storage backend. It is also possible to ensure that a set of pods are placed on the same node to avoid latency. This is pod affinity. Kubernetes also supports custom schedulers where the placement logic is completely driven by a third party scheduler.
The best thing about Kubernetes scheduler is the simplicity. Most of the above-described placement strategies are very simple to implement. It just takes a set of labels and annotations appropriately included or excluded within pods and nodes. A simple key/value pair on a set of nodes and pods can deliver a sophisticated placement strategy.
Kubernetes is emerging as one of the best resource schedulers of our times. The powerful scheduler, which is also simple and extensible enables us to solve many problems that existed in traditional distributed systems.
Kubernetes is fast becoming the preferred control plane for scheduling and managing jobs in highly distributed environments. These jobs may include deploying virtual machines on physical hosts, placing containers in edge devices, or even extending the control plane to other schedulers such as serverless environments.
, a virtual machine management add-on for Kubernetes, is aimed at allowing users to run VMs right alongside containers in their Kubernetes or OpenShift clusters. It extends Kubernetes by adding resource types for VMs and sets of VMs through Kubernetes’ (CRD) API. KubeVirt VMs run within regular Kubernetes pods, where they have access to standard pod networking and storage, and can be managed using standard Kubernetes tools such as kubectl.
The project from Mirantis makes it possible to run VMs on Kubernetes clusters as if they were plain pods. It enables operators to use standard kubectl commands to manage VMs, and bringing them onto the cluster network as first class citizens. With Virtlet, it is possible to build higher-level Kubernetes objects including deployments, statefulsets or daemonSets.
Microsoft’s project is the most interesting scheduler leveraging Kubernetes. The Virtual Kubelet is an agent that runs in an external environment which is registered as a node within Kubernetes cluster. The agent creates a node resource through the Kubernetes API. By leveraging the concepts of , it schedules pods in an external environment by calling its native API.
👁 Image
Virtual Kubelet works with , , and control plane.
Refer to my earlier articles for a detailed walkthrough of the and of Virtual Kubelet.
The projects discussed above are just the tip of the iceberg. With Kubernetes becoming the foundation for modern infrastructure, it is gearing up to run a variety of workloads including traditional line-of-business applications such as ERP and CRM.
Application vendors are going to heavily rely on two emerging capabilities of Kubernetes – Custom Schedulers and Custom Resource Definitions (CRD).
As discussed earlier, custom schedulers in Kubernetes lets developers define custom scheduling logic. A pod’s declaration may include the custom scheduler’s name hinting the control plane to bypass the default scheduler. This is a powerful mechanism to control the placement of pods within the cluster.
, a cloud-native storage company exploited the power of custom scheduler to create (STorage Orchestrator Runtime for Kubernetes). It ensures that stateful pods are always placed on the nodes that has Portworx driver and storage. This is helpful in achieving high availability of database workloads deployed as containers.
in Kubernetes extend the simplicity and power of object lifecycle management to custom types. A custom resource is an object that extends the Kubernetes API or allows developers to introduce their own API into a project or a cluster. A custom resource definition (CRD) file defines custom object kind that lets the API Server handle the entire lifecycle. Deploying a CRD into the cluster causes the Kubernetes API server to begin serving the specified custom resource.
Once a CRD is created, operators can use kubectl or third-party tools to manage the lifecycle of a 3rd party resource like the way they deal with pods and deployments in Kubernetes. ISVs may package and deploy their software as a set of CRDs.
The extensibility of Kubernetes is turning it into a universal scheduler and management tool.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}