 |
VOOZH | about |
|
VOOZH | about |
We’re so glad you’re here. You can expect all the best TNS content to arrive Monday through Friday to keep you on top of the news and at the top of your game.
Check your inbox for a confirmation email where you can adjust your preferences and even join additional groups.
Follow TNS on your favorite social media networks.
Become a TNS follower on LinkedIn.
Check out the latest featured and trending stories while you wait for your first TNS newsletter.
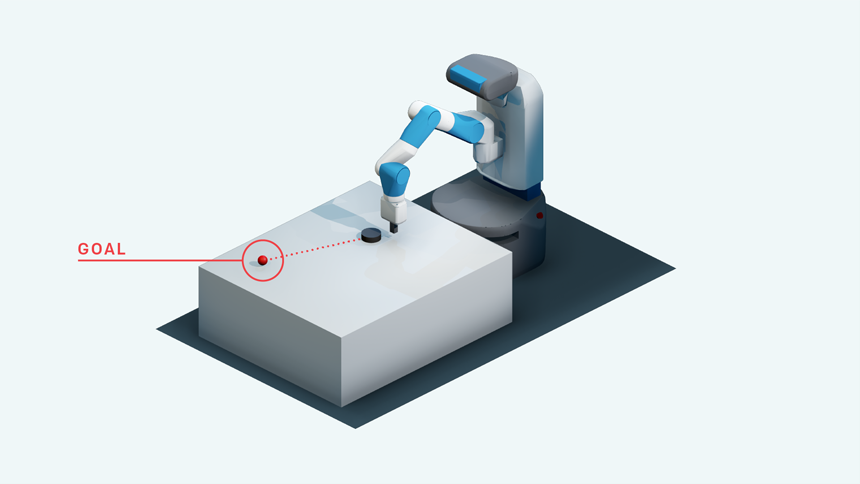
One key trait of humans and many other animals is the ability to learn from mistakes. When confronted with a goal to achieve or a specific skill or task to master, it often takes us many attempts before we are able to succeed at something — or at least, perform it well enough. In going through that process of repeated failures, we learn the various ways of how not to do something. Each time we fail, we learn something new that may help us finally do it correctly, which in hindsight, allows us to see that failure is necessary for success.
While this trait of learning from hindsight comes naturally for humans, that’s not necessarily the case for robots. The closest analogy we might have in artificial intelligence models is reinforcement learning, where machines are tasked with solving some kind of problem, and “earn” rewards of different magnitudes, depending on how close it gets to solving the problem. However, engineering this method of reward-dependent machine learning can get complicated, and isn’t always easily translated into the real world, and can actually discourage an AI agent from exploration.
Hoping to tackle this conundrum while developing a simpler way for machines to learn from their mistakes, San Francisco-based AI research company OpenAI recently released an open source algorithm called Hindsight Experience Replay (HER) — part of a larger release of simulated robotics environments intended for AI research development. Here is HER briefly explained:
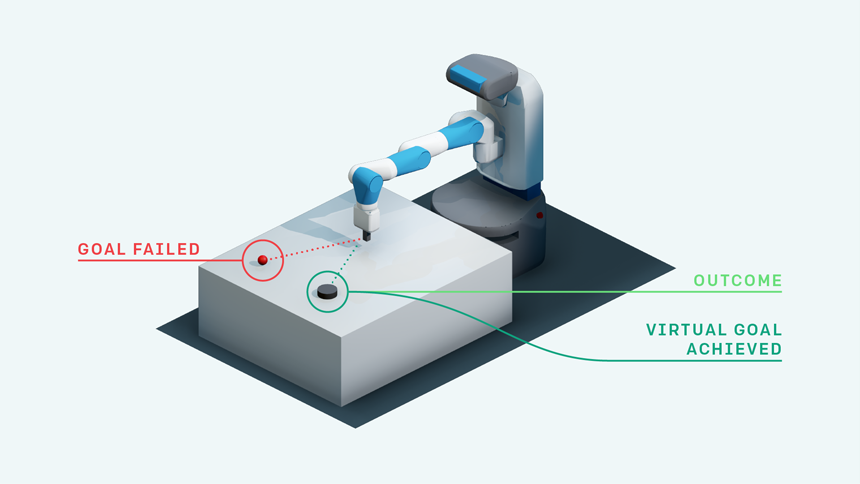
According to the researchers, the idea here is to get machines to learn from their failures in a way that is more akin to humans. “The key insight that HER formalizes is what humans do intuitively: Even though we have not succeeded at a specific goal, we have at least achieved a different one,” wrote the researchers in a blog post. “So why not just pretend that we wanted to achieve this goal to begin with, instead of the one that we set out to achieve originally?”
The HER algorithm achieves this by using what is called “sparse and binary” rewards, which only provide an indication to the agent that either it has failed or succeeded. In contrast, the “dense,” “shaped” rewards used in conventional reinforcement learning tip agents off as to whether they are getting “close,” “closer,” “much closer,” or “very close” to hitting their goal. Such so-called dense rewards can speed up the learning process, but the drawback is that these dense rewards often don’t contain much of a learning signal for the agent to learn from, and can be difficult to design and implement for real-world applications.
In contrast, with HER, even if an AI agent isn’t successful at performing a task, it still receives a sparse reward to encourage it further. In addition, HER creates a “multi-goal” reinforcement learning framework by reframing each failed attempt as a success, altering the goal slightly each time so that there is a learning signal to exploit, while still keeping the overall objective in mind.
“By doing this substitution, the reinforcement learning algorithm can obtain a learning signal since it has achieved some goal; even if it wasn’t the one that you meant to achieve originally,” wrote the team. “If you repeat this process, you will eventually learn how to achieve arbitrary goals, including the goals that you really want to achieve.”
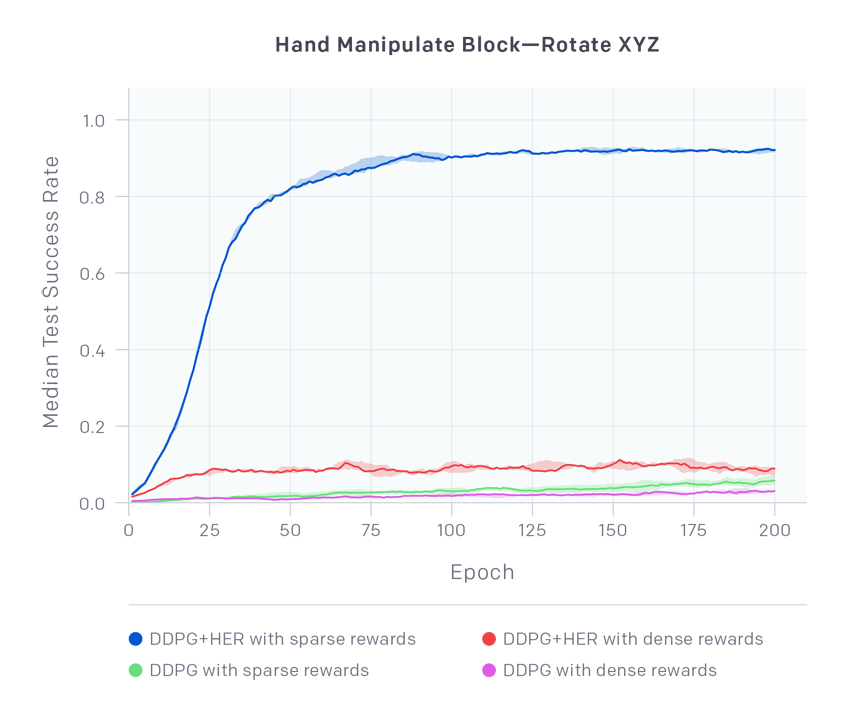
The team tested out the HER algorithm using simulated environments based on existing hardware robots, and how they performed in various manipulation tasks such as pushing, sliding, and pick-and-place. The algorithm was then transferred from a simulated environment to a real robot arm. Watch how the addition of HER boosts the relative success rate of solving these tasks, compared to an unmodified deep reinforcement learning model:
In relation to the other reinforcement learning techniques in the experiment, the team’s comparisons revealed that HER performed significantly better in goal-based environments where the AI agent might not achieve the initial target early on. However, unlike other reinforcement learning techniques, with HER the agent is able to learn something new in hindsight, after the completion of each attempt.
The use of sparse rewards seems to increase the rate of success as well, as agents are not penalized by exploratory behaviors that aren’t in service of the solving the original task. Sparse rewards are also simpler to design and put into action and don’t require more in-depth knowledge of the domain where the learning is taking place — which mimics more closely how learning is done in the real world. These are fascinating findings, possibly the first to show that complex manipulation behaviors can be learned using only simple, binary rewards, and are yet another step toward creating intelligent machines that can learn like humans.
Images: OpenAI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}