
{kind=link}
Decision Trees are a non-parametric supervised learning method, capable of finding complex nonlinear relationships in the data. They can perform both classification and regression tasks. But in this article, we only focus on decision trees with a regression task. For this, the equivalent Scikit-learn class is DecisionTreeRegressor.
We will start by discussing how to train, visualize and make predictions with Decision Trees for a regression task. We will also discuss how to regularize hyperparameters in decision trees. This will avoid the problem of overfitting. Finally, we will discuss some of the advantages and disadvantages of Decision Trees.
Code convention
We use the following code convention to import the necessary libraries and set the plot style.
Target audience
I assume that you have a basic understanding of the terminology used in the decision tree and how it works behind the scenes. In this tutorial, more emphasis is given for the model hyperparameter tuning techniques such as k-fold cross-validation.
Problem statement
We intend to build a model for the non-linear features, Longitude and MedHouseVal (Median house value) in the popular California housing dataset (cali_housing.csv).
Let’s see the first few rows of the dataset.
{kind=link}
This dataset has 20640 observations!
Visualize data
To see the relationship between the above mentioned two features, we create the following scatterplot using seaborn.
{kind=link}
As you can see in the scatterplot, there is a complex non-linear relationship between the two features. Decision tree regression is a powerful model capable of finding this kind of complex non-linear relationships in the data.
Build the model
Let’s train our model using the Scikit-learn DecisionTreeRegressor class.
Let’s visualize our model.
{kind=link}
We can visualize the tree diagram of this model using Graphviz.
{kind=link}
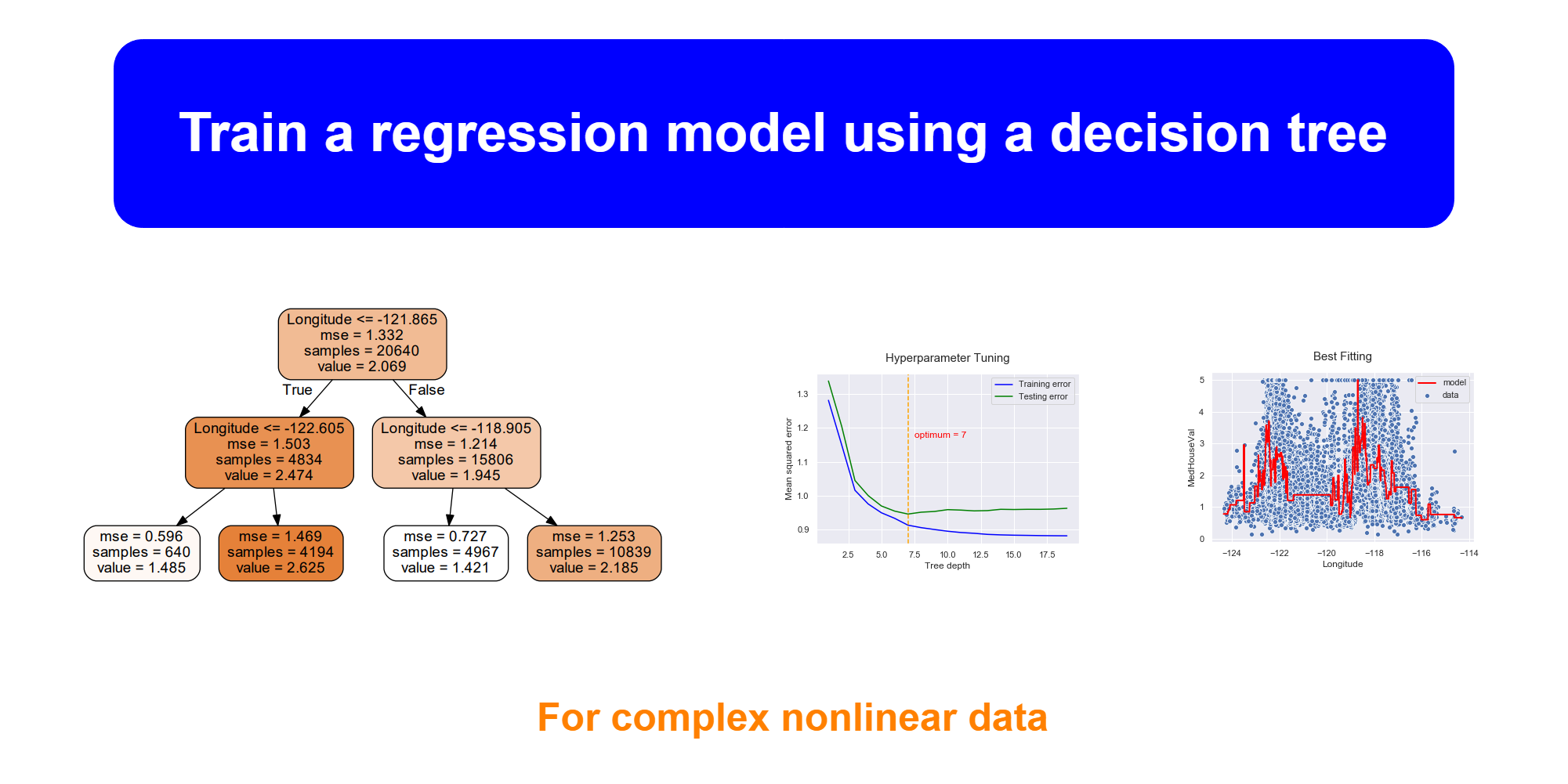
There are 4 leaf nodes in our tree. This is because we set max_depth=2. The number of leaf nodes is equivalent to 2^max_depth. The hyperparameter max_depth controls the complexity of branching.
In this case where max_depth=2, the model does not fit the training data very well. This is called the problem of underfitting.
Let’s create a different model with max_depth=15. By repeating the same steps, we can create the following model.
{kind=link}
Here we cannot visualize the tree diagram because it has 32768 (2¹⁵) leaf nodes! In this case where max_depth=15, the model fits the training data very well but it fails to generalize for new input data. This is called the problem of overfitting. Here the model has adapted to the noise of the data and it tries to memorize the data rather than learning any kind of pattern.
So, when we create the best model, we should avoid both underfitting and overfitting conditions.
So, what is the best value for the hyperparameter max_depth? Finding out the optimum value (not too small or too large) for max_depth is called hyperparameter tuning.
Hyperparameter tuning for decision tree regression
There are mainly two methods.
- Using Scikit-learn train_test_split() function
- Using k-fold cross-validation
Using Scikit-learn train_test_split() function
This is a very simple method to implement, but a very efficient method. All you need to do is to split the original dataset into two parts called train set and test set. We can easily do that using the Scikit-learn _train_test_split() function. The inputs are the feature matrix – X and the target vector – y. We usually withhold about 10%-30% data for the testing. The hyperparameter random_state_ accepts an integer. By specifying this, we can ensure the same split across different executions.
Then we train the model using X_train, y_train and test it using X_test, y_test. This is done for different values of _max_depth_ hyperparameter ranging from 1 to 20 and plot the testing error with the training error.
{kind=link}
At the point of tree depth = 7, the testing error begins to increase although the training error decreases continuously. From this plot, we can confirm that the optimum value for _max_depth_ hyperparameter is 7.
Using k-fold cross-validation
A more promising way to tune the model hyperparameter is to use the k-fold cross-validation. By using this method, you can tune more than 1 hyperparameter simultaneously. Here, training proceeds on the training set, after which evaluation is done on the validation set and the final evaluation can be done on the test set. However, partitioning the original dataset into 3 sets (train, validation and test) drastically reduces the available data for the training process.
As a solution, we use a procedure called k-fold cross-validation where k is the number of folds (which is usually 5 or 10). In k-fold cross-validation,
- We first divide the original dataset into the train set and test set using train_test_split() function.
- The train set is further divided into k-number of folds.
- The model is trained using k−1 of the folds and validated on the remaining fold.
- The process is done k times and the performance measure is reported at each execution. Then it takes the average.
- After finding the parameters, the final evaluation is done on the test set.
The following diagram illustrates the k-fold cross-validation procedure.
{kind=link}
Tuning hyperparameters can be done using the Grid Search method along with k-fold cross-validation. The equivalent Scikit-learn function is GridSearchCV. It finds all the hyperparameter combinations for a specified k number of folds.
Imagine that you want to find the best combination from all the hyperparameter combinations for the following two hyperparameters in DecisionTreeRegressor.
- max_depth: 1–10 (10 different values)
- min_samples_split: 10, 20, 30, 40, 50 (5 different values)
The following diagram shows the hyperparameter space. If you take one point (one combination), the GridSearchCV function searches that combination and train the model using those values along with k-fold cross-validation. Likewise, it searches all the combinations (here 10 x 5= 50!). So, it executes 50 x k times!
{kind=link}
{kind=link}
Now, we can create the best model using these optimum values. It avoids both overfitting and underfitting conditions.
{kind=link}
Advantages of decision trees
- Do not require feature scaling
- Can be used for nonlinear data
- Non-parametric: Very few underlying assumptions in data
- Can be used for both regression and classification
- Easy to visualize
- Easy to interpret
Disadvantages of decision trees
- Decision tree training is computationally expensive, especially when tuning model hyperparameter via k-fold cross-validation.
- A small change in the data can cause a large change in the structure of the decision tree.
This tutorial was designed and created by Rukshan Pramoditha, the Author of Data Science 365 Blog.
Technologies used in this tutorial
- Python (High-level programming language)
- numPy (Numerical Python library)
- pandas (Python data analysis and manipulation library)
- matplotlib (Python data visualization library)
- seaborn (Python advanced data visualization library)
- Scikit-learn (Python machine learning library)
- Jupyter Notebook (Integrated Development Environment)
Machine learning used in this tutorial
- Decision tree regression
2020–10–26
Share This Article
Towards Data Science is a community publication. Submit your insights to reach our global audience and earn through the TDS Author Payment Program.
Write for TDS{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}