
Word2Vec Explained
Explaining the Intuition of Word2Vec & Implementing it in Python
{kind=link}
Table of Contents
- Introduction
- What is a Word Embedding?
- Word2Vec Architecture
- CBOW (Continuous Bag of Words) Model
- Continuous Skip-Gram Model
- Implementation
- Data
- Requirements
- Import Data
- Preprocess Data
- Embed
- PCA on Embeddings
- Concluding Remarks
- Resources
Introduction
Word2Vec is a recent breakthrough in the world of NLP. Tomas Mikolov, a Czech computer scientist and currently a researcher at CIIRC ( Czech Institute of Informatics, Robotics and Cybernetics), was one of the leading contributors to the research and implementation of word2vec. Word embeddings are an integral part of solving many problems in NLP. They depict how humans understand language to a machine. You can imagine them as a vectorized representation of text. Word2Vec, a standard method of generating word embeddings, has a variety of applications, such as text similarity, recommendation systems, sentiment analysis, etc.
What is a Word Embedding?
Before we get into word2vec, let’s establish an understanding of what word embeddings are. This is important to know because the overall result and output of word2vec will be embeddings associated with each unique word passed through the algorithm.
Word embeddings are a technique where individual words are transformed into a numerical representation of the word (a vector). Where each word is mapped to one vector, this vector is then learned in a way which resembles a neural network. The vectors try to capture various characteristics of that word with regard to the overall text. These characteristics can include the semantic relationship of the word, definitions, context, etc. With these numerical representations, you can do many things, like identify similarities or dissimilarities between words.
These are integral inputs to various aspects of machine learning. A machine cannot process text in its raw form; thus, converting the text into an embedding will allow users to feed the embedding to classic machine learning models. The simplest embedding would be a one-hot encoding of text data where each vector would be mapped to a category.
For example: have = [1, 0, 0, 0, 0, 0, ... 0]
a = [0, 1, 0, 0, 0, 0, ... 0]
good = [0, 0, 1, 0, 0, 0, ... 0]
day = [0, 0, 0, 1, 0, 0, ... 0] ...However, there are multiple limitations of simple embeddings such as this, as they do not capture characteristics of the word, and they can be quite large depending on the size of the corpus.
Word2Vec Architecture
The effectiveness of Word2Vec comes from its ability to group together vectors of similar words. Given a large enough dataset, Word2Vec can make strong estimates about a word’s meaning based on its occurrences in the text. These estimates yield word associations with other words in the corpus. For example, words like "King" and "Queen" would be very similar to one another. When conducting algebraic operations on word embeddings, you can find a close approximation of word similarities. For example, the 2-dimensional embedding vector of "king" – the 2-dimensional embedding vector of "man" + the 2-dimensional embedding vector of "woman" yielded a vector which is very close to the embedding vector of "queen". Note that the values below were chosen arbitrarily.
King - Man + Woman = Queen
[5,3] - [2,1] + [3, 2] = [6,4] {kind=link}
There are two main architectures which yield the success of word2vec. The skip-gram and CBOW architectures.
CBOW (Continuous Bag of Words)
This architecture is very similar to a feed-forward neural network. This model architecture essentially tries to predict a target word from a list of context words. The intuition behind this model is quite simple: given a phrase "Have a great day" , we will choose our target word to be "a" and our context words to be ["have", "great", "day"]. What this model will do is take the distributed representations of the context words to try and predict the target word.
{kind=link}
Continuous Skip-Gram Model
The skip-gram model is a simple neural network with one hidden layer trained to predict the probability of a given word being present when an input word is present. Intuitively, the skip-gram model is the opposite of the CBOW model. In this architecture, it takes the current word as input and tries to accurately predict the words before and after this current word. This model essentially tries to learn and predict the context words around the specified input word. Based on experiments assessing the accuracy of this model, it was found that the prediction quality improves given a large range of word vectors. However, it also increases the computational complexity. The process can be described visually, as seen below.
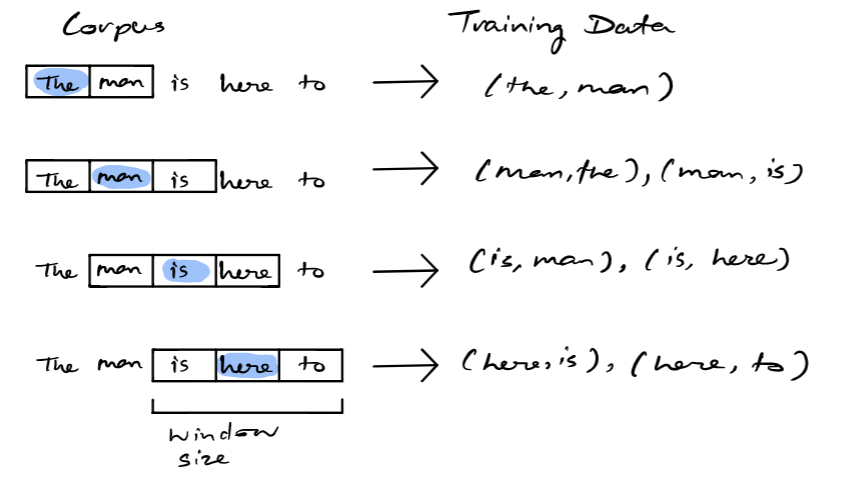{kind=link}
As seen above, given some corpus of text, a target word is selected over some rolling window. The training data consists of pairwise combinations of that target word and all other words in the window. This is the resulting training data for the neural network. Once the model is trained, we can essentially yield a probability of a word being a context word for a given target. The following image below represents the architecture of the neural network for the skip-gram model.
{kind=link}
A corpus can be represented as a vector of size N, where each element in N corresponds to a word in the corpus. During the training process, we have a pair of target and context words. The input array will have 0 in all elements except for the target word. The target word will be equal to 1. The hidden layer will learn the embedding representation of each word, yielding a d-dimensional embedding space. The output layer is a dense layer with a softmax activation function. The output layer will yield a vector of the same size as the input. Each element in the vector will consist of a probability. This probability indicates the similarity between the target word and the associated word in the corpus.
For a more detailed overview of both these models, I highly recommend reading the original paper which outlined these results here.
Implementation
I’ll be showing how to use word2vec to generate word embeddings and use those embeddings for finding similar words and visualization of embeddings through PCA.
Data
For the purposes of this tutorial, we’ll be working with the Shakespeare dataset. You can find the file I used for this tutorial here; it includes all the lines Shakespeare has written for his plays.
Requirements
nltk==3.6.1
node2vec==0.4.3
pandas==1.2.4
matplotlib==3.3.4
gensim==4.0.1
scikit-learn==0.24.1Note: Since we’re working with NLTK, you might need to download the following corpus for the rest of the tutorial to work. This can easily be done by the following commands :
import nltk
nltk.download('stopwords')
nltk.download('punkt')Import Data
Note: Change the PATH variable to the path of the data you’re working with.
Preprocess Data
Stopword Filtering Note
- Be aware that the stopwords removed from these lines are of modern vocabulary. The application & data has a high importance to the type of preprocessing tactics necessary for cleaning of words.
- In our scenario, words like "you" or "yourself" would be present in the stopwords and eliminated from the lines, however, since this is Shakespeare text data, these types of words would not be used. Instead "thou" or "thyself" might be helpful to remove. Stay keen on these types of miniature changes because they make a drastic difference in the performance of a good model versus a poor one.
- For the purposes of this example, I won’t be going into extreme details in identifying stopwords from a different century, but be aware that you should.
Embed
{kind=link}
PCA on Embeddings
{kind=link}
Tensorflow has made a very beautiful, intuitive and user-friendly representation of the word2vec model. I highly recommend you to explore it as it allows you to interact with the results of word2vec. The link is below.
Embedding projector – visualization of high-dimensional data
Concluding Remarks
Word embeddings are an essential part of solving many problems in NLP, it depicts how humans understand language to a machine. Given a large corpus of text, word2vec produces an embedding vector associated with each word in the corpus. These embeddings are structured such that words with similar characteristics are in close proximity to one another. CBOW (continuous bag of words) and the skip-gram model are the two main architectures associated with word2vec. Given an input word, skip-gram will try to predict the words in context to the input, whereas the CBOW model will take a variety of words and try to predict the missing one.
I’ve also written about node2vec, which uses word2vec to generate node embeddings given a network. You can read about it here.
Resources
- https://arxiv.org/pdf/1301.3781.pdf
- https://www.kdnuggets.com/2019/02/word-embeddings-nlp-applications.html
- https://wiki.pathmind.com/word2vec
- https://projector.tensorflow.org/
If you enjoyed reading this article, please consider following me for upcoming articles explaining other data science materials and those materials (like word2vec) to solve relevant problems in different areas of data science. Here are some other articles I’ve written that I think you might enjoy.
Bayesian A/B Testing Explained
Share This Article
Towards Data Science is a community publication. Submit your insights to reach our global audience and earn through the TDS Author Payment Program.
Write for TDS{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}