
eBook – Guide Spring Cloud – NPI EA (cat=Spring Cloud)
{kind=link}
eBook – Mockito – NPI EA (tag = Mockito)
👁 announcement - icon
Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
eBook – Java Concurrency – NPI EA (cat=Java Concurrency)
👁 announcement - icon
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
eBook – Reactive – NPI EA (cat=Reactive)
👁 announcement - icon
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
eBook – Java Streams – NPI EA (cat=Java Streams)
👁 announcement - icon
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
eBook – Jackson – NPI EA (cat=Jackson)
eBook – HTTP Client – NPI EA (cat=Http Client-Side)
eBook – Maven – NPI EA (cat = Maven)
eBook – Persistence – NPI EA (cat=Persistence)
eBook – RwS – NPI EA (cat=Spring MVC)
Course – LS – NPI EA (cat=Jackson)
👁 announcement - icon
Get started with Spring and Spring Boot, through the Learn Spring course:
>> LEARN SPRINGCourse – RWSB – NPI EA (cat=REST)
👁 announcement - icon
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Course – LSS – NPI EA (cat=Spring Security)
👁 announcement - icon
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Course – LSD – NPI EA (tag=Spring Data JPA)
👁 announcement - icon
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Partner – Moderne – NPI EA (cat=Spring Boot)
👁 announcement - icon
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Course – LJB – NPI EA (cat = Core Java)
1. Overview
In this article, we’ll focus on how to list all objects in an S3 bucket using Java. We’ll discuss the usage of the AWS SDK for Java to interact with S3 and look at examples for different use cases.
The emphasis will be on using the AWS SDK for Java V2, noted for its several advancements over the preceding version, like enhanced performance, non-blocking I/O, and a user-friendly API design.
2. Prerequisites
To list all objects in an S3 bucket, we can utilize the S3Client class provided by the AWS SDK for Java.
First, let’s create a new Java project and add the following Maven dependency to our pom.xml file:
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<version>2.24.9</version>
</dependency>For the examples in this article, we’ll go with version 2.20.52. To view the latest version, we can check the Maven Repository.
We also need an AWS account set up, install AWS CLI, and configure it with our AWS credentials (AWS_ACCESS_KEY_ID and AWS_SECERET_ACCESS_KEY) to be able to access the AWS resources programmatically. We can find all the steps to accomplish this in the AWS documentation.
Finally, we need to create an AWS S3 bucket and upload some files. As we can see in the following image, for our examples, we’ve created a bucket called baeldung-tutorials-s3 and uploaded 1060 files to it:
👁 S3 Bucket Objects{kind=link}
{kind=link}
3. List Objects From an S3 Bucket
Let’s use the AWS SDK for Java V2 and create a method for reading objects from a bucket:
String AWS_BUCKET = "baeldung-tutorial-s3";
Region AWS_REGION = Region.EU_CENTRAL_1;void listObjectsInBucket() {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.build();
ListObjectsV2Response listObjectsV2Response = s3Client.listObjectsV2(listObjectsV2Request);
List<S3Object> contents = listObjectsV2Response.contents();
System.out.println("Number of objects in the bucket: " + contents.stream().count());
contents.stream().forEach(System.out::println);
s3Client.close();
}To list objects from an AWS S3 bucket, we first need to create a ListObjectsV2Request instance, specifying the bucket name. Then, we call the listObjectsV2 method on the s3Client object, passing the request as an argument. This method returns a ListObjectsV2Response, containing information about the objects in the bucket.
Finally, we use the contents() method to access the S3 object lists and write the number of objects retrieved as an output. We also defined two static attributes for the bucket name and the corresponding AWS region.
After we execute the method, we get the following result:
Number of objects in the bucket: 1000
S3Object(Key=file_0.txt, LastModified=2023-06-06T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-06-06T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-06-06T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
S3Object(Key=file_100.txt, LastModified=2023-06-06T11:35:15Z, ETag="b99834bc19bbad24580b3adfa04fb947", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1000.txt, LastModified=2023-04-29T18:54:31Z, ETag="47ed733b8d10be225eceba344d533586", Size=1, StorageClass=STANDARD)
[...]As we can see, we don’t get all of our uploaded objects back as a result.
It’s important to note that this solution is designed to return up to 1000 objects only. If the bucket contains more than 1000 objects, we must implement pagination using the nextContinuationToken() method in the ListObjectsV2Response object.
4. Pagination With Continuation Token
In case our AWS S3 bucket contains more than 1000 objects, we need to implement pagination using the nextContinuationToken() method.
Let’s look at an example demonstrating how to handle this scenario:
void listAllObjectsInBucket() {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
String nextContinuationToken = null;
long totalObjects = 0;
do {
ListObjectsV2Request.Builder requestBuilder = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.continuationToken(nextContinuationToken);
ListObjectsV2Response response = s3Client.listObjectsV2(requestBuilder.build());
nextContinuationToken = response.nextContinuationToken();
totalObjects += response.contents().stream()
.peek(System.out::println)
.reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);
} while (nextContinuationToken != null);
System.out.println("Number of objects in the bucket: " + totalObjects);
s3Client.close();
}Here, we use a do-while loop to paginate through all the objects in the bucket. The loop continues until there are no more continuation tokens, indicating that we retrieved all objects.
Consequently, we get the following as output:
Number of objects in the bucket: 1060Using this approach, we explicitly manage pagination. We check for the presence of a continuation token and use it in the following request. This gives us complete control over when and how to request the next page. It allows for greater flexibility in handling the pagination process.
By default, the maximum number of objects returned in the response is 1000. It might contain fewer keys but will never contain more. We can change this via the maxKeys() method of the ListObjectsV2Reqeust.
5. Pagination With ListObjectsV2Iterable
We can use the AWS SDK to handle the pagination for us by using the ListObjectsV2Iterable class and listObjectsV2Paginator() method. This simplifies the code, as we don’t need to manage the pagination process manually. This leads to more concise and readable code, making it easier to maintain.
Let’s see how we can put it into action:
void listAllObjectsInBucketPaginated(int pageSize) {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET )
.maxKeys(pageSize) // Set the maxKeys parameter to control the page size
.build();
ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);
long totalObjects = 0;
for (ListObjectsV2Response page : listObjectsV2Iterable) {
long retrievedPageSize = page.contents().stream()
.peek(System.out::println)
.reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);
totalObjects += retrievedPageSize;
System.out.println("Page size: " + retrievedPageSize);
}
System.out.println("Total objects in the bucket: " + totalObjects);
s3Client.close()
}Here’s the output we get when we call the method with a pageSize of 500:
S3Object(Key=file_0.txt, LastModified=2023-06-06T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-06-06T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-06-06T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_494.txt, LastModified=2023-04-29T18:53:56Z, ETag="69b7a7308ee1b065aa308e63c44ae0f3", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_495.txt, LastModified=2023-04-29T18:53:57Z, ETag="83acb6e67e50e31db6ed341dd2de1595", Size=1, StorageClass=STANDARD)
S3Object(Key=file_496.txt, LastModified=2023-04-29T18:53:57Z, ETag="3beb9cf0eab8cbf2215990b4a6bdc271", Size=1, StorageClass=STANDARD)
S3Object(Key=file_497.txt, LastModified=2023-04-29T18:53:57Z, ETag="69691c7bdcc3ce6d5d8a1361f22d04ac", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_944.txt, LastModified=2023-04-29T18:54:27Z, ETag="f623e75af30e62bbd73d6df5b50bb7b5", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_945.txt, LastModified=2023-04-29T18:54:27Z, ETag="55a54008ad1ba589aa210d2629c1df41", Size=1, StorageClass=STANDARD)
S3Object(Key=file_946.txt, LastModified=2023-04-29T18:54:27Z, ETag="ade7a0dcf4ddc0673ed48b70a4a340d6", Size=1, StorageClass=STANDARD)
S3Object(Key=file_947.txt, LastModified=2023-04-29T18:54:27Z, ETag="0a476d83ef9cef4bce7f9025522be3b5", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_999.txt, LastModified=2023-04-29T18:54:31Z, ETag="5e732a1878be2342dbfeff5fe3ca5aa3", Size=1, StorageClass=STANDARD)
Page size: 60
Total objects in the bucket: 1060The AWS SDK handles the pagination lazily by retrieving the next page when we iterate over the pages in the for loop. It fetches the next page only when we reach the end of the current page, which means that the pages are loaded on-demand and not all at once.
6. List Objects Using a Prefix
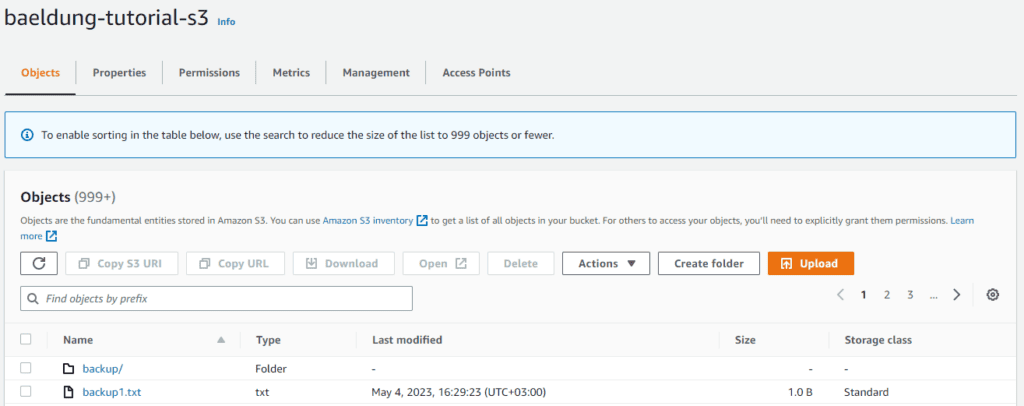
In some cases, we’d want to list just objects with a common prefix, for example, all that start with “backup”.
To showcase this use case, let’s upload a file named backup1.txt to the bucket, create a folder named backup and move six files into it. The bucket now contains seven objects in total.
This is what our bucket would look like:
👁 S3 Objects with common prefix{kind=link}
{kind=link}
Let’s change our function to return just the objects with a common prefix:
void listAllObjectsInBucketPaginatedWithPrefix(int pageSize, String prefix) {
S3Client s3Client = S3Client.builder()
.region(AWS_REGION)
.build();
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder()
.bucket(AWS_BUCKET)
.maxKeys(pageSize) // Set the maxKeys parameter to control the page size
.prefix(prefix) // Set the prefix
.build();
ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);
long totalObjects = 0;
for (ListObjectsV2Response page : listObjectsV2Iterable) {
long retrievedPageSize = page.contents().stream().count();
totalObjects += retrievedPageSize;
System.out.println("Page size: " + retrievedPageSize);
}
System.out.println("Total objects in the bucket: " + totalObjects);
s3Client.close();
}We just had to call the prefix method on the ListObjectsV2Request. If we call the function with the prefix parameter set to “backup“, it would count all the objects from the bucket that start with “backup”. Both keys, “backup1.txt” and “backup/file1.txt” would match:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup");Here’s the result we get back:
S3Object(Key=backup/, LastModified=2023-04-30T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-04-30T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-04-30T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-04-30T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-04-30T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-04-30T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
S3Object(Key=backup1.txt, LastModified=2023-05-04T13:29:23Z, ETag="ec631d7335abecd318f09f56515ed63c", Size=1, StorageClass=STANDARD)
Page size: 7
Total objects in the bucket: 7If we don’t want to count the object directly under the bucket, we need to add a trailing slash to the prefix:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup/");Now we get just the objects inside the “bucket/” folder:
S3Object(Key=backup/, LastModified=2023-04-30T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-04-30T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-04-30T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-04-30T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-04-30T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-04-30T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
Page size: 6
Total objects in the bucket: 67. Conclusion
In this article, we looked at different use cases for effectively listing objects in an AWS S3 bucket using the AWS SDK for Java V2.
We learned different approaches to managing object listings, such as using ListObjectsV2Reqest for less than 1000 objects, implementing pagination using a continuation token, leveraging the convenience of ListObjectsV2Iterable for automatic pagination, and using common prefixes to filter and organize object listings.
The code backing this article is available on GitHub. Once you're logged in as a Baeldung Pro Member, start learning and coding on the project.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}