 |
VOOZH | about |
|
VOOZH | about |
Discover 6 common AI infrastructure pitfalls that slow down AI innovation. Learn how to avoid them and accelerate your AI journey from development to production with BentoML’s scalable inference platform.
AI teams today face constant pressure to move faster. There’s always a new AI initiative that needs to launch quickly, a cutting-edge open-source model worth integrating, or a novel inference setup that could improve performance. But instead of shipping these ideas quickly, many get stuck in backlog while teams report: “Infrastructure is slowing us down.”
Sound familiar? The core issue is that AI systems have grown increasingly complex, making deployment on traditional infrastructure an uphill battle. Unlike conventional applications, modern AI systems require:
These are critical considerations for AI teams, but implementation often falls to dedicated infrastructure teams, which means extra delays and costs.
Ideally, AI teams would have infrastructure that provides:
When AI teams get mired in infrastructure tasks, innovation suffers. That’s why we built BentoML — to remove infrastructure roadblocks and help AI teams move faster. In working with enterprises deploying AI at scale, we’ve identified the six common pitfalls that slow AI teams down. In this post, we’ll share what we’ve learned and how you can fix them.
Your team has just delivered a new model that could improve customer experience. But when you ask when it can go live, the answer is deflating: “We need to set up the infrastructure, which will take a couple of weeks.”
AI workloads require specialized infrastructure that demands extra engineering effort, including:
Beyond setup, AI engineers must also learn and adapt to custom infrastructure, from building container images in a specific way to implementing metrics collection code and handling boilerplate configurations. These efforts are often duplicated across different projects with minor tweaks, requiring back-and-forth coordination between multiple teams. Over time, they have serious business implications:
AI teams can’t afford to spend weeks managing infrastructure. They need to focus on building, iterating, and deploying models.
BentoML transforms the infrastructure burden from weeks of manual work to simple, automated processes. The fully-managed AI inference platform provides:
“BentoML’s infrastructure gave us the platform we needed to launch our initial product and scale it without hiring any infrastructure engineers. As we grew, features like scale-to-zero and BYOC have saved us a considerable amount of money.”
—— Patric Fulop, CTO of Neurolabs
Most AI/ML infrastructure implementations lock runtimes (e.g., PyTorch and vLLM) to specific versions. The primary reason is to cache container images and ensure compatibility with infrastructure-related components. While this simplifies deployment in clusters, it also restricts flexibility when you need to test or deploy newer models or frameworks that fall outside the supported list.
As the AI runtime space rapidly evolves, this limitation becomes an even bigger challenge. For LLMs alone, teams must choose from a growing number of implementations (e.g. vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI), each with different trade-offs in performance, throughput, and latency.
When AI teams are forced to work within rigid, outdated environments, it means:
BentoML gives AI teams the freedom to use any ML tool, model, or framework without waiting on infrastructure updates.
"BentoML provides our research teams a streamlined way to quickly iterate on their POCs and when ready, deploy their AI services at scale. In addition, the flexible architecture allows us to showcase and deploy many different types of models and workflows from Computer Vision to LLM use cases.”
—— Thariq Khalid, Senior Manager, Computer Vision, ELM Research Center
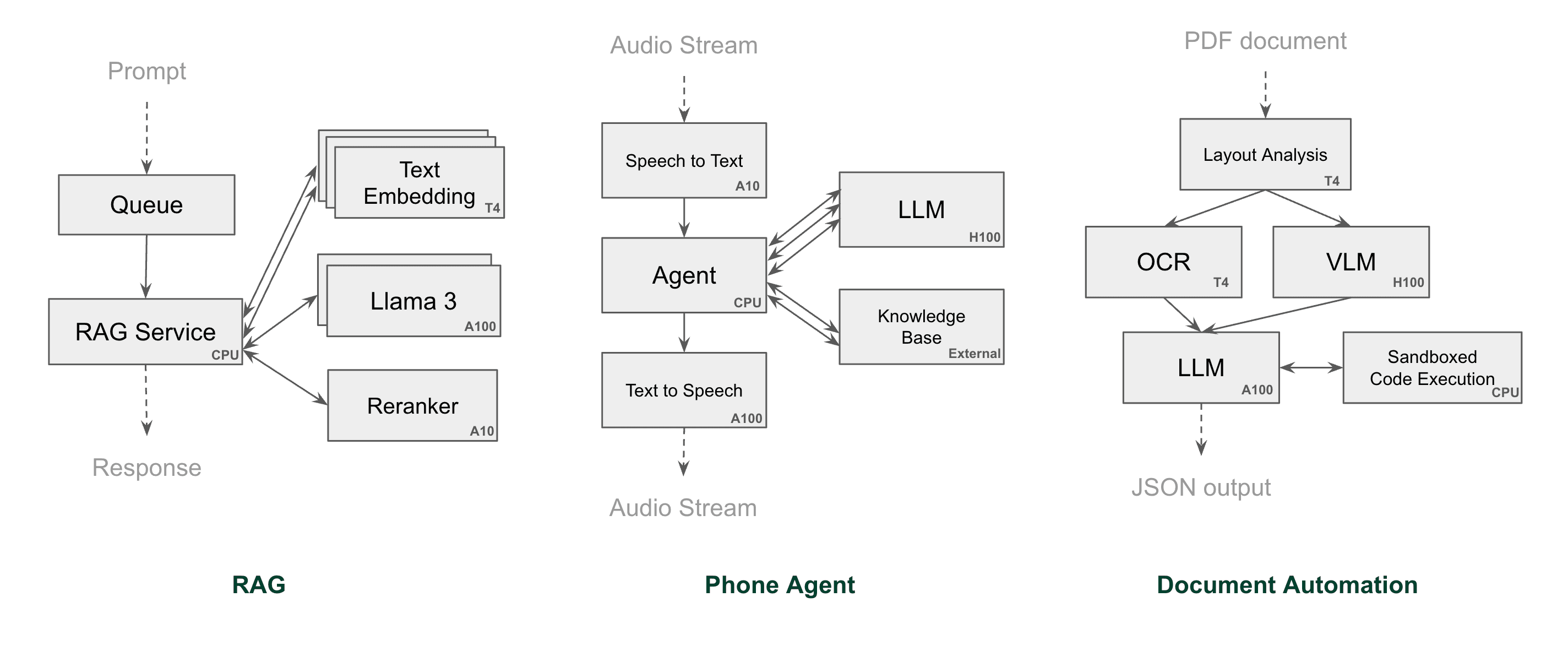
AI models alone don’t deliver business value. They need to be integrated into a broader AI system. Beyond simply loading model weights, you may also need additional components, such as:
But here’s the challenge: Traditional frameworks and tools aren’t built for advanced code customization; they only offer rigid, predefined API structures with limited flexibility. Adding custom logic often means hacking together workarounds or spreading business logic across multiple services. This results in unnecessary complexity and maintenance overhead.
BentoML provides first-class support for custom code.
Custom code lives with the model. Instead of defining preprocessing, postprocessing and business logic across different services and managing them via completely different processes, BentoML lets developers customize these steps directly within the model deployment pipeline using idiomatic Python.
Multi-model pipelines & distributed AI services. BentoML provides simple abstractions for building workflows where:
You’re deep in development, refining your model inference code and business logic. You change a few lines of code but hesitate before testing: it can take tens of minutes or even hours to get it up and running again.
Why? Your model requires GPUs, and your laptop simply doesn’t have the power. That means you need to redeploy everything to the cloud, a process that involves:
By the time you see an error message about a simple config mistake, 30 minutes has passed. But it’s not just code iteration that suffers. Any adjustment to inference setup, model configurations, or infrastructure faces the same problem. For every single iteration, you need a complete end-to-end evaluation run.
Such development iteration is just painfully slow.
When AI teams are forced to work within slow iteration loops, the consequences go beyond just wasted time:
BentoML gives developers instant feedback loops for code, model, and infrastructure changes.
Local development. BentoML supports running and testing code locally, when the development environment has the necessary compute resources.
Cloud development with BentoML Codespaces. It allows you to run your development environment instantly in the cloud and:
Here is a demo of adding function calling to a phone calling agent built with Codespaces.
Fast cold starts. Your code and models reload quickly upon changes, minimize waiting time.
“BentoML allows us to build and deploy AI services with incredible efficiency. What used to take days, now takes just hours. In the first four months alone, we brought over 40 models to production, thanks to BentoML’s inference platform.”
—— Director of Data Science at NYSE listed Technology Company
Typical AI infrastructure is tied to a single cloud provider and region, which may not have the GPU capacity you need. If you switch to another provider, it often means rebuilding your infrastructure stack from scratch, a process that could take months.
When your team doesn’t have the compute resources they need, the impact goes far beyond just waiting in a queue:
BentoML gives your team the freedom to deploy models anywhere, without re-engineering your stack.
You finally deployed a few models in the cloud. Congratulations! At first, everything seemed fine. But soon, the operational chaos begins:
These questions highlight a fundamental problem: lack of standardization. Without unified AI operations - what we call InferenceOps, routine tasks turn into painful cross-team coordination.
As you scale AI deployments, the fragmentation worsens. More models and types, more frequent updates, and more clouds and regions all require standardized workflows and centralized management. Otherwise, maintenance issues can compound, leading to:
BentoML provides a future-proof infrastructure to support scalable AI maintenance and InferenceOps.
Bringing AI models from development to production shouldn’t take months. For many teams, however, it does. The above-mentioned six pitfalls often hold teams back, delaying innovation and increasing costs.
BentoML removes these roadblocks by automating deployment, scaling, and infrastructure management. This allows AI teams to focus on what they do best: building innovative AI solutions that drive business value. With BentoML, teams can speed up AI development by up to 20x, delivering models to production faster and staying ahead of the competition.
Ready to deploy AI models faster?
Stay updated on AI infrastructure, inference techniques, and performance optimization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}