
AI cost optimization in 2026: what AI actually costs and how to cut it
{kind=link}
Quick Answer
AI cost optimization is the practice of reducing what organizations spend on training, deploying, and running AI workloads such as GPU compute, LLM API consumption, and inference infrastructure, without degrading model performance or business value. The highest-impact levers are commitment-based GPU discounts (40–72% savings), model right-sizing, and token waste reduction. CloudZero is the first cloud cost management platform to integrate directly with Anthropic and OpenAI, unifying LLM API spend with infrastructure costs to answer: was the AI spend worth it?
Run a cluster of eight around the clock and the invoice hits $71,800 per month, before storage, data transfer, or the staging notebook someone left running over the long weekend at $1,500/month.
Meanwhile, CloudZero’s ROI in the AI Era report found that organizations budget 30–36% of cloud cost optimization spend for AI, but actual billing data shows AI-specific line items at closer to 2.5%. The other 97.5% is buried in generic compute and storage accounts that nobody attributes to AI workloads. That visibility gap is where cloud cost savings hide, and where most organizations are flying blind.
This guide provides real dollar figures for AI workloads in 2026, ranks the optimization levers by impact, and shows how cloud cost optimization strategies connect to the question finance teams actually care about: not “how much did we spend?” but “did the spend drive value?”
What is AI cost optimization?
AI cost optimization is the discipline of continuously monitoring, allocating, and reducing the cost of AI and machine learning (ML) workloads, including model training, fine-tuning, inference, and LLM API consumption, while preserving model quality and business outcomes. It encompasses GPU compute, storage, data pipelines, token-based API consumption, and the operational overhead of managing AI infrastructure at scale.
That definition covers a lot of ground, and it needs to, because the challenge is that broad.
Traditional cloud cost optimization focuses on CPU compute, storage tiers, and networking. AI infrastructure cost optimization adds three dynamics that make the old playbook insufficient:
First, GPU economics are nothing like CPU economics. A 10% utilization improvement on a $0.042/hour t3.medium saves less than half a cent. The same improvement on a $98/hour H100 saves $9.80, a 233x difference in the dollar impact per optimization decision. When the FinOps Foundation’s 2025 State of FinOps Report lists AI/ML spending management as the number-one emerging priority, jumping four positions year over year, this math is why.
Second, token-based pricing models for LLM APIs introduce per-request economics that have no parallel in traditional infrastructure. The same Claude Sonnet call costs $3.00 per million input tokens direct, but 10–20% more routed through a cloud marketplace. You’re paying for the convenience.
Third, the training-versus-inference lifecycle creates two fundamentally different spending profiles. Training is bursty, interruptible, and commitment-hostile. Inference is steady-state, latency-sensitive, and commitment-friendly. Optimize them the same way and you’ll over-commit on one and under-commit on the other.
This is cost intelligence: connecting spend to business context, not just tracking the total. The difference between “our GPU bill was $500K” and “Feature X costs $0.003 per API call for our largest customer, but Feature Y costs $0.14, and Y is the one with a negative margin.” One of those statements starts a conversation. The other ends up in a slide deck nobody reads.
Now that the foundation is clear, the next question is obvious: what do these workloads actually cost in dollar terms?
playbook
The AI Cost Optimization Playbook
Traditional cloud cost management is broken. Here’s why — and how to make the switch to cloud cost intelligence.
What do AI workloads actually cost in 2026?
AI workloads in 2026 cost roughly $1–$98 per GPU hour and $0.075–$15 per million tokens, depending on instance type, model, and routing. Below are the real numbers across AWS, GCP, and Azure.
GPU compute: On-demand pricing across providers
The AI server cost for running AI workloads depends on GPU type, provider, and commitment level. This table shows on-demand rates, what you pay without any discount.
Instance | Provider | GPUs | GPU type | $/hr on-demand | Monthly (24/7) |
p5.48xlarge | AWS | 8 | H100 80GB | $55.04 | $40,179 |
p4d.24xlarge | AWS | 8 | A100 40GB | $21.96 | $16,029 |
g5.xlarge | AWS | 1 | A10G 24GB | $1.01 | $737 |
inf2.48xlarge | AWS | 12 | Inferentia2 | $12.98 | $9,476 |
trn1.32xlarge | AWS | 16 | Trainium | $21.50 | $15,695 |
a3-highgpu-8g | GCP | 8 | H100 80GB | $88.49 | $64,598 |
a2-highgpu-1g | GCP | 1 | A100 40GB | $3.67 | $2,679 |
ND96isr_H100_v5 | Azure | 8 | H100 80GB | $98.32 | $71,774 |
For real-time cross-provider comparisons, see CloudZero’s cloud GPU pricing comparison.
A workload running on a p5.48xlarge that only needs a g5.xlarge is overspending by 97x. Not a rounding error. CloudZero’s anomaly detection catches exactly this kind of mismatch and routes the alert to the engineering team that owns the workload, not to a Slack channel where it gets lost between lunch polls and deploy notifications.
Those infrastructure numbers tell one side of the story. But for teams consuming AI through APIs, which now includes most production deployments, inference costs are measured in tokens, not instance hours.
What LLM API calls actually cost at scale
LLM costs depend on which model you call, how many tokens you send, and where you route the request. Here is what the major models charge per million tokens:
Model | Provider | Input/1M tokens | Output/1M tokens |
GPT-4o | OpenAI | $2.50 | $10.00 |
GPT-4o mini | OpenAI | $0.15 | $0.60 |
Claude Sonnet 4 | Anthropic | $3.00 | $15.00 |
Claude Haiku 3.5 | Anthropic | $1.00 | $5.00 |
Gemini 1.5 Pro | $1.25 | $10.00 | |
Gemini 1.5 Flash | $0.30 | $2.50 |
The spread between cheapest and most expensive option in each provider’s lineup is 8–23x. The bigger cost variable is in the routing, not the model. Running the same Claude Sonnet call through Amazon Bedrock or Azure OpenAI adds a 10–20% cloud marketplace premium on top of the base token rate. At millions of tokens monthly, that markup compounds into a line item nobody planned for.
CloudZero’s direct integrations with Anthropic and OpenAI, plus support for Bedrock, Vertex AI, and Azure OpenAI; pull token consumption from every source into a single view. That is the only way to compare direct API costs against cloud marketplace costs without building a spreadsheet that becomes stale the day after you ship it.
{kind=link}
For complete pricing breakdowns by model, see CloudZero’s guides to ChatGPT pricing, Claude API pricing, OpenAI API pricing, and Gemini API cost per call.
The costs that never make it into the AI budget
The cost of generative ai extends well beyond GPU instances and API calls. Training datasets, model checkpoints, and fine-tuning artifacts accumulate storage costs that sit outside the AI line item entirely. Databricks or Snowflake for feature stores, data preprocessing, and model monitoring add AI compute costs that exist because of AI but never get attributed to AI workloads.
Idle SageMaker notebooks with GPU attachments, left running over weekends by engineers who “will get to it Monday”, cost $500–$3,000 per month each. Vertex AI workbenches have the same problem. And data transfer between training clusters and storage layers, especially in multi-region setups, adds a meaningful percentage to total AI infrastructure cost that rarely appears in pre-project estimates.
CloudZero’s FinOps in the AI Era report quantifies this gap: organizations’ reported AI spending is roughly 12x lower than their actual AI-driven cloud consumption. The rest is ghost spend, hiding in compute, storage, and data transfer where nobody connects it to the AI workloads that created it.
Understanding what you spend is the prerequisite. The next step is understanding where the money goes, and which cost drivers move the most dollars.
What are the biggest AI cost drivers?
The biggest AI cost driver at most organizations is overprovisioned GPU compute. Below are the five highest-dollar drivers, ranked by impact.
- Overprovisioned GPU instances. Engineering teams default to the largest available GPU for the same reason they used to default to the largest EC2 instance: it works, and nobody gets paged at 2 AM for over-provisioning. But a p5.48xlarge running a workload that needs a g5.xlarge burns $71,800/month in excess spend. CloudZero customers routinely find 40–60% of GPU instances oversized, a pattern that only becomes visible when cost per team and feature is mapped to utilization data. This is the single largest gpu cost optimization opportunity at most organizations.
- On-demand GPU pricing without commitments. AWS Savings Plans save up to 66% on GPU instances. Reserved Instances save up to 72% on 3-year terms. AWS cut P4 and P5 prices by up to 45% for committed customers, meaning the gap between committed and on-demand pricing has never been wider.
- Idle resources nobody owns. A forgotten p5 instance costs $71,800/month. A staging SageMaker notebook with a GPU costs $1,500/month. Multiply that across every team running experiments and it becomes a serious line item, one finance usually can’t even see. Without cost allocation that maps resources to owners, nobody knows the idle GPU exists, so nobody turns it off.
- Token waste and context window bloat. Every token costs money. Re-sending 4,000 tokens of system context with every API call, because the integration was built in a hackathon and nobody refactored it, multiplies costs linearly. A chatbot processing 1,000 requests/hour at 4K context tokens burns 2.88 billion tokens/month in context alone. At $2.50/1M input tokens, that is $7,200/month per endpoint, just for the context window, before the model generates a single output token. Teams running multi-LLM stacks multiply this across providers.
- No attribution to business outcomes. When GPU spend is an account-level line item with no connection to teams, features, or customers, AI cost reduction is guesswork. The FinOps Foundation’s 2025 State of FinOps Report found fewer than 30% of organizations have mature cost allocation for AI workloads. Without it, every other optimization on this list is a shot in the dark.
The thread connecting all five: visibility. You cannot right-size what you cannot see. You cannot commit on workloads you cannot attribute. You cannot cut token waste you cannot measure. Each of these problems has a specific solution, ranked by dollar impact in the next section.
How to reduce AI infrastructure costs: 7 cloud cost optimization strategies ranked by dollar impact
These it cost optimization strategies are ordered by how much money they move. The playbook works for aws cost optimization, Azure, GCP, and multi cloud cost optimization environments, because the principles apply everywhere, even if the implementation varies by provider.
- Commit to discounted GPU pricing, continuously, not annually. This is the single largest dollar lever and the top cloud cost optimization best practices recommendation from every FinOps framework. Compute Savings Plans save up to 66%; convertible Reserved Instances save up to 72%. But the key insight most teams miss: do not batch-purchase commitments once a year. GPU workloads shift faster than traditional compute, teams migrate from A100s to H100s mid-year, new models demand different instance families, and batch inference volumes are seasonal. CloudZero’s discount analytics surfaces exactly where commitment coverage gaps exist. The result: cloud cost savings of 40–72% on the largest line items.
- Right-size GPU instances to actual workload needs. The fastest way to reduce AWS costs on AI workloads is matching instance type to actual demand. AWS Inferentia2 delivers up to 4x better price-performance for many inference tasks compared to general-purpose GPUs. Trainium handles training workloads at a fraction of equivalent NVIDIA instance costs. Decision framework: batch inference on sub-13B models → Inferentia2 or Trainium. Real-time inference on 70B+ → H100s earn their price. Everything in between → g5 with A10G. This single strategy addresses infrastructure cost optimization at the resource level.
- Use spot instances for fault-tolerant training. Spot pricing saves 60–90% on GPU instances. PyTorch and TensorFlow both support native checkpointing, so interruptions restart from the last checkpoint, not from scratch. Catch: spot availability for GPU instances varies wildly by region. Test availability before designing your pipeline around it. This is one of the most effective cloud cost optimization techniques for bursty training workloads.
- Separate inference from training infrastructure. Inference is steady-state, perfect for commitments. Training is bursty, perfect for spot or Capacity Blocks. Blending them means you either over-commit or under-commit. CloudZero customers who separate these workloads see 35–50% lower total AI cloud cost optimization spend, because they can commit aggressively on inference while using spot for training. This separation is the most underused cloud spend optimization lever in AI, and a core cloud cost management strategies principle.
- Choose the right model, not the biggest. A fine-tuned 7B model often outperforms a general 70B on domain-specific tasks at a fraction of the inference costs. Quantization (INT8/INT4) cuts serving costs 50–75% with minimal quality loss. A routing layer that sends simple queries to Haiku-class models and reserves frontier models for complex reasoning.
- Optimize prompts and eliminate token waste. Reducing average prompt length by 30% reduces API costs by 30%, the math is linear. Cache system prompts. Strip unnecessary context from multi-turn conversations. Batch inference requests. Teams using Amazon Bedrock or Azure OpenAI should enable prompt caching, which cuts repeated-context costs by 50–90%. This is the lowest-effort, highest-percentage lever for any team consuming LLM APIs at scale.
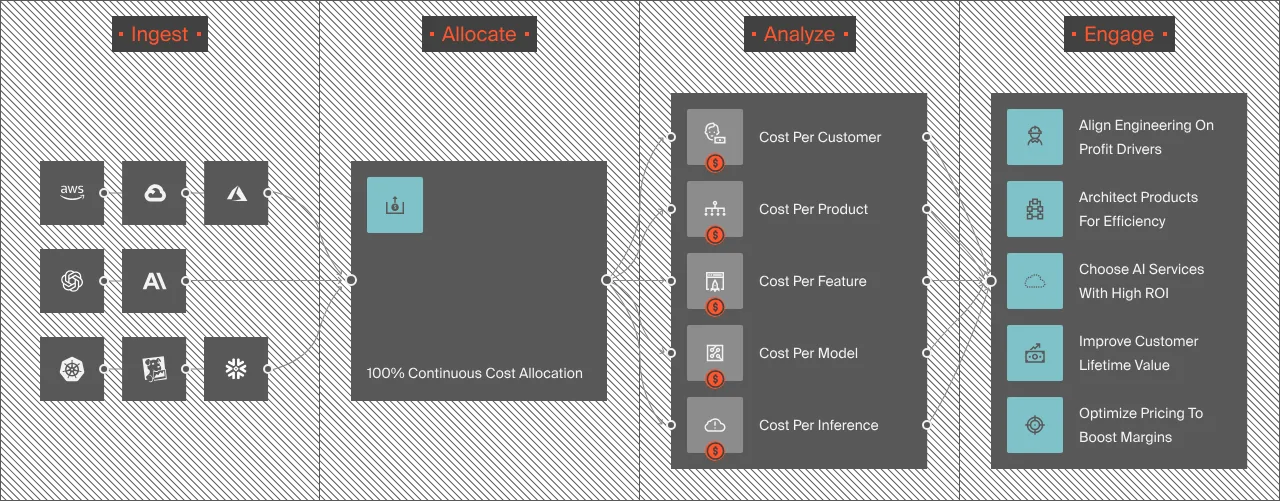
- Allocate every AI dollar to teams, features, and customers. Allocation is more than just a tactic; it’s the very foundation every other tactic depends on. When engineering teams see their AI cost per feature, they optimize naturally. No mandates needed. CloudZero maps spend to business dimensions; cost per customer, product, team or deployment, with no tagging required on every resource. Teams that gain this visibility reduce costs by 20–35% within the first quarter. For the mechanics, see CloudZero’s guide to chargeback vs. showback. This is the strategy that transforms reduce cloud costs from an abstract goal into a measurable, team-level outcome.
The seven strategies above answer “how do I spend less?” But the sharper question, and the one that separates cost cutting from cost intelligence, is next.
How do you measure AI cost per unit of business value?
Knowing you spent $500K on GPU compute last month is just a number without context. What did it produce? Which customers did it serve? Which features consumed the most?
AI cost efficiency means cost in context, cost per customer served, cost per inference request, cost per AI-powered feature, cost per dollar of revenue generated. These are cloud cost optimization metrics that native cloud tools were never designed to provide. They are unit economics applied to AI infrastructure.
CloudZero’s approach: ingest cost data from every source, AWS, GCP, Azure, Kubernetes, Snowflake, Datadog, MongoDB, Anthropic, OpenAI, and 30+ other providers, normalize it into a common data model, then map it to business dimensions that engineering and finance define together. No resource-by-resource tagging. No manual spreadsheets. The platform’s allocation engine attributes spend automatically, so teams can see cost per customer, cost per feature, and cost per team, the metrics that connect ai cost management to business outcomes.
{kind=link}
One CloudZero customer managing spend across 50+ LLMs discovered that a single low-usage model consumed 40% of their GPU budget. Another found their document processing feature cost $0.12 per document for one customer segment and $0.31 for another, because the second segment’s documents triggered the long-context pricing tier. Neither insight was visible in any billing dashboard. Both were visible in CloudZero within minutes.
Cost management tells you what you spent. Cost intelligence tells you whether it was worth it, and where to cut next. CloudZero is built for the second question. That distinction matters most when the tool delivering cost intelligence was built for exactly this problem.
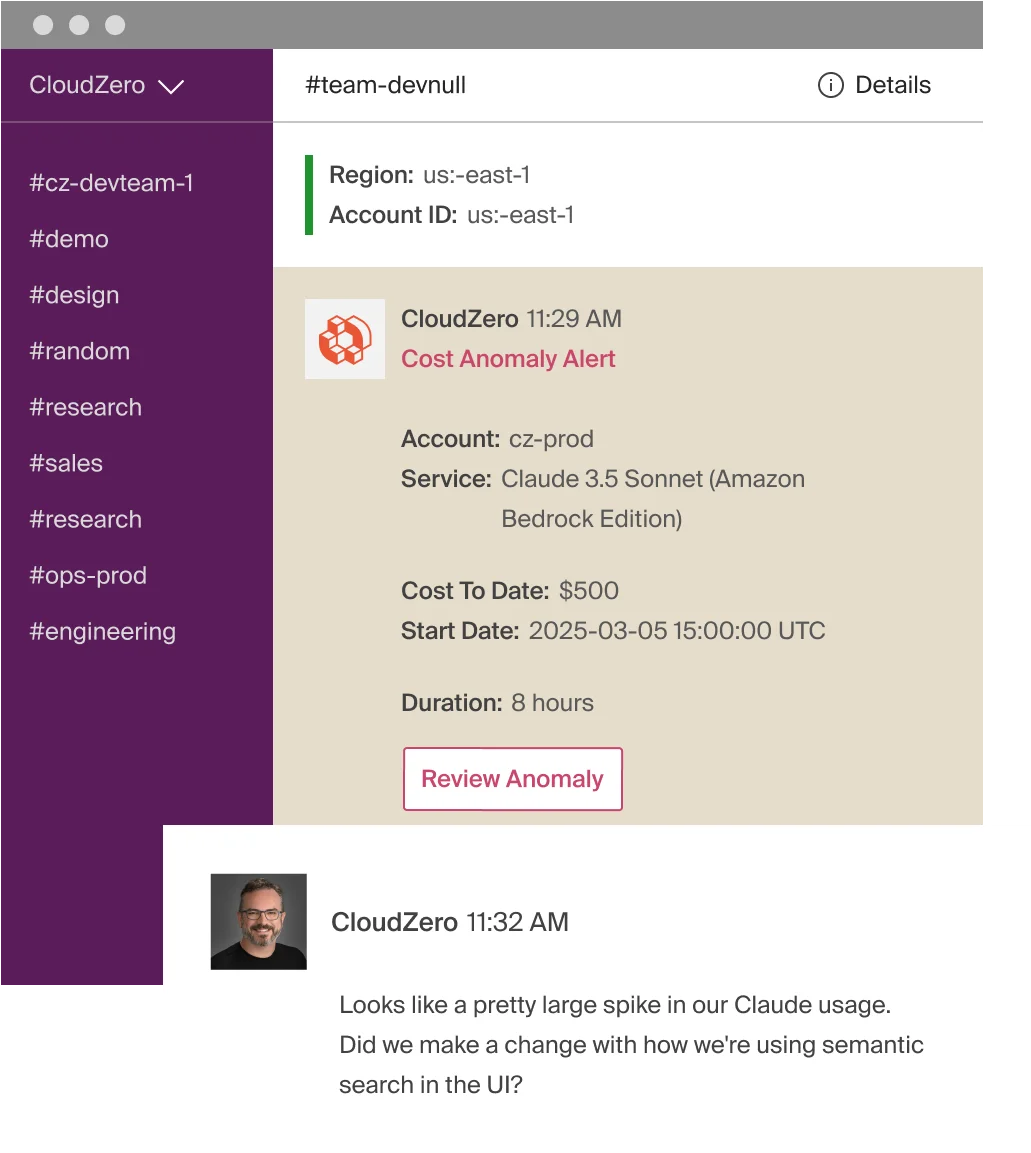
CloudZero’s anomaly detection compares hourly spend from the past 36 hours against 12 months of history, automatically defines “normal,” and alerts the engineering team that owns the affected workload. When a scaling event, bad deployment, or runaway Lambda adds thousands in minutes, the right team knows immediately.
{kind=link}
CloudZero’s cost per customer capability also shows which customers are profitable after infrastructure costs and which are margin-negative. For AI-heavy products, this is the difference between a product that scales profitably and one that quietly bleeds money on every new user. Combined with Kubernetes cost optimization visibility, teams can trace costs from the container level all the way to the customer.
Organizations like Toyota, Duolingo, Coinbase, Upstart, Drift, and Skyscanner use CloudZero to manage more than $15 billion in cloud and AI spend at this level of granularity. Ready to see what your AI spend actually looks like? 👁 Image
to see CloudZero’s AI cost intelligence in action. You can also get a free cloud cost assessment, where CloudZero’s team analyzes your current spend and identifies optimization opportunities at no cost.
{kind=link}
Frequently Asked Questions about AI cost optimization
{kind=link}
Author Spotlight
ROI in the AI Era: A Critical Recalibration
Suggested Articles
See more{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
see cloudzero in action