
Introducing Token Intelligence: trace what your AI spend is actually producing
Today we are introducing Token Intelligence in Faros. Token Intelligence traces the flow of AI tokens to the work they produced, so engineering leaders can understand their spend, optimize their workflows, and maximize the outcomes it should deliver.
The pricing model for AI shifted underneath everyone. GitHub moved to subscription plus consumption. Cursor, Copilot, and Windsurf reworked credits and added premium request charges. Anthropic and OpenAI rolled out tiered consumption pricing. The bills got big enough that companies are now scrambling to get their AI costs under control, and investors who once rewarded AI ambition want to see the return. Tokens are now a capital allocation decision, carrying the same weight as headcount and infrastructure.
A CTO at a large consumer tech company recently pulled his AI spend data. One engineer, his most productive, shipping more customer-facing features than anyone else on the team, was running up $47,000 a month in AI token costs. His question wasn't whether to cut it. It was whether he could afford to replicate it. That engineer earns north of $400,000 in total compensation, roughly $33,000 a month loaded, so the AI bill already runs higher than the salary. Is every dollar of that $47,000 doing productive work, or is some of it the detours the agent took, the redundant context, the wrong model for the task? And if this is what great looks like, what does it cost to run across 400 engineers? A usage dashboard can't tell him.
Stop tokenmaxxing. Start outcome maxxing.
The industry coined a term for how most organizations got here: tokenmaxxing. Push AI consumption as high as possible and assume value follows. For some teams it did. For others, the annual AI budget was gone before summer. AI agents compound the problem, multiplying model calls behind the scenes in ways seat-based tools never did, and a single agentic task can consume far more AI tokens than a standard prompt.
We don't think the answer is to spend less. If a dollar of tokens produces more than a dollar spent any other way, you should spend more, not less.
What matters is outcome maxxing: turning every dollar of AI spend into work that ships and outcomes that matter. It works in order: First you understand where the spend goes. Then you optimize the workflows currently wasting it. Then you maximize outcomes by making the AI more accurate.
Token Intelligence is where it starts.
{kind=link}
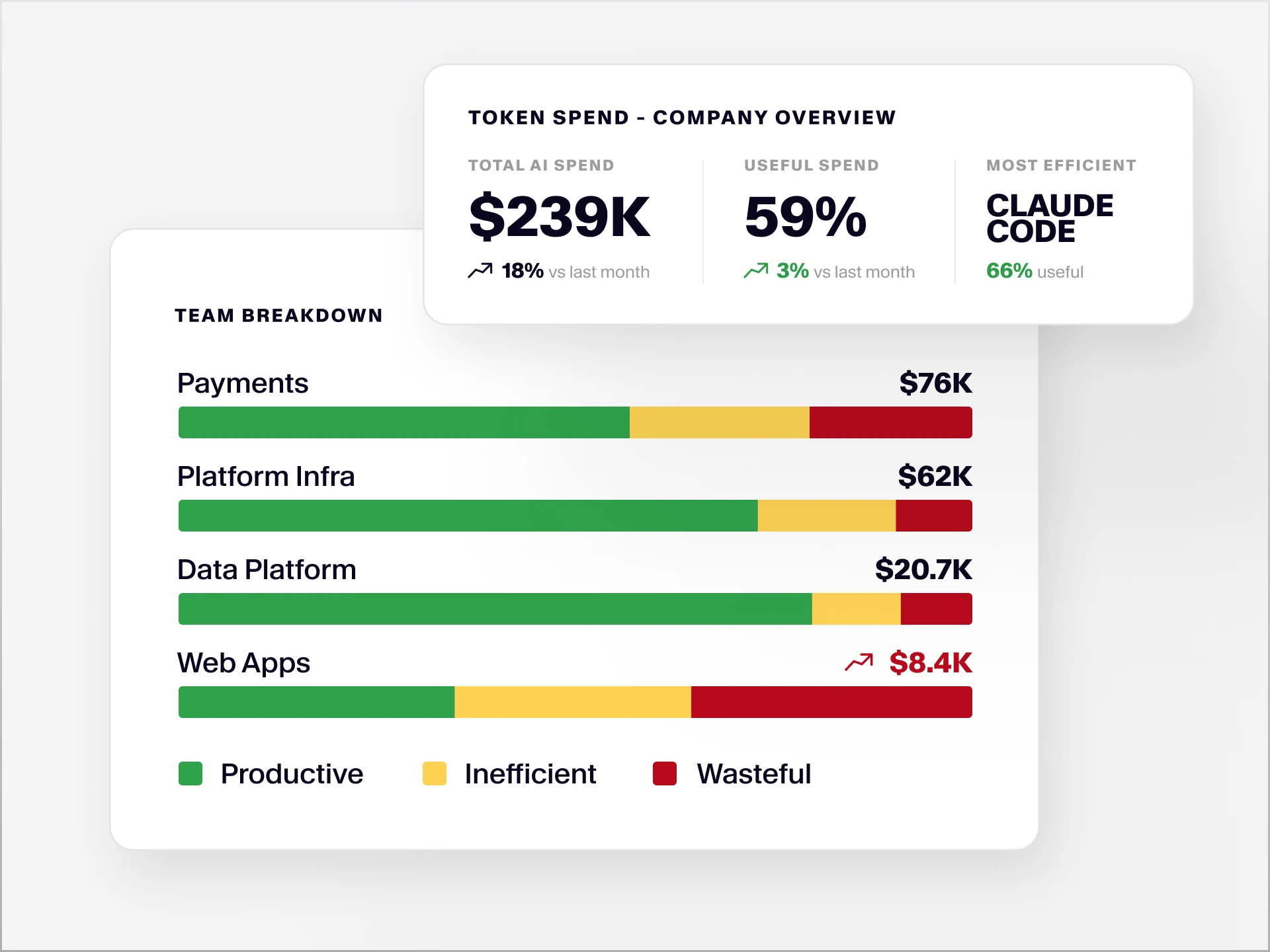
Understand your AI spend
Trace spend to its source. Total AI spend across the organization, broken down by team, tool, model, and type of work, tracked against a company baseline. Engineering leaders see where spend is concentrating, how fast it's growing, and which teams are running above or below the org average.
Classify every token by efficiency. Each token is classified as productive, inefficient, or wasteful based on the quality of the session that consumed it. Of that engineer's $47,000: how much went to lean, deliberate AI use with clear intent? How much went to loops where the agent explored a path that was ultimately abandoned — work that better prompting or the right context file could have avoided? How much went to running the most expensive model to move files around?
Attribute spend to teams and budgets. Spend mapped to each team and measured against budget, with outliers surfaced automatically. Every team sees their own spend, their own efficiency breakdown, and how they compare to the baseline.
Decide which tools and models to keep. A keep, scope, or cut verdict for every tool in the stack, based on outcomes, alongside which model performs best. Teams build the cost-efficient routes into their own practices and agent harnesses, and leaders walk into vendor conversations knowing exactly what each tool produced. As enterprises route work across frontier and open-weight models to manage costs, this is where the routing decisions get grounded in actual output data.
{kind=link}
Optimize your workflows
Once you can see where the spend goes, you need to know why. Token Intelligence connects to the rest of Faros, so engineering leaders can ask their own data questions in plain language and get findings back, not just charts. Why did this team's spend triple last month? Where is rework concentrated? Which workflows burn tokens without shipping anything? The answers come back grounded in how your engineering organization actually works. A manager doesn't have to build a dashboard to get one, and the findings point to the workflows worth fixing first.
{kind=link}
Maximize your outcomes
The biggest gains don't come from trimming spend. They come from making the AI more accurate, so more of every token lands on the first try. Faros takes what your organization already knows — its codebase history, the decisions behind it, the standards it holds — and delivers it as task-specific context and guardrails straight into your development workflows. Before an agent or an engineer starts a task, they already have the related PRs, the known bugs, and the checks that keep past failures from repeating. The work comes out better the first time, with less wasted exploration and more output that survives review.
{kind=link}
Why it works
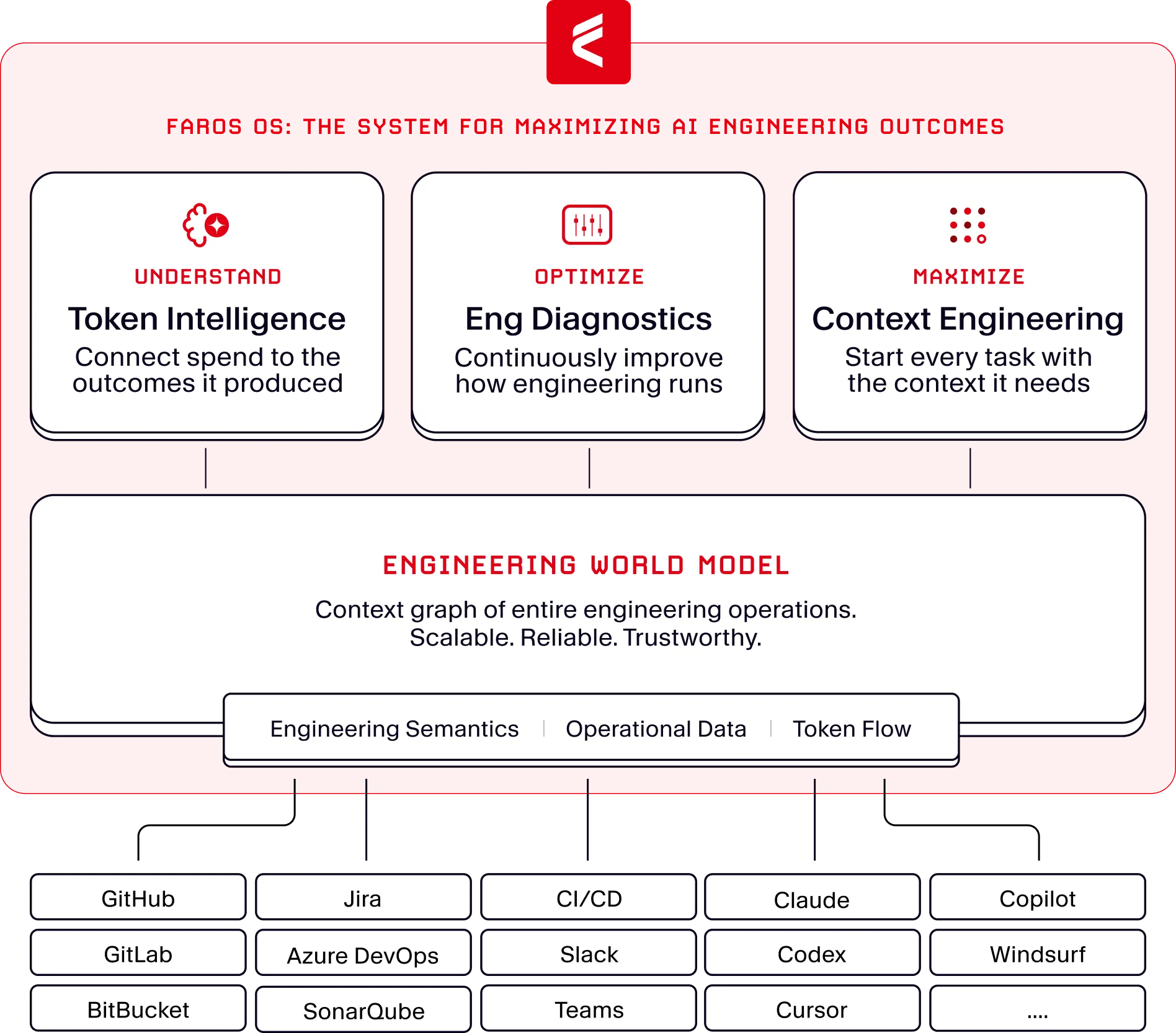
Token Intelligence sits on the Faros Engineering World Model, which connects data across teams, tools, repos, and workflows at any scale. That context is what makes efficiency classification accurate instead of a guess. Counting the tokens a session burned is easy. Knowing what the session was doing — and whether the AI was used well — takes a model of how your engineering organization actually operates. Underneath it is the Token Attribution Ledger, which ties every dollar to the work it did and the outcome it shipped. This is where AI FinOps gets precise: your AI tool vendors tell you what you spent. Faros tells you what it produced.
Deployment does not require any software installation on developer machines, and nothing interferes with the developer environment. Token Intelligence connects to your AI coding tools through their built-in telemetry, managed from one place.
{kind=link}
Where this is heading
Understand, optimize, maximize is a loop, and right now you run it. We are building toward a system that runs more of it on its own. It watches where AI works and where it doesn't, generates the context that keeps agents accurate, and keeps that context current as your code changes. Token intelligence is the first piece of that system, and the piece every organization needs first. You can't optimize or maximize what you can't yet trace.
Available now
Token Intelligence is available today. Every team can see its AI development costs and own its spend against budget. Leaders get the org-wide picture, spot the outliers, and make tool and model decisions with outcome data behind them.
Request a demo to see what your organization's token spend is producing.
The Field Guide to Measuring Token Efficiency covers the outcome signals and guardrail metrics behind this launch.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}