 |
VOOZH | about |
|
VOOZH | about |
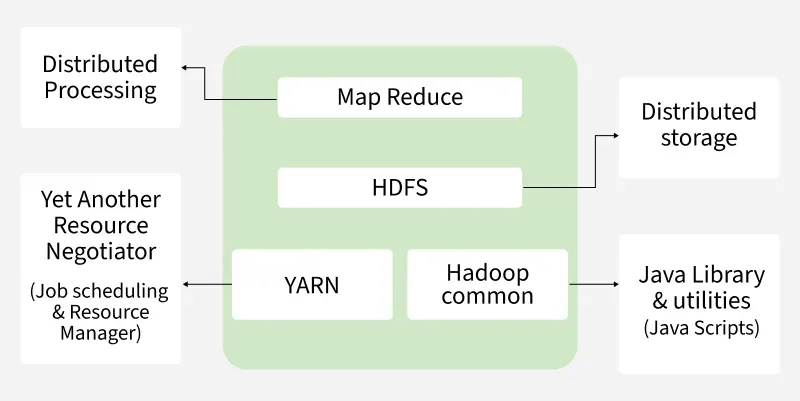
Hadoop is an open-source Java framework that stores and processes massive data using clusters of inexpensive (commodity) hardware. Based on Google’s MapReduce programming model, it enables distributed, parallel processing. Big companies like Facebook, Yahoo, Netflix and eBay use Hadoop to handle large-scale data efficiently.
Hadoop Architecture Mainly consists of 4 components:
Let's understand role of each one of this component in detail.
MapReduce is a data processing model in Hadoop that runs on YARN. It enables fast, distributed and parallel processing by dividing tasks into two phases Map and Reduce making it efficient for handling large-scale data.
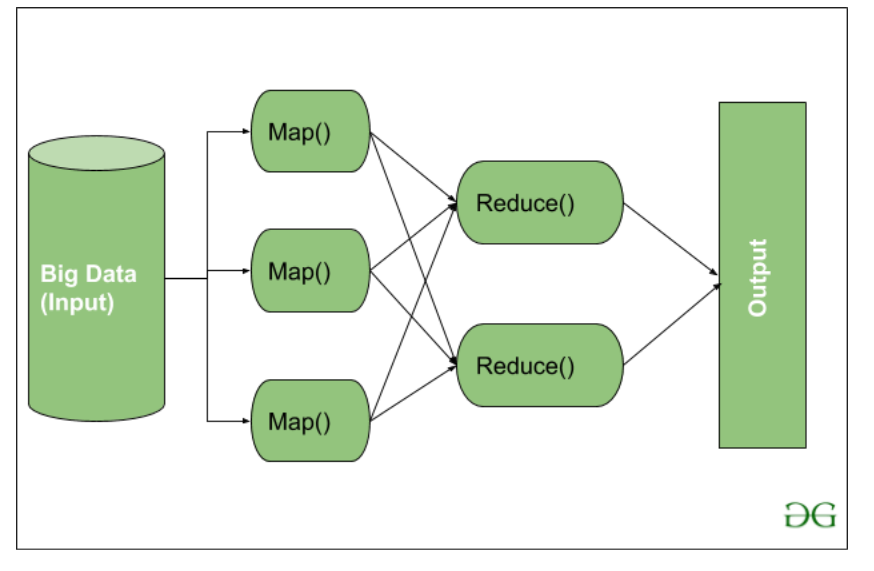
👁 MapReduce workflowMapReduce Workflow: workflow begins when input data is split into key-value pairs by Map() function. These are then grouped by key and processed by Reduce() function for tasks like sorting or aggregation. The final output is written to HDFS.
Note: Core aggregation often happens in the Reducer, but preprocessing and filtering are ideally done in the Mapper to optimize performance.
Map Task Components:
Reduce Task Components:
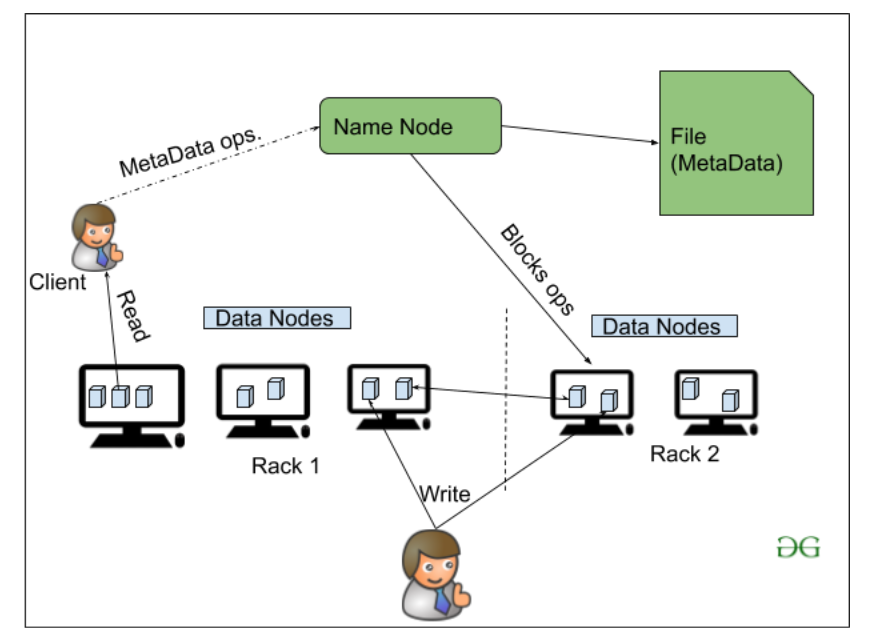
HDFS (Hadoop Distributed File System) is Hadoop’s primary storage system, built for high-throughput access to large datasets. It runs on inexpensive commodity hardware and stores data in large blocks to optimize performance. HDFS ensures fault tolerance and high availability across the cluster.
HDFS Architecture Components:
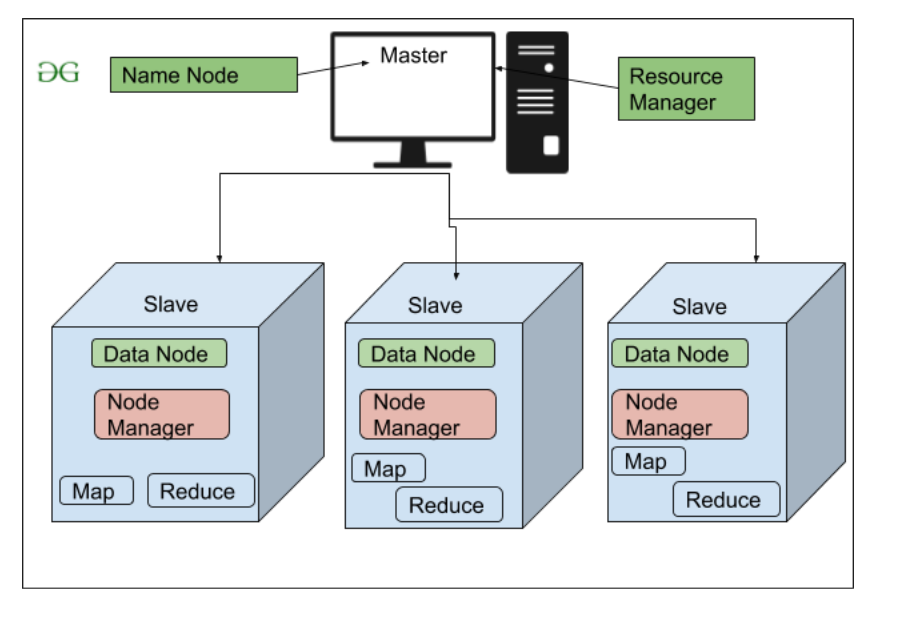
High Level Architecture Of Hadoop
👁 High Level Architecture Of Hadoop
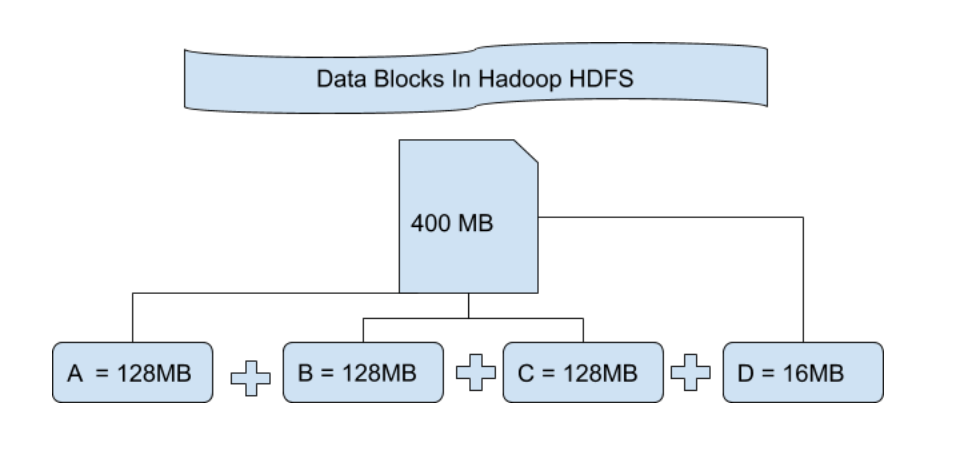
File Block In HDFS: In HDFS data is always stored in the form of blocks. By default, each block is 128MB in size, although this value can be manually configured depending on the use case (commonly increased to 256MB or more in modern systems).
Suppose you upload a file of 400MB to HDFS. Hadoop will divide this file into blocks as follows:
128MB + 128MB + 128MB + 16MB = 400MB
This creates four blocks three of 128MB and one of 16MB. Hadoop splits files purely by size, not content, so a single record can span across two blocks.
1. Comparison with Traditional File Systems
2. Replication In HDFS:
HDFS replication ensures data availability and fault tolerance by storing multiple copies of each block.
Designed for commodity hardware, where failures are common—replication prevents data loss. While it increases storage usage, reliability is prioritized over space efficiency.
3. Rack Awareness:
A rack is a group of machines (typically 30–40) in a Hadoop cluster. Large clusters have many racks. Rack Awareness helps NameNode to:
This improves overall performance and efficiency in data access.
HDFS Architecture
YARN is resource management layer in Hadoop ecosystem. It allows multiple data processing engines like MapReduce, Spark and others to run and share cluster resources efficiently.
It handles two core responsibilities:
Components of Yarn:
Key Features of YARN:
Hadoop Common, also known as Common Utilities, includes core Java libraries and scripts required by all components in a Hadoop ecosystem such as HDFS, YARN and MapReduce.
These libraries offer core functionalities such as:
Hadoop Common provides shared libraries and utilities that help all Hadoop components work together. It handles hardware failures automatically and includes tools like Hadoop Archive, native library support and RPC mechanisms.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}