 |
VOOZH | about |
|
VOOZH | about |
Before diving into Hadoop clusters, it's important to understand what a cluster is.
A cluster is simply a group of interconnected computers (or nodes) that work together as a single system. These nodes are connected via a Local Area Network (LAN) and share resources and tasks to achieve a common goal. Together, they function as one powerful unit.
A Hadoop cluster is a type of computer cluster made up of commodity hardware inexpensive and widely available devices. These nodes work together to store and process large volumes of data in a distributed environment.
In a Hadoop cluster:
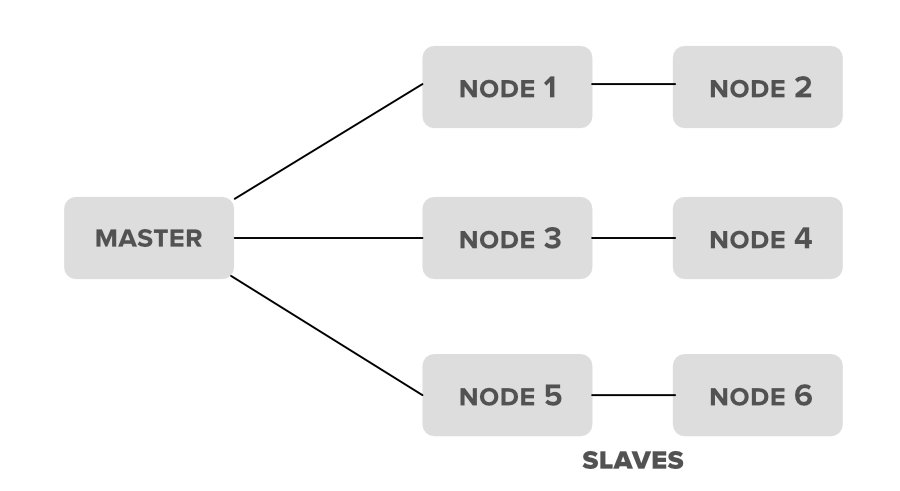
The Master nodes coordinate and guide the Slave nodes to efficiently store, process and analyze data.
Hadoop clusters can handle various types of data:
The image below demonstrates structure of a Hadoop cluster where the Master node controls and coordinates multiple Slave nodes. This setup enables distributed storage and parallel data processing across inexpensive hardware.
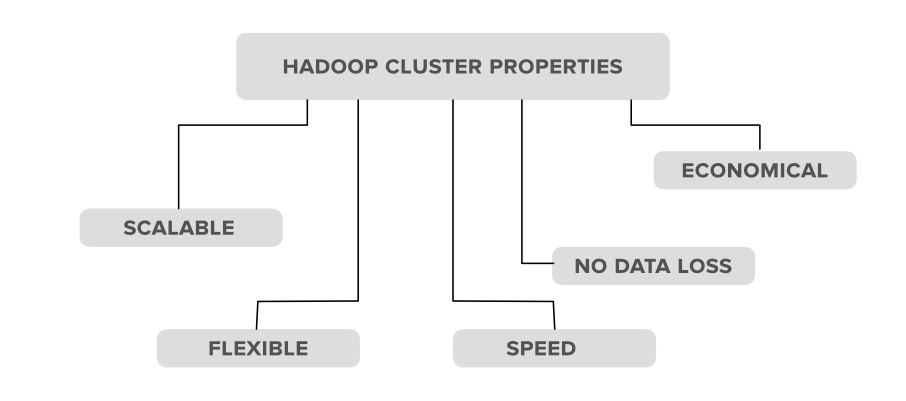
👁 Hadoop-Cluster-SchemaThe image below visually summarizes core properties of a Hadoop cluster, which are explained individually in the following sections.
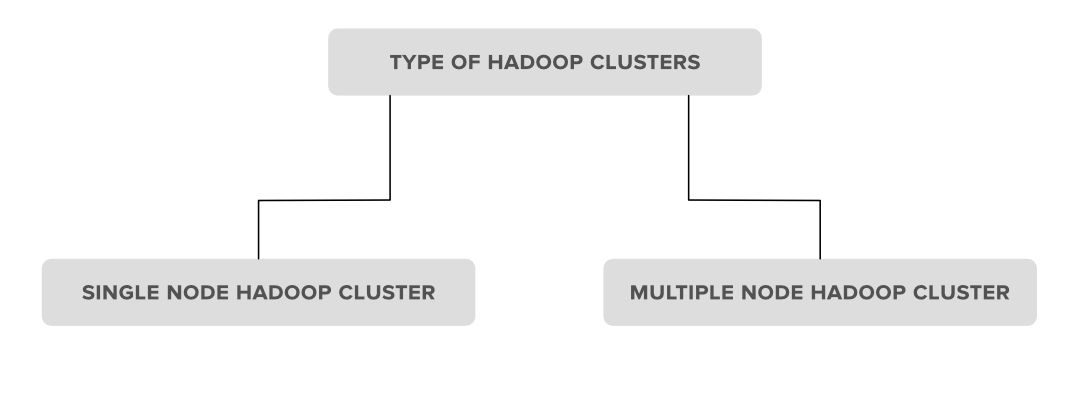
👁 Hadoop-Clusters-PropertiesHadoop clusters can be deployed in different ways depending on usage and environment. Each type serves a specific purpose, from testing to large-scale data processing. Let's discuss them further.
👁 Types-of-Hadoop-clustersIn a single node cluster, all Hadoop components (NameNode, DataNode, ResourceManager, NodeManager, etc.) run on the same machine. This setup uses a single JVM (Java Virtual Machine) and is mainly used for learning or testing purposes.
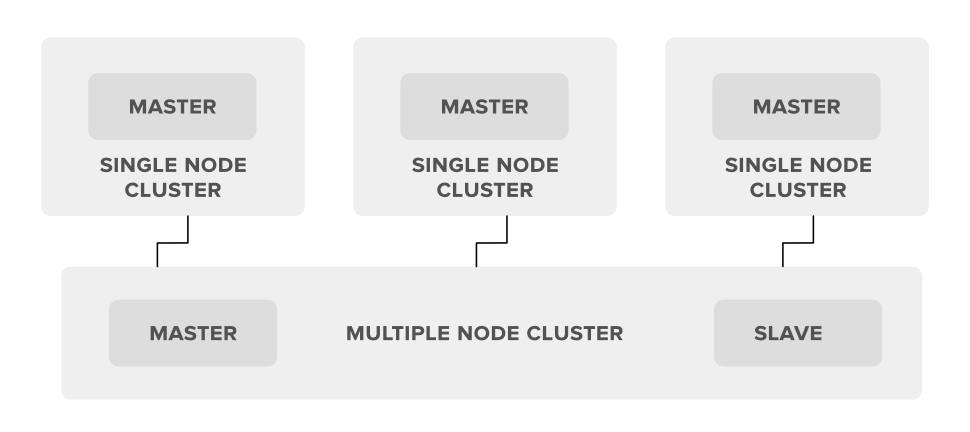
A multi node cluster has multiple machines (nodes). Master daemons like NameNode and ResourceManager run on powerful systems, while slave daemons like DataNode and NodeManager run on other, often less powerful, machines. This setup is used in real-world, large-scale data processing.
👁 Multiple-Node-Hadoop-Cluster{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}