 |
VOOZH | about |
|
VOOZH | about |
In Hadoop, daemons are background Java processes that run continuously to manage storage, resource allocation, and task coordination across a distributed system. These daemons form the backbone of the Hadoop framework, enabling efficient data processing and fault tolerance at scale.
Hadoop's architecture is divided into master and slave components, each managed by specific daemons:
With the introduction of YARN in Hadoop 2, resource management was decoupled from data processing, significantly improving Hadoop’s scalability, flexibility, and multi-application support.
NameNode works on the Master System. The primary purpose of Namenode is to manage all the MetaData. Metadata is the list of files stored in HDFS(Hadoop Distributed File System). As we know the data is stored in the form of blocks in a Hadoop cluster. So the DataNode on which or the location at which that block of the file is stored is mentioned in MetaData. All information regarding the logs of the transactions happening in a Hadoop cluster (when or who read/wrote the data) will be stored in MetaData. MetaData is stored in the memory.
hadoop-daemon.sh start namenode
👁 starting and stopping namenode in Hadoophadoop-daemon.sh stop namenode
DataNode works on the Slave system. The NameNode always instructs DataNode for storing the Data. DataNode is a program that runs on the slave system that serves the read/write request from the client. As the data is stored in this DataNode, they should possess high memory to store more Data.
hadoop-daemon.sh start datanode
👁 starting and stopping a Datanode in Hadoophadoop-daemon.sh stop datanode
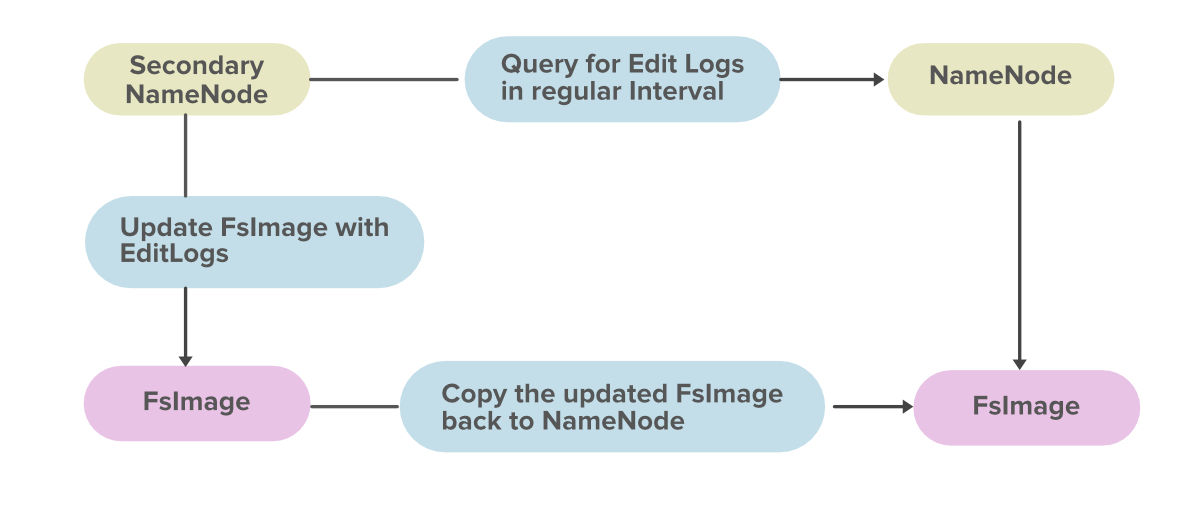
Secondary NameNode is used for taking the hourly backup of the data. In case the Hadoop cluster fails, or crashes, the secondary Namenode will take the hourly backup or checkpoints of that data and store this data into a file name fsimage. This file then gets transferred to a new system. A new MetaData is assigned to that new system and a new Master is created with this MetaData, and the cluster is made to run again correctly.
This is the benefit of Secondary Name Node. Now in Hadoop2, we have High-Availability and Federation features that minimize the importance of this Secondary Name Node in Hadoop2.
As secondary NameNode keeps track of checkpoints in a Hadoop Distributed File System, it is also known as the checkpoint Node.
👁 secondary-namenode| The Hadoop Daemon's | Port |
|---|---|
| Name Node | 50070 |
| Data Node | 50075 |
| Secondary Name Node | 50090 |
These ports can be configured manually in hdfs-site.xml and mapred-site.xml files.
Resource Manager is also known as the Global Master Daemon that works on the Master System. The Resource Manager Manages the resources for the applications that are running in a Hadoop Cluster. The Resource Manager Mainly consists of 2 things.
yarn-daemon.sh start resourcemanager
👁 start-stop-resource-manager in Hadoopstop:yarn-daemon.sh stop resourcemanager
The Node Manager works on the Slaves System that manages the memory resource within the Node and Memory Disk. Each Slave Node in a Hadoop cluster has a single NodeManager Daemon running in it. It also sends this monitoring information to the Resource Manager.
yarn-daemon.sh start nodemanager
👁 Hadoop Node Manager - how to start and stopyarn-daemon.sh stop nodemanager
In a Hadoop cluster, Resource Manager and Node Manager can be tracked with the specific URLs, of type http://:port_number
| The Hadoop Daemon's | Port |
|---|---|
| ResourceManager | 8088 |
| NodeManager | 8042 |
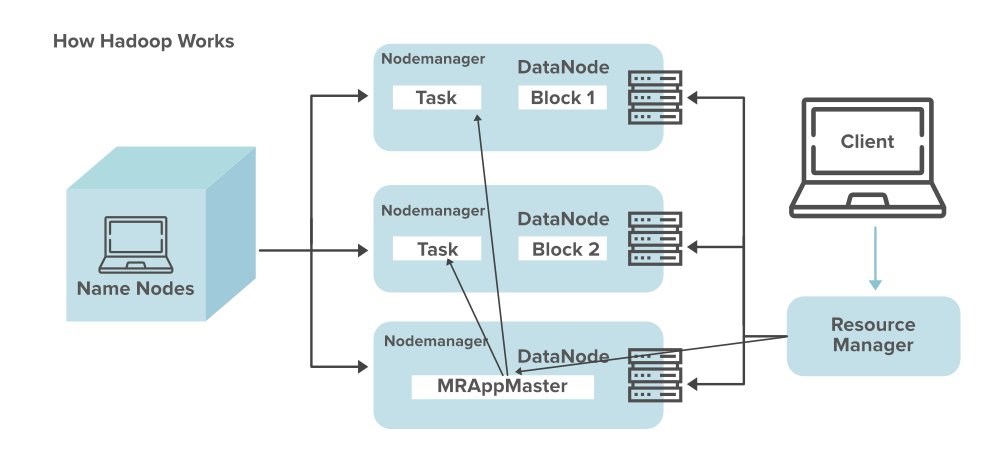
The below diagram shows how Hadoop works.
👁 How-Hadoop-Works{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}