 |
VOOZH | about |
|
VOOZH | about |
Before learning about HDFS (Hadoop Distributed File System), it’s important to understand what a file system is. A file system is a way an operating system organizes and manages files on disk storage. It helps users store, maintain, and retrieve data from the disk.
Example: Windows uses file systems like NTFS (New Technology File System) and FAT32 (File Allocation Table 32). FAT32 is an older file system but is still supported on versions like Windows XP. Similarly, Linux uses file systems such as ext3 and ext4.
DFS stands for distributed file system, it is a concept of storing file in multiple nodes in a distributed manner. DFS actually provides Abstraction for a single large system whose storage is equal to the sum of storage of other nodes in a cluster.
Storing very large files (e.g., 30TB) on a single system is impractical because:
Distributed File Systems (DFS) overcome these issues by storing data across multiple machines, enabling faster and scalable processing.
Example:
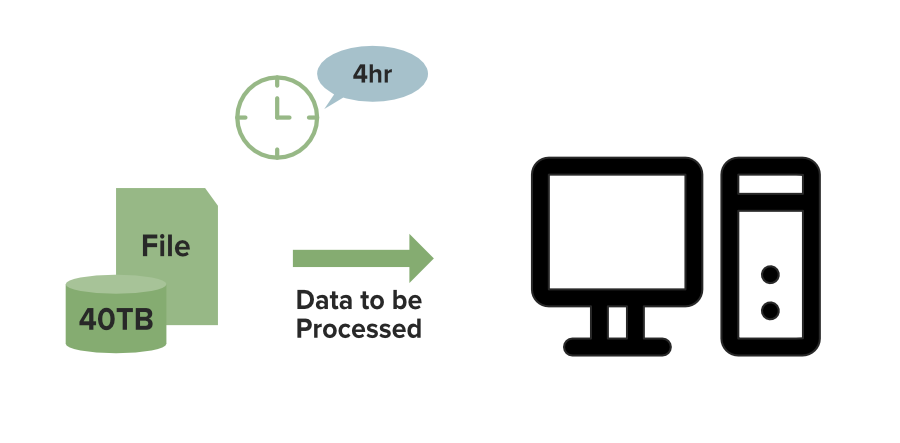
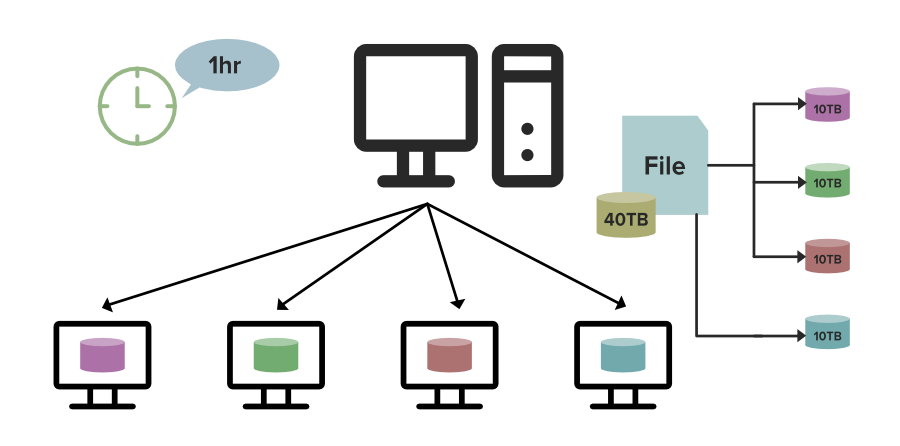
Suppose you have a 40TB file to process. On a single machine, it might take about 4 hours to complete. However, using a Distributed File System (DFS), as shown in the image below, 40TB file is split across 4 nodes in a cluster, with each node storing 10TB. Since all nodes work simultaneously, processing time reduces to just 1 hour. This demonstrates why DFS is essential for faster and efficient big data processing.
Local File System Processing:
👁 Local-File-System-Processing
Distributed File System Processing:
👁 Distributed-File-System-Processing
Now we think you become familiar with the term file system so let's begin with HDFS.
HDFS (Hadoop Distributed File System) is the main storage system in Hadoop. It stores large files by breaking them into blocks (default 128 MB) and distributing them across multiple low-cost machines.
HDFS ensures fault-tolerance by keeping copies of data blocks on different machines. This makes it reliable, scalable and ideal for handling big data efficiently.
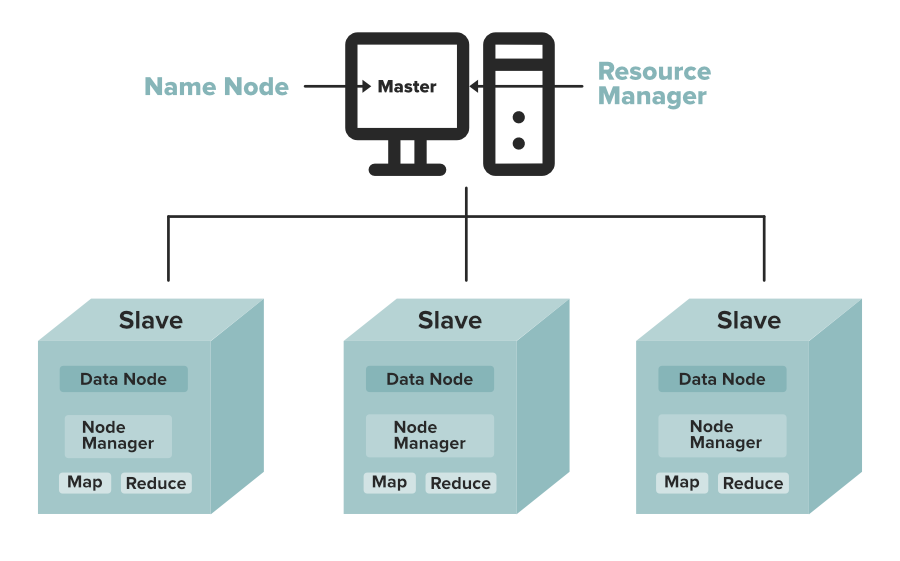
Hadoop follows a master-slave architecture using the MapReduce algorithm. Similarly, HDFS has two main components that follow this structure:
1. NameNode (Master):
The NameNode acts as the master of the Hadoop cluster. It is responsible for storing metadata — data about the actual data. This includes information like:
The NameNode manages and monitors the DataNodes and sends them instructions to create, delete or replicate data blocks. It also receives regular heartbeat signals and block reports from the DataNodes to ensure everything is functioning properly.
Since NameNode controls entire cluster, it requires high RAM and processing power to manage system efficiently.
2. DataNode (Slave):
The DataNodes act as slaves and are responsible for storing actual data blocks in Hadoop cluster. You can have dozens or even hundreds of DataNodes and more DataNodes mean more storage capacity.
Each DataNode performs tasks like creating, deleting or replicating data blocks all based on the instructions received from the NameNode. To store large files efficiently, DataNodes should have a high storage capacity.
{kind=link}
{kind=link}
{kind=link}
{kind=link}