A Data Lake is a centralized storage system that stores structured, semi-structured, and unstructured data in its raw format for flexible analysis. Unlike data warehouses, it follows a “store first, analyze later” approach, making it ideal for big data, machine learning, and real-time processing. It provides scalable, low-cost storage where analysts, engineers, and data scientists can use their own tools to extract insights.
Stores all data types and uses schema-on-read (structure applied during analysis).
Highly scalable with distributed storage like Hadoop HDFS, AWS S3, and Azure Data Lake Storage.
Cost-effective for storing massive volumes of raw data.
Supports advanced analytics, ML, streaming, and multiple user teams simultaneously.
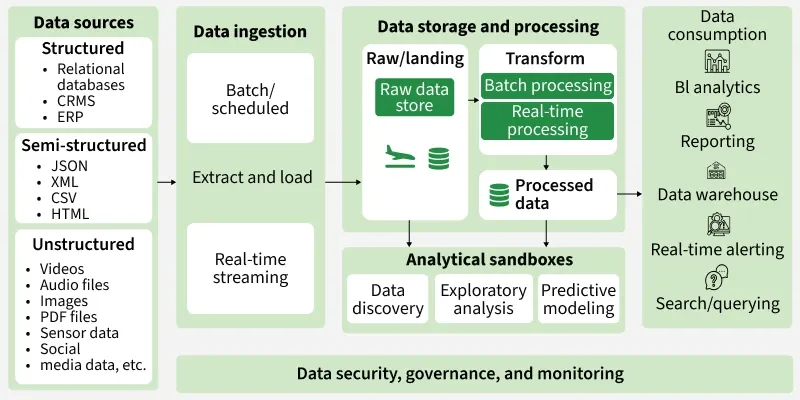
Data Lake Architecture
A typical data lake architecture consists of the following layers:
Tools: Power BI, Tableau, Spark SQL, Python/R notebooks, ML frameworks.
Data Lake vs Data Warehouse
Feature
Data Lake
Data Warehouse
Data Type
Structured, semi-structured, and unstructured data
Structured data only
Schema Approach
Schema-on-read (applied during analysis)
Schema-on-write (defined before storage)
Storage Cost
Low (object storage-based)
Higher (optimized structured storage)
Primary Use Case
Big Data, AI, ML, real-time analytics
Business Intelligence, reporting
Data Processing
ELT (Extract → Load → Transform)
ETL (Extract → Transform → Load)
Flexibility
Very high
Moderate
Performance
Raw storage, depends on processing engine
Optimized for fast SQL queries
Governance
Requires strong external governance
Built-in structure and control
Examples
AWS S3-based lakes, Hadoop HDFS
Amazon Redshift, Snowflake
Data Lake Zones
To keep data organized, data lakes are often divided into logical zones:
Raw Zone (Landing Zone): Stores unprocessed data exactly as received and no transformations are applied on it.
Cleansed Zone: Data is cleaned, validated, and standardized.
Curated/Trusted Zone: Analytics-ready, structured, and optimized data. Often converted to formats like Parquet for fast reads.
Sandbox/Workspace Zone: For data scientists to experiment with datasets without affecting production data.
Performance Optimization Strategies
To ensure efficiency:
Partition data (e.g., by date or region): Reduces the amount of data scanned by queries, improving speed and lowering costs.
Use columnar formats (Parquet, ORC): Stores data by columns instead of rows, enabling faster analytics and better compression.
Apply compression: Decreases storage size and reduces I/O operations, making queries more efficient.
Implement caching: Stores frequently accessed data in memory to minimize repeated data processing.
Optimize file sizes: Avoids too many small files or very large files, improving query performance and parallel processing.
Use indexing and clustering techniques: Organizes data intelligently so queries can locate relevant records fast.
Real-World Example
Consider an e-commerce company, in the company there are multiple data sources so the complete workflow given below:
Data Sources:
Website clickstreams
Payment transactions
Inventory databases
Customer reviews
Warehouse IoT sensors
Workflow:
Data is ingested via Kafka.
Stored in AWS S3.
Processed using Apache Spark.
Stored in curated zone (Parquet format).
Used for dashboards and ML fraud detection models.
This enables real-time analytics and predictive insight
Challenges of Data Lakes
Data Quality: Since Data Lakes store raw and unprocessed data there is a risk of poor data quality. Without proper governance data Lake will get filled with inconsistent or unreliable data.
Security Concerns: As they accumulate a vast amount of sensitive data ensuring robust security measures is crucial to prevent unauthorized access and data breaches.
Metadata Management: Managing all the metadata for large datasets can get tricky. Having a well-organized metadata store and data catalog is important for easily finding and understanding the data.
Integration Complexity: Bringing data from different sources together and making sure everything works smoothly can be difficult especially when the data comes in different formats and structures.
Skill Requirements: Implementing and managing a data lake requires specialized skills in big data technologies which can be a challenge for companies that don't have the right expertise.
Data Processing Frameworks
Apache Spark: A fast, distributed processing engine that supports in-memory computations. It provides APIs in Python, Java, Scala, and R, and is used for batch analytics, streaming, and machine learning.
Apache Hadoop: A framework designed for distributed storage and processing of massive datasets. It uses HDFS for storage and offers high scalability and fault tolerance.
Apache Flink: A real-time stream processing engine built for low-latency and high-throughput workloads. It supports event-time processing and can also run batch jobs.
Apache Storm: A real-time computation system used for processing data in motion. It is scalable, fault-tolerant, and integrates with various data sources for continuous analytics.
TensorFlow: An open-source machine learning framework used for building and training deep learning models. Often used in Data Lakes for advanced analytics and AI workloads.

{kind=link}
{kind=link}