 |
VOOZH | about |
|
VOOZH | about |
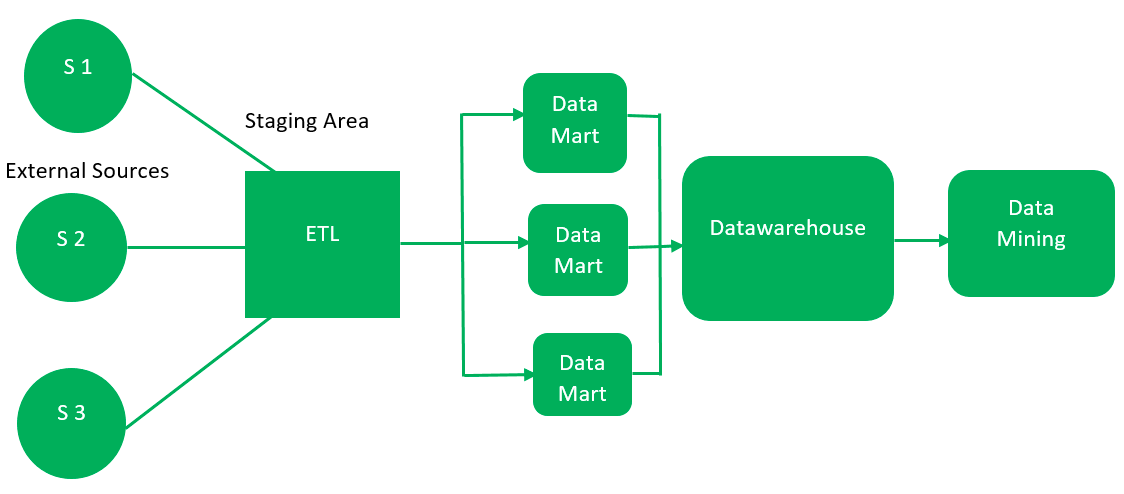
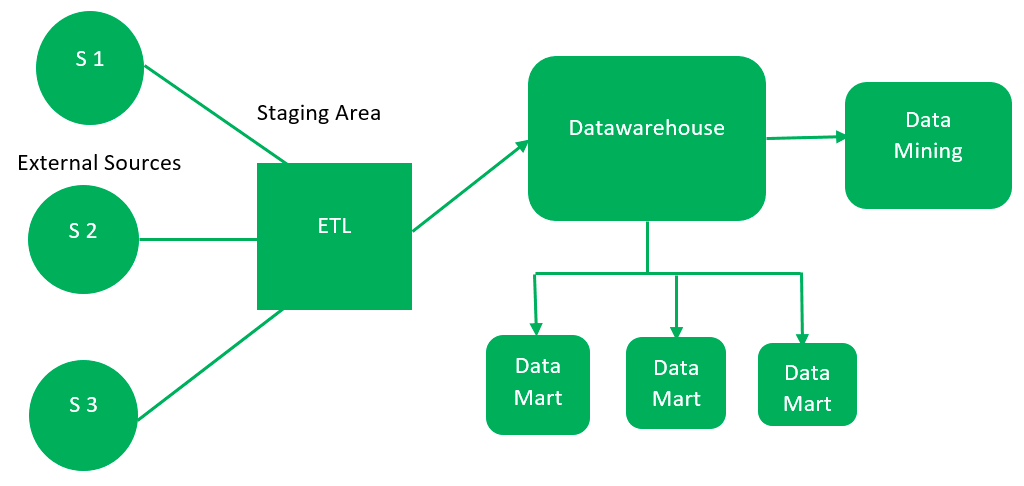
The architecture of warehouse includes different units such as sources, ETL, staging area, database, access layer and many more. In this article we will explore the typical data warehouse architecture and different models.
It is collection of data from different data sources in a unified schema. Also, data warehouse is digital storage used to store large amount of data from various data sources.
The different architecture components and layers of data warehouse are as follows:
Data warehouses integrate data from various sources with format option like structured, unstructured and semi-structured including the operational databases, transactional systems, external sources and many more.
The ETL extracts the data from data source, transform data into its consistent form used for analysis and load it into the data warehouse. These tools are also used to automate the cleansing, validation and aggregation of data.
In data warehouse architecture the area that provides an intermediate storage where the data is extracted from source and is temporarily stored before loading it into the data warehouse. The staging area allows data validation, error handling and integration of data from multiple sources.
The main component of data warehouse architecture is database. It stores the data in a structured format that optimizes the query processing and analysis. The data warehouse database consists of data marts, data cubes or different models that are used to enhance the different functions and analysis requirements.
The data access layer provides the techniques for users to interact with the data present in the data warehouse. It includes tools and interfaces like SQL queries, OLAP cubes, dashboards and data visualization software.
Metadata refers to as the data about data. It is an important component of typical data warehouse architecture. Metadata repository stores the information about the structure, relationships and other information of the data stored in the data warehouse. The metadata provides the data governance, data analysis and metadata-driven automation.
The data quality, consistency and integrity of data is important for good decision making. The data quality and governance techniques like data profiling, data cleansing, data lineage tracking, and access controls are collected into data warehouse architecture to provide data accuracy.
The scalability and performance optimization are required in the data warehouse architectures when the amount of data and user demands increases. The techniques like partitioning, indexing, compression and parallel processing to increase the performance and adapt increased workload.
The two data warehousing models are listed below.
The Kimball model is an alternative approach for data warehouse designing. This model focuses on flexibility, rapid development and easy to use by end users. The key characteristic of this model includes the dimensional modeling, bottom-up approach, user oriented, iterative and agile development, conformed dimensions, flexibility, scalability, integration with operational systems and many more.
The Inmon model is commonly used model to design data warehouses. It prioritizes on centralized and integrated approach in data warehouse designing. This model deals with single, wide source for data. The key characteristics of Inmon model includes centralized data repository, normalized data structure, data integration, subject oriented, scalability, flexibility, long-term history and separation of staging data and presentation layers.
From the above discussion we can conclude that the data warehouse has several components like data sources, ETL, databases, staging area, access layer etc. We have also discussed about data warehouse models: Kimball and Inmon and their key characteristics.
{kind=link}
{kind=link}
{kind=link}