 |
VOOZH | about |
|
VOOZH | about |
Given an input text and an array of k words, arr[], find all occurrences of all words in the input text. Let n be the length of text and m be the total number of characters in all words, i.e. m = length(arr[0]) + length(arr[1]) + ... + length(arr[k-1]). Here k is total numbers of input words.
Example:
Input: text = "ahishers"
arr[] = {"he", "she", "hers", "his"}
Output:
Word his appears from 1 to 3
Word he appears from 4 to 5
Word she appears from 3 to 5
Word hers appears from 4 to 7
If we use a linear time searching algorithm like KMP, then we need to one by one search all words in text[]. This gives us total time complexity as O(n + length(word[0]) + O(n + length(word[1]) + O(n + length(word[2]) + ... O(n + length(word[k-1]). This time complexity can be written as O(n*k + m).
Aho-Corasick Algorithm finds all words in O(n + m + z) time where z is total number of occurrences of words in text. The Aho–Corasick string matching algorithm formed the basis of the original Unix command fgrep.
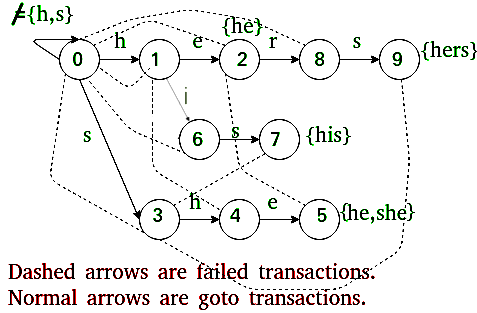
Go To : This function simply follows edges of Trie of all words in arr[]. It is represented as 2D array g[][] where we store next state for current state and character. Failure : This function stores all edges that are followed when current character doesn't have edge in Trie. It is represented as 1D array f[] where we store next state for current state. Output : Stores indexes of all words that end at current state. It is represented as 1D array o[] where we store indexes of all matching words as a bitmap for current state.
Preprocessing:
👁 Extending the Trie into an automaton to support linear time matching
Go to :
We build Trie. And for all characters which don't have an edge at root, we add an edge back to root.
Failure :
For a state s, we find the longest proper suffix which is a proper prefix of some pattern. This is done using Breadth First Traversal of Trie.
Output :
For a state s, indexes of all words ending at s are stored. These indexes are stored as bitwise map (by doing bitwise OR of values). This is also computing using Breadth First Traversal with Failure.
Below is the implementation of Aho-Corasick Algorithm
Word his appears from 1 to 3 Word he appears from 4 to 5 Word she appears from 3 to 5 Word hers appears from 4 to 7
Time Complexity: O(n + l + z), where ‘n’ is the length of the text, ‘l' is the length of keywords, and ‘z’ is the number of matches.
Auxiliary Space: O(l * q), where ‘q’ is the length of the alphabet since that is the maximum number of children a node can have.
Applications:
? Detecting plagiarism
? Text mining
? Bioinformatics
? Intrusion Detection
{kind=link}
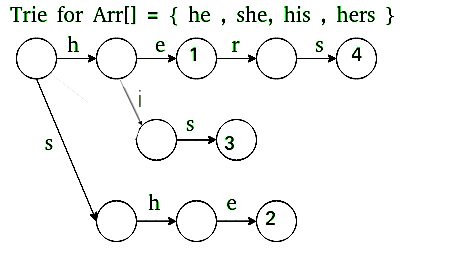{kind=link}
{kind=link}