Given a binary tree, determine whether the tree contains any duplicate subtree of size two or more. Two subtrees are considered duplicates if they have the same structure and identical node values. Return true if such a duplicate subtree exists; otherwise, return false.
Note: Subtrees consisting of only a single leaf node are not considered duplicate subtrees.
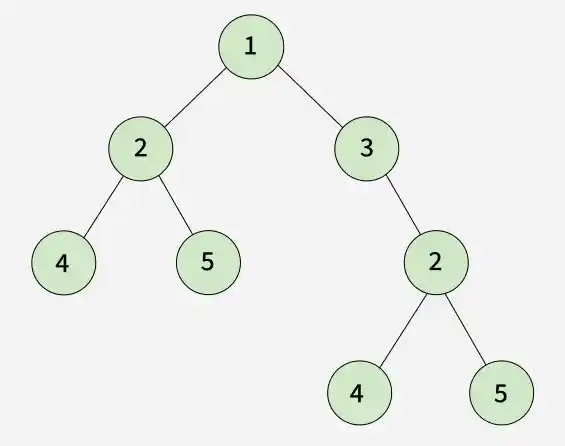
Example:
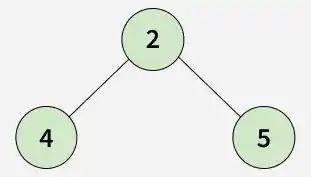
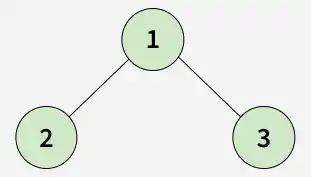
Input: root = [1, 2, 3, 4, 5, N, 2, N, N, N, N, 4, 5]
[Naive Approach] Generating All Subtrees - O(n ^ 2) Time and O(n ^ 2) Space
The idea is to generate all subtrees (of size greater than 1)of the binary tree and store their Serialized Form in an arrayor hash map. Then iterate through the array/map to check for duplicate subtrees.
Traverse the binary tree recursively in postorder fashion.
Serialize every subtree into a unique string representation.
For null nodes return "N" and for leaf nodes return their value.
Combine current node, left subtree, and right subtree strings to form the serialized subtree.
Store the frequency of every serialized subtree in a hash map.
After traversal, if any subtree frequency is greater than 1, return true; otherwise return false.
Output
True
[Optimized Approach] Early Termination DFS - O(n ^ 2) Time and O(n ^ 2) Space
The idea is to use a hash set to store the subtrees in Serialized String Form. For a given subtree of size greater than 1, if its equivalent serializedstring already exists, then return true. If all subtrees are unique, return false.
Traverse the binary tree using recursion in postorder fashion.
Serialize every subtree into a unique string representation.
For null nodes, return "N" and for leaf nodes return their value.
Combine current node, left subtree, and right subtree strings to form the serialization.
Check whether the serialized subtree already exists in the hash set.
If it already exists, return true; otherwise store it in the set and continue traversal.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}