Check if a Binary Tree is subtree of another Binary Tree
Last Updated : 9 May, 2026
Given two binary trees, a tree T (root1) with n nodes and a tree S (root2) with m nodes, check whether S is a subtree of T. A tree S is a subtree of T if it is formed by choosing any node in T and including all of its descendants. If S exactly matches any such subtree of T in both structure and node values, then it is considered a subtree.
[Naive Approach] Preorder Traversal with Subtree Matching - O(n*m) Time and O(n+m) Space
Traverse the main tree (root1) in preorder. At each node, treat it as a potential root and check whether the subtree rooted at this node is identical to root2. The identical check is done by recursively comparing both trees for matching structure and node values. Return true if a match is found at any node, otherwise, continue the traversal.
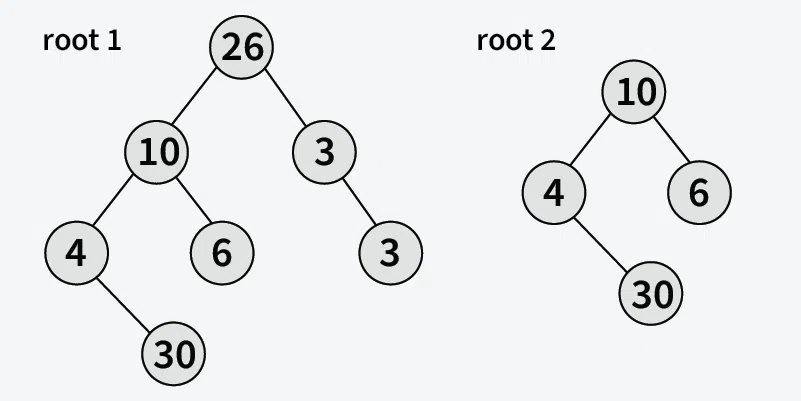
Consider the following tree for example to understand the flow.
Tree1 : [1, 2, 3] Tree2 : [2]
isSubTree(1, 2) --> areIdentical(1, 2) = false then check for left child or right child. isSubTree(2, 2) --> areIdentical(2, 2) = true --> return true. No need to check for right child if left is giving true.
areIdentical(2, 2) --> data is equal --> check for children areIdentical(NULL, NULL) --> true areIdentical(NULL, NULL) --> true therefore, return true.
Output
true
[Alternate Approach] Using String Serialisation & Substring Matching - O(n*m) Time and O(n+m) Space
Convert both trees into strings using preorder traversal, and include a special marker (like #) for every null node to preserve the exact structure of the tree. This ensures that different tree structures do not produce the same serialised string. Once both trees are serialised, check if the serialised string of root2 is a substring of the serialised string of root1. If it is found, then root2 is a subtree of root1.
Why this works?
Preorder traversal visits nodes in root => left => right order, so the relative position of each node is preserved in the serialised string.
Adding null markers (#) for missing children and a separator (,) for values ensure that the exact structure of the tree is captured along with the node values.
Because both node values and structure are recorded, each tree gets a unique serialised representation.
This prevents false matches, since two different trees cannot produce the same serialised string.
After serialisation, the subtree check reduces to a simple substring search between the two strings.
While serializing a binary tree with n nodes using preorder traversal, we include a null marker (#) for every null child.
A binary tree with n nodes has exactly (n+1) null child => (n+1) null markers. So, the serialized string contains n node values and (n + 1) null markers.
Total number of items = n + (n+1) = 2n + 1. We add separator (,) also to ensure that concatenation of two node values is not treated as a third value in the string. So total items become (2n + 1) + (2n for separators). Hence, space required = O(4n + 1) ≈ O(n).
Output
true
[Expected Approach] Using String Serialisation & KMP algorithm - O(n+m) Time and O(n+m) Space
This is mainly an optimization over the above approach. The idea is to use KMP algorithm for substring check to ensure that we have overall linear time complexity. Similar to this approach another methods can also be used for substring matching like Boyer–Moore and Trie-based matching.

{kind=link}
{kind=link}
{kind=link}