Given a binary tree, find all duplicate subtrees present in the tree. Two subtrees are considered duplicates if they have the same structure and identical node values at corresponding positions.
Return the root of each such tree in the form of a list.
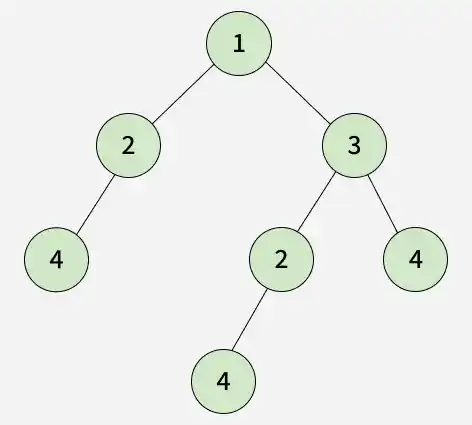
Output: 2 4 4 Explanation: The tree contains two duplicate subtrees: The subtree rooted at node 4. The subtree rooted at node 2 having left child 4. Therefore, the roots of the duplicate subtrees are 2 and 4.
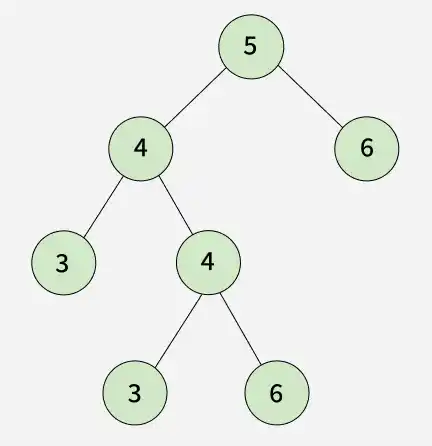
Output: 3 6 Explanation: The binary tree contains two duplicate subtrees: The subtree rooted at node 3 The subtree rooted at node 6 Both of these subtrees appear more than once in the tree with the same structure and node values.
Using Hash Map and Serialization - O(n ^ 2) Time and O(n ^ 2) Space
The idea is to serialize each subtree in the binary tree and use a hash map to keep track of the frequency of each serialized subtree. When a subtree's serialization appears more than once, it indicates a duplicate subtree, and the root node of such duplicate subtree is then added to the result list.
Traverse the binary tree recursively, starting from the root.
Serialize every subtree into a unique string representation.
For each node, combine left subtree, current node, and right subtree strings.
Store the frequency of every serialized subtree in a hash map.
If any subtree serialization appears for the second time, add its root node to the answer list.
Finally, return and print all duplicate subtrees stored in the result.
Output
4
2 4
Time Complexity: O(n^2) Since string copying takes O(n) extra time. Auxiliary Space: O(n^2) Since we are hashing a string for each node and length of this string can be of the order N.
Using Hash Map and Integer IDs - O(n) Time and O(n) Space
The idea of this approach is to avoid the time-consuming process of concatenating strings for subtree serialization by assigning a unique integer ID to each serialized subtree.
So the key that we use to do look up in hash table for duplicate subtrees becomes of constant length. Why? because it is combination of three integers (left subtree ID, root value and right subtree ID) separated by some constant number of separator characters.
We now mainly use two maps, one to store subtree and id mapping (with fixed length key explained above and a an integer id value), and other map with (ID as key and count as value). Whenever the count becomes 2, we add the subtree to result.
Traverse the binary tree recursively, starting from the root node.
Serialize each subtree using left subtree ID, current node value, and right subtree ID.
Use a hash map to assign a unique integer ID to every unique subtree serialization.
Store the frequency of each subtree ID in another hash map.
If any subtree ID appears for the second time, add its root node to the answer list.
Finally, return and print all duplicate subtrees stored in the result.
Output
4
2 4
Time Complexity: O(n) as each node is traversed only once and the string concatenation only involves three integers. Auxiliary Space: O(n) due to hash map.

{kind=link}
{kind=link}
{kind=link}
{kind=link}