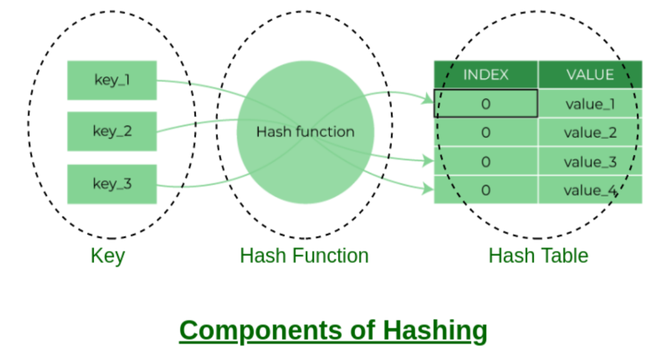
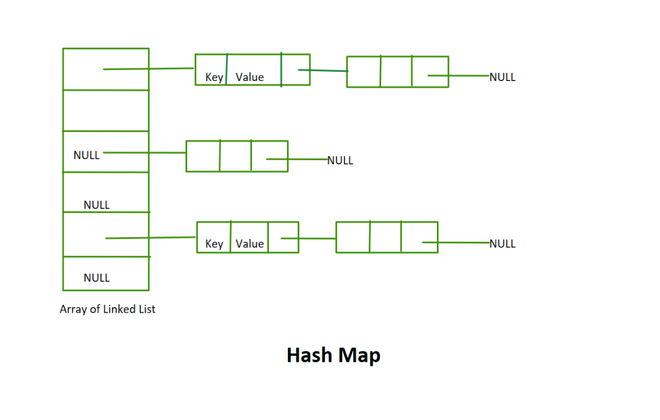
The value returned by the Hash function is the bucket index for a key in a separate chaining method. Each index in the array is called a bucket as it is a bucket of a linked list.
Rehashing
Rehashing is a technique used in hash tables to reduce collisions when the number of elements increases. In rehashing, a new hash table with larger capacity (usually double the previous size) is created, and all existing elements are reinserted using the updated hash function.
Note: Rehashing generally occurs when the load factor becomes greater than 0.5.
Steps in Rehashing
Double the size of the hash table.
Reinsert all existing elements into the new table using the hash function.
Delete the old table and replace it with the new one.
Load Factor Formula
Load Factor = Number of Elements / Total Number of Buckets
Collision
Collision is the situation when the bucket index is not empty. It means that a linked list head is present at that bucket index. We have two or more values that map to the same bucket index.

{kind=link}
{kind=link}
{kind=link}