 |
VOOZH | about |
|
VOOZH | about |
Data structures are ways to organize and store data so it can be used efficiently. They are essential in computer science for managing and processing information in programs. Common types of data structures include arrays, linked lists, stacks, queues, trees, and graphs. Each structure is designed for specific tasks, such as searching, sorting, or managing hierarchical data. Understanding data structures helps in solving problems faster and writing better algorithms.
Data structures are of two types:
1. Linear Data Structures: In linear data structures, elements are arranged in a sequential order. Each element is connected to its previous and next element, making traversal straightforward.
2. Non-Linear Data Structures: In non-linear data structures, elements are not arranged sequentially. They are connected in a hierarchical or network-like structure.
An array is a data structure used to store multiple elements of the same type in contiguous memory locations. Arrays are simple and widely used for organizing and managing data.
Declaration:
In C, we can declare an array by specifying its and size or by initializing it or by both.
// Array declaration by specifying size
int arr[10];
// Array declaration by initializing elements
int arr[] = {10, 20, 30, 40};
// Array declaration by specifying size and
// initializing elements
int arr[6] = {10, 20, 30, 40}
Initialization:
int arr[5] = {1, 2, 3, 4, 5};
Accessing Elements:
arr[0] = 10; // Assigns 10 to the first element
printf("%d", arr[2]); // Prints the third element
Formulas:
Length of Array = UB - LB + 1
1. One-Dimensional Array: Stores elements in a single row.
Example:
int arr[5] = {10, 20, 30, 40, 50};
2. Multi-Dimensional Array: Represents a matrix or table of data.
Example:
int matrix[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
Given the address of first element, address of any other element is calculated using the formula:-
Loc (arr [k]) = base (arr) + w * k
w = number of bytes per storage location
of for one element
k = index of array whose address we want
to calculate
Elements of two-dimensional arrays (mXn) are stored in two ways:-
Loc(arr[i][j]) = base(arr) + w (m *j + i)
Loc(arr[i][j]) = base(arr) + w (n*i + j)
for (int i = 0; i < 5; i++) {
printf("%d ", arr[i]);
}
O(n)O(log n)read more about - Arrays
A stack is a linear data structure that follows the Last In, First Out (LIFO) principle, meaning the element added last is removed first. It is widely used in programming for tasks such as expression evaluation, backtracking, and function call management.
1. Push: Adds an item in the stack. If the stack is full, then it is said to be an Overflow condition. (Top=Top+1). Time Complexity: O(1).
2. Pop: Removes an item from the stack. The items are popped in the reversed order in which they are pushed. If the stack is empty, then it is said to be an Underflow condition.(Top=Top-1). Time Complexity: O(1).
3. Peek: Retrieves the top element without removing it. Time Complexity: O(1).
Infix notation: X + Y - Operators are written in-between their operands. This is the usual way we write expressions. An expression such as
A * ( B + C ) / D
Postfix notation (also known as "Reverse Polish notation"): X Y + Operators are written after their operands. The infix expression given above is equivalent to
A B C + * D/
Prefix notation (also known as "Polish notation"): + X Y Operators are written before their operands. The expressions given above are equivalent to
/ * A + B C D
Conversion between these notations: Click here
Stacks can be implemented in C using:
It is a mathematical puzzle where we have three rods and n disks. The objective of the puzzle is to move the entire stack to another rod, obeying the following simple rules:
For n disks, total 2n – 1 moves are required
Time complexity : O(2n) [exponential time]
read more about - Stacks
A queue is a linear data structure that follows the First In, First Out (FIFO) principle. This means the element added first is removed first. Queues are widely used in scenarios like scheduling, buffering, and real-time systems.
O(1).O(n).Front: Get the front item from queue.
Rear: Get the last item from queue.
Queues can be implemented in C using:
read more about - Queues
A linked list is a linear data structure where elements (called nodes) are connected using pointers. Unlike arrays, linked lists do not store elements in contiguous memory locations, making them dynamic and flexible for insertion and deletion operations.
NULL.next and previous pointers form a circle.O(n).O(1) for insertion at the beginning, O(n) for insertion at the end or middle.O(1) for deletion at the beginning, O(n) for deletion at the end or middle.O(n).Each node in a list consists of at least two parts:
// A linked list node
struct node
{
int data;
struct node *next;
};
read more about - Linked List
A tree is a non-linear hierarchical data structure consisting of nodes connected by edges. Trees are widely used for organizing data and solving complex computational problems.
N children.Traversal refers to visiting all nodes in a tree. Common techniques are:
1. Inorder Traversal (Left, Root, Right)
(i) Traverse the left subtree of root in inorder.
(ii) Process the root.
(iii) Traverse the right subtree of root in inorder.
Example:
void inorder(struct Node* root) {
if (root != NULL) {
inorder(root->left);
printf("%d ", root->data);
inorder(root->right);
}
}
2. Preorder Traversal (Root, Left, Right)
(i) Process the root.
(ii) Traverse the left subtree of the root in preorder.
(iii) Traverse the right subtree of the root in preorder.
Example:
void preorder(struct Node* root) {
if (root != NULL) {
printf("%d ", root->data);
preorder(root->left);
preorder(root->right);
}
}
3.Post-order
(i) Traverse the left subtree of root in post-order.
(ii) Traverse the right subtree of root in post-order.
(iii) Process the root.
Example:
void postorder(struct Node* root) {
if (root != NULL) {
postorder(root->left);
postorder(root->right);
printf("%d ", root->data);
}
}
4. Level Order Traversal:
Visits nodes level by level (Breadth-First Search).
Example: Use a queue to implement this traversal.
O(log n) in a balanced tree; O(n) in a skewed treeA Binary Search Tree (BST) is a special type of binary tree where each node follows the binary search property:
Different Operations on Binary Search Tree are:
read more about - Binary Search Tree
A heap is a special tree-based data structure that satisfies the heap property:
50, 30, 20, 15, 10, 8, 16 (root = 50).10, 15, 20, 30, 50, 40 (root = 10).A heap is commonly implemented as a binary heap, where it is represented as a binary tree.
O(n log n).Heapify is an algorithm used to convert a binary tree into a heap. A heap is a special type of binary tree that satisfies the heap property, which can either be:
read more about - Heap
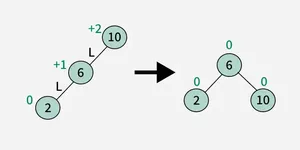
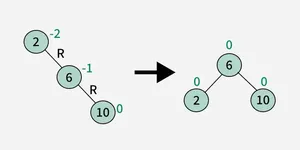
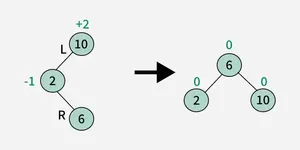
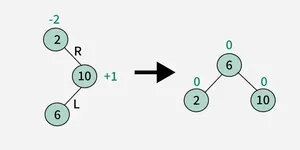
An AVL Tree is a type of self-balancing binary search tree (BST). Named after its inventors, Adelson-Velsky and Landis, it ensures that the height difference (balance factor) between the left and right subtrees of every node is at most 1. This balancing helps maintain efficient operations such as insertion, deletion, and searching
1. Left-Left (LL) Rotation :
2. Right-Right (RR) Rotation :
3. Left-Right (LR) Rotation :
4. Right-Left (RL) Rotation :
Here's a table that outlines various tree operations (like insertion, deletion, etc.) for different types of trees, along with their time complexities:
| Operation | Binary Tree | Binary Search Tree (BST) | Heap | AVL Tree |
|---|---|---|---|---|
| Insertion | O(1) (if position is given) | O(log n) | O(log n) | O(log n) |
| Deletion | O(1) (if node is given) | O(log n) | O(log n) | O(log n) |
| Search | O(n) | O(log n) | O(n) (for unsorted) | O(log n) |
| Traversal | O(n) | O(n) | O(n) | O(n) |
| Balance Check | O(n) | O(n) | N/A | O(log n) |
| Height Calculation | O(n) | O(n) | O(n) | O(log n) |
read more about - AVL Tree
A graph is a non-linear data structure consisting of vertices (nodes) and edges that connect pairs of vertices. Graphs are widely used to represent relationships between objects in various real-world scenarios like social networks, road maps, and web pages.
1. Depth First Search (DFS): Traverses as deep as possible along a branch before backtracking. Uses a stack (recursion or explicit).
Example:
2. Breadth First Search (BFS): Traverses all neighbors of a vertex before moving to the next level.
Example:
read more about - Graphs
Hashing is a technique used to map data of arbitrary size to fixed-size values, called hash values or hash codes, using a hash function. It is widely used in computer science for quick data retrieval and efficient storage.
1. Chaining: Uses linked lists to store multiple elements in the same bucket. Each bucket points to a linked list of elements with the same hash value.
2. Open Addressing: All elements are stored directly in the hash table. On collision, the algorithm probes the table to find an empty slot.
Probing Techniques:
index = (hash + i) % table_size index = (hash + i^2) % table_size index = (hash1 + i * hash2) % table_sizeread more about - Hashing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}