 |
VOOZH | about |
|
VOOZH | about |
Given an array of strings arr[], return the longest common prefix among each and every strings present in the array. If there’s no prefix common in all the strings, return “”.
Input: arr[] = [“geeksforgeeks”, “geeks”, “geek”, “geezer”]
Output: “gee”
Explanation: “gee” is the longest common prefix in all the given strings: “geeksforgeeks”, “geeks”, “geeks” and “geezer”.Input: arr[] = [“apple”, “ape”, “april”]
Output : “ap”
Explanation: “ap” is the longest common prefix in all the given strings: “apple”, “ape” and “april”.Input: arr[] = [“hello”, “world”]
Output: “”
Explanation: There’s no common prefix in the given strings.
Table of Content
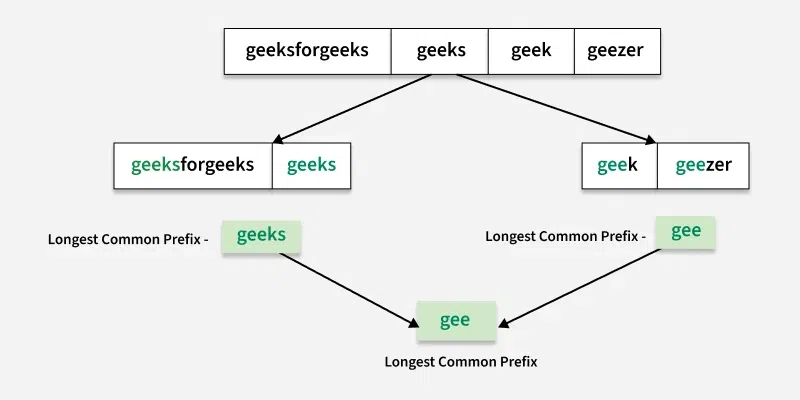
The idea is to sort the array of strings and find the common prefix of the first and last string of the sorted array. Sorting is used in this approach because it makes it easier to find the longest common prefix. When we sort the strings, the first and last strings in the sorted list will be the most different from each other in terms of their characters. So, the longest common prefix for all the strings must be a prefix of both the first and the last strings in the sorted list.
Algorithm:
gee
Time Complexity: O(n*m*log n), to sort the array, where n is the number of strings and m is the length of longest string.
Auxiliary Space: O(m) to store the strings first, last and result.
The idea is to iterate character by character from index 0 and take the current character from the first string as reference. For each position, we compare this character with the corresponding character in all other strings. If all characters match, we add it to the result; otherwise, we stop immediately and return the prefix formed so far.
Algorithm:
gee
The idea is simple, first divide the array of strings into two equal parts. Then find the Longest Common Prefix for all strings in each part individually using recursion. Once we got the Longest Common Prefix of both parts, the Longest Common Prefix of this array will be Longest Common Prefix of these two parts.
Algorithm:
p1 and p2 character by character. gee
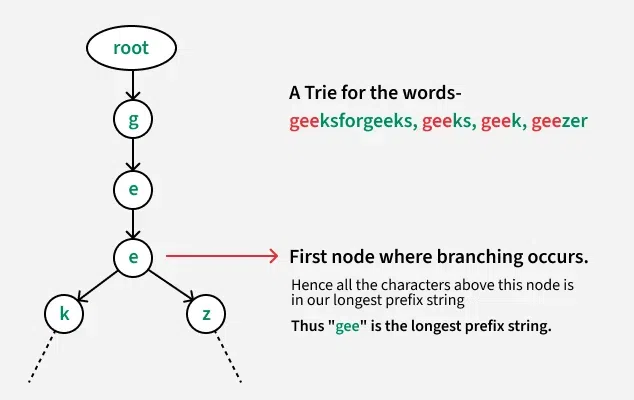
The idea is to insert all the string one by one in the trie. After inserting we perform a walk on the trie. In this walk, we go deeper until we find a node having more than 1 children(branching occurs) or 0 children (one of the string gets exhausted). This is because the characters (nodes in trie) which are present in the longest common prefix must be the single child of its parent, i.e- there should not be branching in any of these nodes.
Algorithm:
gee
{kind=link}
{kind=link}
{kind=link}
{kind=link}