 |
VOOZH | about |
|
VOOZH | about |
Given two strings text (the text) and pattern (the pattern), consisting of lowercase English alphabets, find all 0-based starting indices where pattern occurs as a substring in text.
Examples:
Input: text = "geeksforgeeks", pattern = "geeks"
Output: [0, 8]
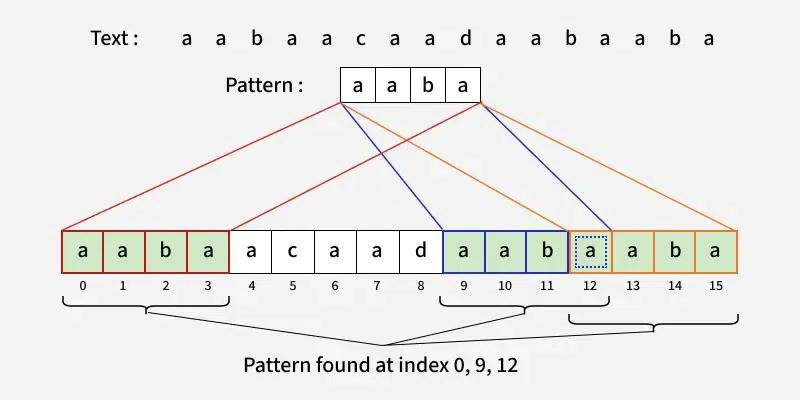
Explanation: The string "geeks" occurs at index 0 and 8 in text.Input: text = "aabaacaadaabaaba", pattern = "aaba"
👁 kmp-algorithm-for-pattern-searching
Output: [0, 9, 12]
Explanation:
In the Naive String Matching algorithm, we check whether every substring of the text of the pattern's size is equal to the pattern or not one by one.
Like the Naive Algorithm, the Rabin-Karp algorithm also check every substring. But unlike the Naive algorithm, the Rabin Karp algorithm matches the hash value of the pattern with the hash value of the current substring of text. So Rabin Karp algorithm has the following step
- Compute the hash of the pattern
- Compare pattern's hash with the hashes of all substrings (of same length as pattern) of the text. If the hashes match, we do a character-by-character check to confirm (to avoid errors due to hash collisions).
The hash value is calculated using a rolling hash function, which allows you to update the hash value for a new substring by efficiently removing the contribution of the old character and adding the contribution of the new character. This makes it possible to slide the pattern over the text and calculate the hash value for each substring without recalculating the entire hash from scratch.
For a string s of length m, the simple hash is
hash(s) = (s[0] × d(m−1) + s[1] × d(m−2) + ... + s[m−1] × d0) % q
Here,
s[i] represents the ASCII value of the character ('a' = 97, 'b' = 98, ..., 'z' = 122)
d is the size of the input alphabet (commonly 256 for ASCII characters)
q is a prime number used as modulus (commonly 101, 1000000007, etc.)Using modulo helps prevent integer overflow and reduces hash collisions.
So we know hash values s[i-1, j-1] and now we need to compute for s[i..j].
Previous value of hash
The hash value of substring s[i−1 … j−1] is: (s[i-1] * d(m-1) + s[i] * d(m-2) + ... + s[j-1] * d0) mod q
New value of hash
The hash value of the next substring s[i … j] is: (s[i] * d(m-1) + s[i+1] * d(m-2) + ... + s[j] * d0 ) mod q
From the above expressions, it is clear that we can get new value from old value by removing the term s[i-1] * d(m-1) and adding the term s[j] * d0)
hash(i, j) = (d * (hash(i−1, j−1) − s[i−1] * d(m−1) )+ s[j]) mod q
Here's how the hash value is typically calculated in Rabin-Karp:
0 8
Time Complexity:
Auxiliary Space: O(1)
{kind=link}
{kind=link}
{kind=link}