Given a linked list sorted in non-decreasing order.Return the list bydeleting the duplicate nodes from the list. The returned list should also be in non-decreasing order.
Example:
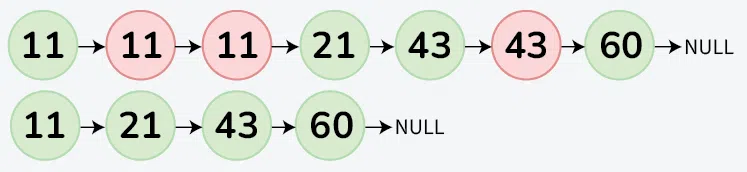
Input : Linked List = 11->11->11->21->43->43->60 Output : 11->21->43->60 Explanation:
[Naive Approach] Using Hash Set – O(n) Time and O(n) Space
The idea is to traverse the linked list and check if the value is present in HashSet or not. If the value is not present in the HashSet then push the value in HashSet append the nodes in the new list , otherwise skip the value as it is the duplicate value.
Follow the steps below to solve the problem:
Initialize an empty Hash Set and pointers new_head and tail as NULL.
Iterate through the original list, adding each unique node's value to the HashSet and appending the node to the new list.
Return the new_head of the new list with duplicates removed.
Output
11 11 11 13 13 20
11 13 20
[Expected Approach] By Changing Next Pointer – O(n) Time and O(1) Space
The idea is to traverse the linked list and for each node, if the next node has the same data, skip and delete the duplicate node.
Follow the steps below to solve the problem:
Traverse the linked list starting from the head node.
Iterate through the list, comparing each node with the next node.
If the data in the next node is same as the curr node adjust pointers to skip the next node.
Output
11 11 11 13 13 20
11 13 20
[Alternate Approach] Using Recursion – O(n) Time and O(n) Space
The idea is similar to the iterative approach. Here we are using the recursion to check each nodeand its next for duplicates. Please note that the iterative approach would be better in terns of time and space. The recursive approach can be good fun exercise or a question in an interview / exam.
Follow the steps below to solve the problem:
If the curr node or its next node is NULL, return the curr node.
If the current node’s data equals the next node’s data, adjust pointers to skip the duplicate.
If no duplicate, recursively process the next node.

{kind=link}
{kind=link}
{kind=link}