 |
VOOZH | about |
|
VOOZH | about |
Given two strings, s1 and s2, find the length of the Longest Common Subsequence. If there is no common subsequence, return 0. A subsequence is a string generated from the original string by deleting 0 or more characters, without changing the relative order of the remaining characters.
For example, subsequences of "ABC" are "", "A", "B", "C", "AB", "AC", "BC" and "ABC". In general, a string of length n has 2n subsequences.
Examples:
Input: s1 = "ABC", s2 = "ACD"
Output: 2
Explanation: The longest subsequence which is present in both strings is "AC".Input: s1 = "AGGTAB", s2 = "GXTXAYB"
Output: 4
Explanation: The longest common subsequence is "GTAB".Input: s1 = "ABC", s2 = "CBA"
Output: 1
Explanation: There are three longest common subsequences of length 1, "A", "B" and "C".
Table of Content
The idea is to compare the last characters of s1 and s2. While comparing the strings s1 and s2 two cases arise:
For example, consider the input strings s1 = "ABX" and s2 = "ACX".
LCS("ABX", "ACX") = 1 + LCS("AB", "AC") [Last Characters Match]
LCS("AB", "AC") = max( LCS("A", "AC") , LCS("AB", "A") ) [Last Characters Do Not Match]
LCS("A", "AC") = max( LCS("", "AC") , LCS("A", "A") ) = max(0, 1 + LCS("", "")) = 1
LCS("AB", "A") = max( LCS("A", "A") , LCS("AB", "") ) = max( 1 + LCS("", "", 0)) = 1
So overall result is 1 + 1 = 2
4
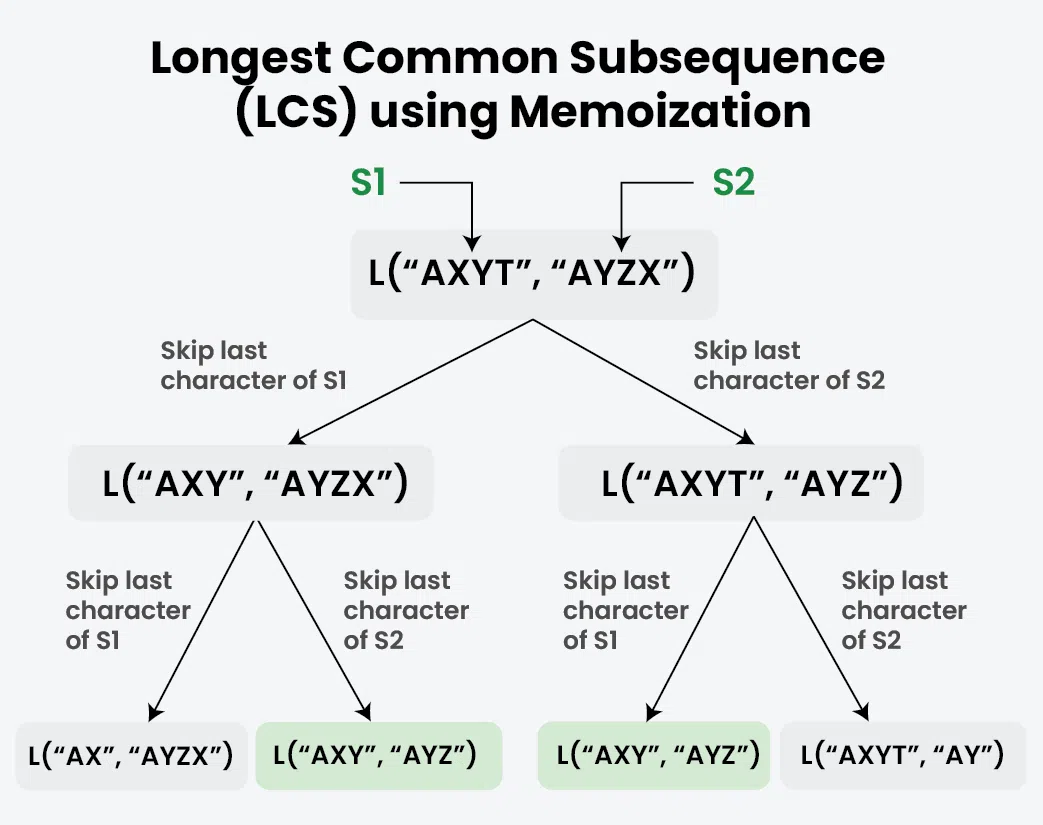
If we use the above recursive approach for strings "AXYT" and "AYZX", we will get a partial recursion tree as shown below. Here we can see that the subproblem L("AXY", "AYZ") is being calculated more than once. If the total tree is considered there will be several such overlapping subproblems. Hence we can optimize it either using memoization or tabulation.
4
There are two parameters that change in the recursive solution and these parameters go from 0 to m and 0 to n. So we create a 2D dp array of size (m+1) x (n+1).
- We first fill the known entries when m is 0 or n is 0.
- Then we fill the remaining entries using the recursive formula.
Say the strings are S1 = "AXTY" and S2 = "AYZX", Follow below :
4
O(n * m) Time O(m) SpaceOne important observation in the above simple implementation is, in each iteration of the outer loop we only need values from all columns of the previous row. So there is no need to store all rows in our dp matrix, we can just store two rows at a time and use them. In that way, used space will be reduced from dp[m+1][n+1] to dp[2][n+1].
The recurrence relation for the Longest Common Subsequence (LCS) problem is:
If the last character of s1 and s2 match:
- dp[i][j] = 1 + dp[i-1][j-1]
if the last characters of s1 and s2 do not match, we take the maximum of two cases:
1. exclude the last character of s1
2. exclude the last char of s2
- dp[i][j] = max(dp[i-1][j],dp[i][j-1])
Base Case: when the length of either s1 or s2 is 0, LCS is 0.
- for i = 0 or j = 0 dp[i][j] = 0
In the recurrance relation one things that we can observe is for finding the current state dp[i][j] we don't need to store the entire table, we only need to store the current row and the previous row because each value at position (i, j) in the table only depends on:
- The value directly above it (dp[i-1][j]),
- The value directly to the left (dp[i][j-1]),
- The value diagonally left above it (dp[i-1][j-1]).
Since only the previous row and the current row are required to compute the LCS, we can reduce the space by using just two rows instead of the entire table. We use a 2D array of size 2 x (n+1) to store only two rows at a time.
We have used two array to store the previous and current row, prev for previous row and curr for current row, once the iteration for current row is done, we will set prev = curr, so that curr row can serve as prev for next index.
4
Time Complexity : O(n * m), where m is the length of string s1 and n is the length of string s2.
Auxiliary Space: O(m), Only two 1D arrays are used, each of size m+1.
In this approach, the auxiliaryspace is further optimized by using a single DP array, where:
dp[j] represents the value of dp[i-1][j] (previous row's value) before updating. During the computation, dp[j] is updated to represent the current row value dp[i][j]
Now the recurrance relations become:
- if the characters s1[i-1] and s2[j-1] match, dp[j] = 1+ prev. Here, prev is a temporary variable storing the diagonal value (dp[i-1][j-1]).
- If the characters don't match, dp[j] = max(dp[j-1], dp[j]). Here dp[j] represents the value of dp[i-1][j] before updating and dp[j-1] represents the value of dp[i-1][j].
4
{kind=link}
{kind=link}
{kind=link}