 |
VOOZH | about |
|
VOOZH | about |
Given a string, find the longest substring which is palindrome.
We have already discussed Naïve [O(n3)], quadratic [O(n2)] and linear [O(n)] approaches in Set 1, Set 2 and Manacher’s Algorithm.
In this article, we will discuss another linear time approach based on suffix tree.
If given string is S, then approach is following:
Can you see why we say that LCS in R and S must be from same position in S ?
Let's look at following examples:
We can see that LCS and LPS are not same always. When they are different ?
When S has a reversed copy of a non-palindromic substring in it which is of same or longer length than LPS in S, then LCS and LPS will be different.
In 2nd example above (S = abacdfgdcaba), for substring abacd, there exists a reverse copy dcaba in S, which is of longer length than LPS aba and so LPS and LCS are different here. Same is the scenario in 4th example.
To handle this scenario we say that LPS in S is same as LCS in S and R given that LCS in R and S must be from same position in S.
If we look at 2nd example again, substring aba in R comes from exactly same position in S as substring aba in S which is ZERO (0th index) and so this is LPS.
The Position Constraint:
We will refer string S index as forward index (Si) and string R index as reverse index (Ri).
Based on above figure, a character with index i (forward index) in a string S of length N, will be at index N-1-i (reverse index) in it's reversed string R.
If we take a substring of length L in string S with starting index i and ending index j (j = i+L-1), then in it's reversed string R, the reversed substring of the same will start at index N-1-j and will end at index N-1-i.
If there is a common substring of length L at indices Si (forward index) and Ri (reverse index) in S and R, then these will come from same position in S if Ri = (N - 1) - (Si + L - 1) where N is string length.
So to find LPS of string S, we find longest common string of S and R where both substrings satisfy above constraint, i.e. if substring in S is at index Si, then same substring should be in R at index (N - 1) - (Si + L - 1). If this is not the case, then this substring is not LPS candidate.
Naive [O(N*M2)] and Dynamic Programming [O(N*M)] approaches to find LCS of two strings are already discussed here which can be extended to add position constraint to give LPS of a given string.
Now we will discuss suffix tree approach which is nothing but an extension to Suffix Tree LCS approach where we will add the position constraint.
While finding LCS of two strings X and Y, we just take deepest node marked as XY (i.e. the node which has suffixes from both strings as it's children).
While finding LPS of string S, we will again find LCS of S and R with a condition that the common substring should satisfy the position constraint (the common substring should come from same position in S). To verify position constraint, we need to know all forward and reverse indices on each internal node (i.e. the suffix indices of all leaf children below the internal nodes).
In Generalized Suffix Tree of S#R$, a substring on the path from root to an internal node is a common substring if the internal node has suffixes from both strings S and R. The index of the common substring in S and R can be found by looking at suffix index at respective leaf node.
If string S# is of length N then:
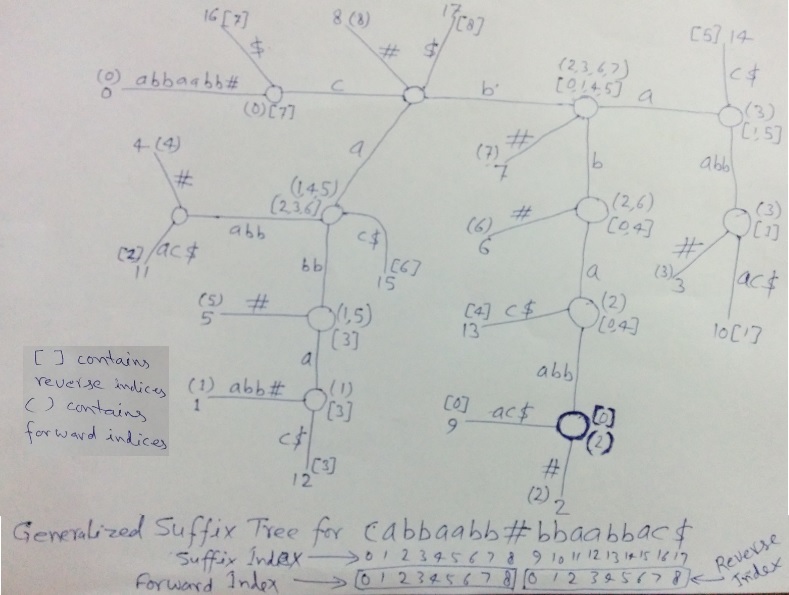
Let's take string S = cabbaabb. The figure below is Generalized Suffix Tree for cabbaabb#bbaabbac$ where we have shown forward and reverse indices of all children suffixes on all internal nodes (except root).
Forward indices are in Parentheses () and reverse indices are in square bracket [].
In above figure, all leaf nodes will have one forward or reverse index depending on which string (S or R) they belong to. Then children's forward or reverse indices propagate to the parent.
Look at the figure to understand what would be the forward or reverse index on a leaf with a given suffix index. At the bottom of figure, it is shown that leaves with suffix indices from 0 to 8 will get same values (0 to 8) as their forward index in S and leaves with suffix indices 9 to 17 will get reverse index in R from 0 to 8.
For example, the highlighted internal node has two children with suffix indices 2 and 9. Leaf with suffix index 2 is from position 2 in S and so it's forward index is 2 and shown in (). Leaf with suffix index 9 is from position 0 in R and so it's reverse index is 0 and shown in []. These indices propagate to parent and the parent has one leaf with suffix index 14 for which reverse index is 4. So on this parent node forward index is (2) and reverse index is [0,4]. And in same way, we should be able to understand the how forward and reverse indices are calculated on all nodes.
In above figure, all internal nodes have suffixes from both strings S and R, i.e. all of them represent a common substring on the path from root to themselves. Now we need to find deepest node satisfying position constraint. For this, we need to check if there is a forward index Si on a node, then there must be a reverse index Ri with value (N – 2) – (Si + L – 1) where N is length of string S# and L is node depth (or substring length). If yes, then consider this node as a LPS candidate, else ignore it. In above figure, deepest node is highlighted which represents LPS as bbaabb.
We have not shown forward and reverse indices on root node in figure. Because root node itself doesn't represent any common substring (In code implementation also, forward and reverse indices will not be calculated on root node)
How to implement this approach to find LPS? Here are the things that we need:
One way to do above is:
While DFS on suffix tree, we can store forward and reverse indices on each node in some way (storage will help to avoid repeated traversals on tree when we need to know forward and reverse indices on a node). Later on, we can do another DFS to look for nodes satisfying position constraint. For position constraint check, we need to search in list of indices.
What data structure is suitable here to do all these in quickest way ?
We will use two unordered_set (one for forward and other from reverse indices) in our implementation, added as a member variable in SuffixTreeNode structure.
Output:
Longest Palindromic Substring in cabbaabb is: bbaabb, of length: 6
Longest Palindromic Substring in forgeeksskeegfor is: geeksskeeg, of length: 10
Longest Palindromic Substring in abcde is: a, of length: 1
Longest Palindromic Substring in abcdae is: a, of length: 1
Longest Palindromic Substring in abacd is: aba, of length: 3
Longest Palindromic Substring in abcdc is: cdc, of length: 3
Longest Palindromic Substring in abacdfgdcaba is: aba, of length: 3
Longest Palindromic Substring in xyabacdfgdcaba is: aba, of length: 3
Longest Palindromic Substring in xababayz is: ababa, of length: 5
Longest Palindromic Substring in xabax is: xabax, of length: 5
Time complexity: O(n)
Auxiliary Space: O(n)
Followup:
Detect ALL palindromes in a given string.
e.g. For string abcddcbefgf, all possible palindromes are a, b, c, d, e, f, g, dd, fgf, cddc, bcddcb.
We have published following more articles on suffix tree applications:
{kind=link}
{kind=link}
{kind=link}