 |
VOOZH | about |
|
VOOZH | about |
Text files can be compressed to make them smaller and faster to send, and unzipping files on devices has a low overhead. The process of encoding involves changing the representation of a file so that the (binary) compressed output takes less space to store and takes less time to transmit while retaining the ability to reconstruct the original file exactly from its compressed representation. Text files can be of various file types, such as HTML, JavaScript, CSS, .txt, and so on. Text compression is required because uncompressed data can take up a lot of space, which is inconvenient for device storage and file sharing.
The size of the text file can be reduced by compressing it, which converts the text to a smaller format that takes up less space. It typically works by locating similar strings/characters within a text file and replacing them with a temporary binary representation to reduce the overall file size. There are two types of file compression,
Text encoding is also of two types:
The two methods differ in the length of the codes. Analysis shows that variable-length encoding is much better than fixed-length encoding. Characters in variable-length encoding are assigned a variable number of bits based on their frequency in the given text. As a result, some characters may require a single bit, while others may require two bits, while still others may require three bits, and so on.
During the encoding process in compression, every character can be assigned and represented by a variable-length binary code. But, the problem with this approach is its decoding. At some point during the decoding process, two or more characters may have the same prefix of code, causing the algorithm to become confused. Hence, the "prefix rule" is used which makes sure that the algorithm only generates uniquely decodable codes. In this way, none of the codes are prefixed to the other and hence the uncertainty can be resolved.
Hence, for text file compression in this article, we decide to leverage an algorithm that gives lossless compression and uses variable-length encoding with prefix rule. The article also focuses on regenerating the original file using the decoding process.
We use the Huffman Coding algorithm for this purpose which is a greedy algorithm that assigns variable length binary codes for each input character in the text file. The length of the binary code depends on the frequency of the character in the file. The algorithm suggests creating a binary tree where all the unique characters of a file are stored in the tree's leaf nodes.
This way, a Huffman tree for a particular text file can be created.
We've talked about variable length input code generation and replacing it with the file's original characters so far. However, this only serves to compress the file. The more difficult task is to decompress the file by decoding the binary codes to their original value.
This would necessitate the addition of some additional information to our compressed file in order to use it during the decoding process. As a result, we include the characters in our file, along with their corresponding codes. During the decoding process, this aids in the recreation of the Huffman tree.
The structure of a compressed file:
| Number of unique characters in the input file |
| Total number of characters in the input file |
| All characters with their binary codes (To be used for decoding) |
| Storing binary codes by replacing the characters of the input file one by one |
In this manner, we recover all of the characters from our input file into a newly decompressed file with no data or quality loss.
Following the steps above, we can compress a text file and then overcome the bigger task of decompressing the file to its original content without any data loss.
Time Complexity: O(N * logN) where N is the number of unique characters as an efficient priority queue data structure takes O(logN) time per insertion, a complete binary tree with N leaves has (2*N - 1) nodes.
Opening Input/Output Files:
Function to Initialize and Create Min Heap:
Function to Build and Create a Huffman Tree:
Recursive Function to Print Binary Codes into Compressed File:
Function to Compress the File by Substituting Characters with their Huffman Codes:
Function to Build Huffman Tree from Data Extracted from Compressed File:
Function to Decompress the Compressed File:
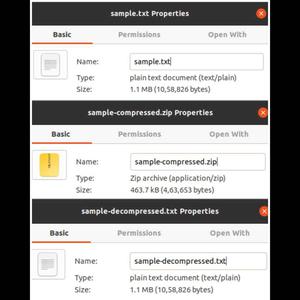
When the snippets of code above are combined to form a full implementation of the algorithm and a large corpus of data is passed to it, the following results can be obtained. It clearly demonstrates how a text file can be compressed with a ratio greater than 50% (typically 40-45%) and then decompressed without losing a single byte of data.
{kind=link}
{kind=link}