Gossip Protocol is a decentralized method used in distributed systems to spread information among nodes through periodic and random communication.
- Keeps all nodes updated in large systems.
- Removes the need for a central coordinator.
👁 algebraic1
Gossip ProtocolImportance
- Scalability: Removes the need for a centralized master node, preventing bottlenecks in large systems.
- Fault Tolerance: System continues functioning even if some nodes fail, as other nodes keep spreading updates.
- Adaptability to Network Changes: Handles dynamic environments where nodes frequently join, leave, or change network topology.
- Eventual Consistency: Ensures all nodes gradually reach the same state, even if there are delays or failures.
Characteristics
- Decentralized Communication: No central controller; every node participates equally in spreading information.
- Random Peer Selection: Each node selects peers randomly to share updates, ensuring uniform distribution.
- Periodic Communication Rounds: Nodes exchange information at regular time intervals called gossip rounds.
- Eventual Convergence: After several rounds, all nodes gradually reach the same consistent state.
Working Mechanism
Step-wise Working
1. Random Peer Selection
- A node selects one or more peers randomly.
- Selection happens during each gossip round.
2. Information Exchange
- The node shares its current state or updates.
- The peer merges or updates its own state.
3.Propagation Through Rounds
- Updated peers repeat the same process.
- Information spreads exponentially across nodes.
4. Network Convergence
- After multiple rounds, most nodes receive the update.
- Eventually, all nodes reach a consistent state.
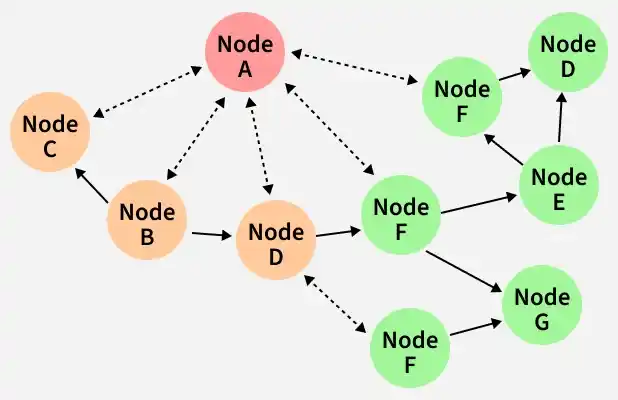
Small Example
- Node A detects a failure.
- A shares this update with Node B and C.
- B and C further spread it to other nodes.
- Within a few rounds, the entire cluster knows about the failure
Types of Gossip Protocol
1. Push Model
A node that has new information sends the update to randomly selected peers during each gossip round.
- Sender initiates communication.
- Peers receive updates without requesting them.
- Fast spread in early stages.
- May cause redundant transmissions later.
2. Pull Model
A node requests information from randomly selected peers to check for updates.
- The receiver initiates communication.
- Updates are shared only when requested.
- Reduces unnecessary message exchange.
- Slower when a few nodes initially have updates.
3. Push–Pull Model
Nodes send both their updates and request from peers in the same gossip round.
- Combines push and pull mechanisms.
- Speeds up convergence.
- More balanced communication.
- Commonly used in practical distributed systems.
Anti-Entropy Mechanism
It is a gossip-based synchronization technique where nodes periodically compare and reconcile their data to eliminate inconsistencies.
- Nodes randomly select peers to compare their state.
- Missing or outdated data is exchanged and updated.
- Focuses on correcting differences between replicas.
- Ensures eventual consistency across the system.
- May involve higher data transfer due to full state comparison.
Rumor-Mongering (Epidemic Spreading)
This is a gossip technique where new information is spread quickly, like a rumor from one node to others.
- A node forwards new updates to random peers.
- Peers continue spreading the update further.
- Propagation happens for limited gossip rounds.
- Spreads information rapidly in early stages.
- Stops once most nodes are aware of the update.
Anti-Entropy vs Rumor-Mongering
| Anti-Entropy | Rumor-Mongering (Epidemic) |
|---|
| Synchronizes full data between nodes. | Spreads specific new updates like a rumor. |
| Compares node states to find differences. | Forwards received updates to random peers. |
| Ensures stronger eventual consistency. | Focuses on fast initial propagation. |
| May exchange larger amounts of data. | Usually sends smaller update messages. |
| Used for data reconciliation. | Used for quick notification spreading. |
Applications
- Failure Detection: Identifies crashed or unreachable nodes by spreading heartbeat information.
- Membership Management: Maintains and updates the list of active nodes in the system.
- Data Replication: Distributes data updates among multiple replicas to keep them synchronized.
- Distributed Databases: Shares cluster state and node information (e.g., in Cassandra).
- Blockchain Networks: Propagate transactions and newly created blocks across the network.
Advantages
- Highly Scalable: Works efficiently even when the number of nodes increases significantly.
- Fault Tolerant: Continues functioning even if some nodes fail.
- Low Coordination Overhead: Does not require complex synchronization or central control.
- Simple Implementation: Easy to design and integrate into distributed systems.
- Balanced Load Distribution: Communication load is shared among all nodes.
Disadvantages
- Probabilistic Guarantees: Does not guarantee immediate or deterministic delivery.
- Bandwidth Overhead: Repeated message exchanges can increase network traffic.
- Slower Convergence in Large Networks: May take more rounds in very large systems.
- Eventual Consistency Only: Not suitable for systems requiring strong consistency.
- Redundant Message Transmission: Some nodes may receive the same update multiple times.

{kind=link}
{kind=link}