 |
VOOZH | about |
|
VOOZH | about |
Question 1
Register renaming is done in pipelined processors
as an alternative to register allocation at compile time
for efficient access to function parameters and local variables
to handle certain kinds of hazards
as part of address translation
Question 2
Consider two processors P1 and P2 executing the same instruction set. Assume that under identical conditions, for the same input, a program running on P2 takes 25% less time but incurs 20% more CPI (clock cycles per instruction) as compared to the program running on P1. If the clock frequency of P1 is 1GHz, then the clock frequency of P2 (in GHz) is _________.
1.6
3.2
1.2
0.8
Question 3
On a non-pipelined sequential processor, a program segment, which is a part of the interrupt service routine, is given to transfer 500 bytes from an I/O device to memory.
Initialize the address register
Initialize the count to 500
LOOP: Load a byte from device
Store in memory at address given by address register
Increment the address register
Decrement the count
If count != 0 go to LOOP
Assume that each statement in this program is equivalent to machine instruction which takes one clock cycle to execute if it is a non-load/store instruction. The load-store instructions take two clock cycles to execute. The designer of the system also has an alternate approach of using DMA controller to implement the same transfer. The DMA controller requires 20 clock cycles for initialization and other overheads. Each DMA transfer cycle takes two clock cycles to transfer one byte of data from the device to the memory. What is the approximate speedup when the DMA controller based design is used in place of the interrupt driven program based input-output?
3.4
4.4
5.1
6.7
Question 4
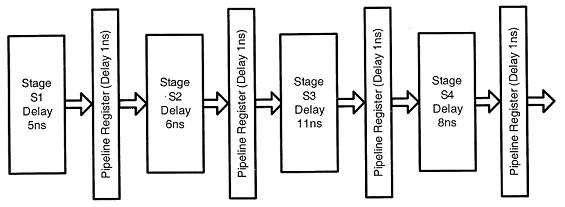
Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure:
👁 GATECS2011Q41
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
4.0
2.5
1.1
3.0
Question 5
A 5-stage pipelined processor has Instruction Fetch(IF),Instruction Decode(ID),Operand Fetch(OF),Perform Operation(PO)and Write Operand(WO)stages.The IF,ID,OF and WO stages take 1 clock cycle each for any instruction.The PO stage takes 1 clock cycle for ADD and SUB instructions,3 clock cycles for MUL instruction,and 6 clock cycles for DIV instruction respectively.Operand forwarding is used in the pipeline.What is the number of clock cycles needed to execute the following sequence of instructions?
Instruction Meaning of instruction
I0 :MUL R2 ,R0 ,R1 R2 ¬ R0 *R1
I1 :DIV R5 ,R3 ,R4 R5 ¬ R3/R4
I2 :ADD R2 ,R5 ,R2 R2 ¬ R5+R2
I3 :SUB R5 ,R2 ,R6 R5 ¬ R2-R6
13
15
17
19
Question 6
Consider a 4 stage pipeline processor. The number of cycles needed by the four instructions I1, I2, I3, I4 in stages S1, S2, S3, S4 is shown below:
S1 | S2 | S3 | S4 | |
I1 | 2 | 1 | 1 | 1 |
I2 | 1 | 3 | 2 | 2 |
I3 | 2 | 1 | 1 | 3 |
I4 | 1 | 2 | 2 | 2 |
What is the number of cycles needed to execute the following loop? For (i=1 to 2) {I1; I2; I3; I4;}
16
23
28
30
Question 7
If we use internal data forwarding to speed up the performance of a CPU (R1, R2 and R3 are registers and M[100] is a memory reference), then the sequence of operations
A
B
C
D
Question 8
Consider the following reservation table for a pipeline having three stages S1, S2 and S3.
Time -->
-----------------------------
1 2 3 4 5
-----------------------------
S1 | X | | | | X |
S2 | | X | | X | |
S3 | | | X | | |
The minimum average latency (MAL) is __________
3
2
1
4
Question 9
Consider the following data path of a simple non-pilelined CPU. The registers A, B, A1, A2, MDR, the bus and the ALU are 8-bit wide. SP and MAR are 16-bit registers. The MUX is of size 8 × (2:1) and the DEMUX is of size 8 × (1:2). Each memory operation takes 2 CPU clock cycles and uses MAR (Memory Address Register) and MDR (Memory Date Register). SP can be decremented locally.
The CPU instruction “push r”, where = A or B, has the specification
M [SP] ← r
SP ← SP – 1
How many CPU clock cycles are needed to execute the “push r” instruction?
1
3
4
5
Question 10
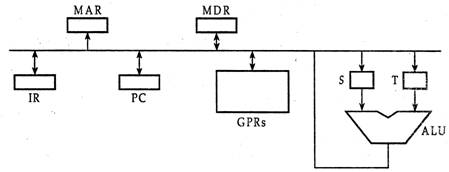
Consider the following data path of a CPU.
👁 LightboxThe, ALU, the bus and all the registers in the data path are of identical size. All operations including incrementation of the PC and the GPRs are to be carried out in the ALU. Two clock cycles are needed for memory read operation - the first one for loading address in the MAR and the next one for loading data from the memory bus into the MDR 79.
The instruction “call Rn, sub” is a two word instruction. Assuming that PC is incremented during the fetch cycle of the first word of the instruction, its register transfer interpretation is
Rn < = PC + 1;
PC < = M[PC];
The minimum number of clock cycles needed for execution cycle of this instruction is.
2
3
4
5
There are 49 questions to complete.
{kind=link}
{kind=link}
{kind=link}
{kind=link}