Scalability in distributed systems is the ability of a system to handle increasing workload, users, or data without degrading performance or reliability.
Prevents system slowdown or failure during peak usage.
Ensures performance remains stable even when demand increases.
Scalable System
It is a system that can handle increasing workload, users, or data volume without a significant drop in performance or reliability.
Can support more users, requests, or transactions as demand grows.
Keeps response time and throughput stable even under heavy load.
Continues functioning correctly without frequent failures or downtime.
Uses CPU, memory, storage, and network resources effectively when scaling.
Types of Scalability
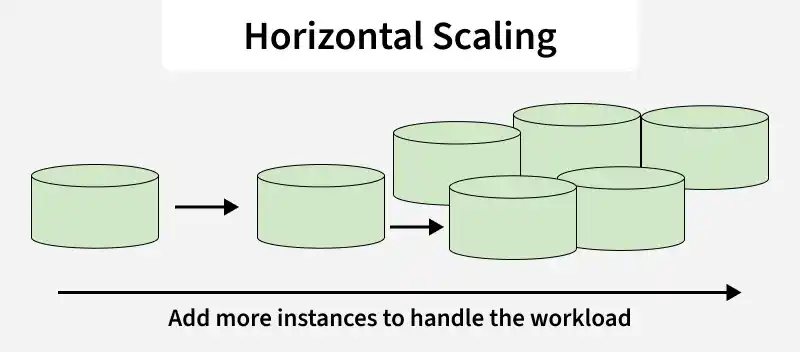
1. Horizontal Scalability (Scaling Out)
This involves adding more machines or nodes to a distributed system to handle increased load or demand.
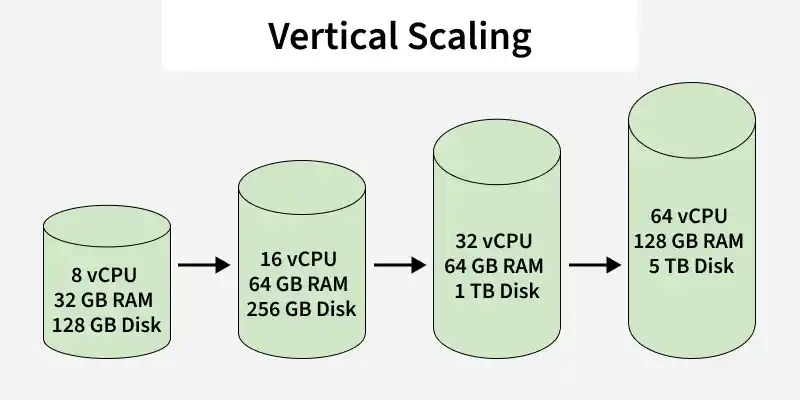
Upgrade Hardware: To scale vertically, upgrade the hardware of an existing server by adding more RAM, faster CPUs, or additional storage.
Single Node Focus: Vertical scaling focuses on enhancing the capabilities of a single node rather than adding more nodes.
Examples:
Upgrading a database server with more RAM and a faster processor to handle increased query loads.
Increasing the CPU and memory of an application server to improve its performance under higher user demand.
Metrics for Measuring Scalability
Throughput: It measures the amount of work a system can process in a given time.
Latency: It is the time taken for a request to travel from client to server and back.
Response Time: Response time is the total time required to complete a request.
Resource Utilization: Measures how efficiently system resources are used.
Speedup and Efficiency: Measures how much faster a system becomes when additional resources are added.
Key Characteristics
1. Load Balancing
It distributes incoming requests across multiple servers.
Prevents overloading of a single node
Improves system performance and response time
Enhances availability and fault tolerance
Ensures efficient utilization of resources
2. Stateless Design (Where Possible)
Each request is processed independently without storing session data on the server.
Simplifies horizontal scaling
Allows any server to handle any request
Reduces dependency between nodes
Improves fault tolerance and flexibility
3. Replication
Maintaining copies of data or services across multiple nodes.
Increases availability
Improves read performance
Provides backup in case of node failure
Supports fault tolerance in distributed systems
4. Partitioning (Sharding)
This divides large datasets into smaller parts distributed across different nodes.
Reduces load on a single database
Improves query performance
Supports large-scale data handling
Enables parallel processing
5. Decentralization
Decentralization removes reliance on a single central node.
Eliminates a single point of failure
Improves system reliability
Supports independent node operation
Enhances scalability across geographic regions
Architectural Patterns for Scalable Distributed Systems
1. Client-Server Architecture
In the client-server architecture, the system is divided into two main components: clients and servers. The client requests resources or services from the server, which processes the requests and returns the results.
Centralized Management: Servers manage resources, data, and services centrally, while clients interact with them.
Scalability Approaches:
Scaling the Server: Adding more resources (CPU, memory) to the server to handle increased load.
Scaling the Clients: Increasing the number of clients that can connect to the server without requiring server changes.
Challenges:
Single Point of Failure: If the server fails, all clients are affected.
Load Bottlenecks: As the number of clients increases, the server might become a performance bottleneck.
2. Microservices Architecture
The microservices architecture involves breaking down an application into small, independent services that communicate through well-defined APIs. Each microservice focuses on a specific business capability.
Modularity: Each service is responsible for a specific function and can be developed, deployed, and scaled independently.
Scalability Approaches:
Service Scaling: Scale individual services based on their load and requirements, rather than scaling the entire application.
Elastic Scaling: Automatically adjust the number of service instances based on demand.
Challenges:
Complexity: Managing multiple services and their interactions can be complex.
Inter-Service Communication: Ensuring reliable and efficient communication between services can be challenging.
3. Peer-to-Peer Architecture
In a peer-to-peer (P2P) architecture, nodes (peers) in the network have equal roles and responsibilities. Each peer can act as both a client and a server, sharing resources directly with other peers.
Decentralization: No single central server; each node contributes resources and services.
Scalability Approaches:
Distributed Load: Workload and data are distributed across all peers, allowing for scalability as more peers join.
Self-Healing: Nodes can join or leave the network without affecting overall functionality.
Challenges:
Data Consistency: Ensuring data consistency and synchronization across all peers can be difficult.
Security: Managing security and trust between peers requires careful consideration.
4. Event-Driven Architecture
Event-driven architecture (EDA) focuses on the production, detection, and reaction to events. Components (producers) generate events, and other components (consumers) respond to these events asynchronously.
Asynchronous Communication: Events are handled independently of the sender and receiver, allowing for decoupled and scalable interactions.
Scalability Approaches:
Event Streaming: Use event streaming platforms to manage and process large volumes of events in real-time.
Event Processing: Scale event processing systems to handle increased event traffic and processing requirements.
Challenges:
Event Management: Managing event flows and ensuring timely processing can be complex.
Event Ordering: Ensuring the correct order and handling of events, especially in distributed systems, requires careful design.
Design Principles for Building Scalable Systems
Scalable systems are built using architectural principles that allow them to handle growth efficiently while maintaining performance and reliability.
1. Avoid Single Point of Failure (SPOF)
A single point of failure is a component whose failure can stop the entire system.
Use redundancy for critical components
Deploy multiple servers instead of one
Implement failover mechanisms
Ensure high availability through replication
2. Use Caching Mechanisms
Caching stores frequently accessed data temporarily for faster retrieval.
Reduces load on databases
Improves response time
Minimizes repeated computations
Useful for read-heavy applications
3. Asynchronous Communication
Asynchronous systems process tasks without blocking other operations.
Improves system responsiveness
Reduces waiting time between services
Enables background processing
Suitable for distributed and event-driven systems
4. Microservices Architecture
Microservices divide an application into smaller, independent services.
Each service scales independently.
Easier to manage large applications
Improves fault isolation
Supports distributed deployment
5. Elastic Resource Provisioning
Elastic provisioning automatically adjusts resources based on demand.
Scale up during high traffic.c
Scale down during low usage
Optimizes cost and performance
Common in cloud-based systems
Scalability vs Elasticity
Scalability and elasticity are related concepts in distributed systems, but they are not the same. Both deal with handling workload changes, but their approach differs.
Scalability refers to the ability of a system to handle an increasing workload by adding resources.
Elasticity refers to the ability of a system to automatically adjust resources up or down based on real-time demand.
Scalability
Elasticity
Ability to handle growth in workload
Ability to automatically adjust resources based on demand
Focuses on increasing system capacity
Focuses on dynamic resource adjustment
Can be manual or planned scaling
Usually automatic scaling
Supports long-term growth
Handles short-term fluctuations
Common in distributed and large-scale systems
Common in cloud-based environments
Challenges in Scalability
While scalability improves system capacity and performance, it also introduces several technical and operational challenges in distributed systems.
1. Data Consistency Issues
Maintaining consistent data across multiple nodes becomes difficult as the system scales.
Replicated data must remain synchronized.
Delays in updates can cause stale data
Strong consistency reduces performance
Trade-offs often required (e.g., consistency vs availability)
2. Network Overhead
As more nodes are added, communication between them increases.

{kind=link}
{kind=link}
{kind=link}