
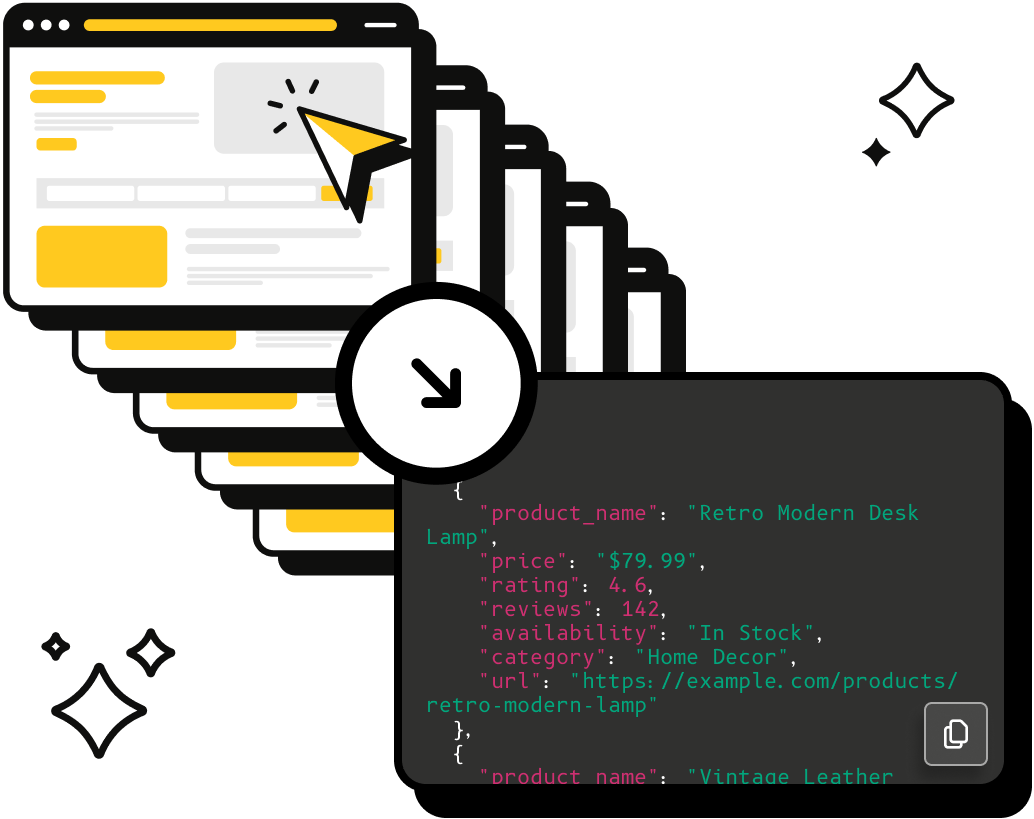
Data Scraping API
Extracting data has never been more simple with CSS or XPATH selectors and ScrapingBee.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
👁 Quote symbol
{kind=link}
ScrapingBee simplified our day-to-day marketing and engineering operations a lot. We no longer have to worry about managing our own fleet of headless browsers, and we no longer have to spend days sourcing the right proxy provider
We will parse all this HTML so you don't have to
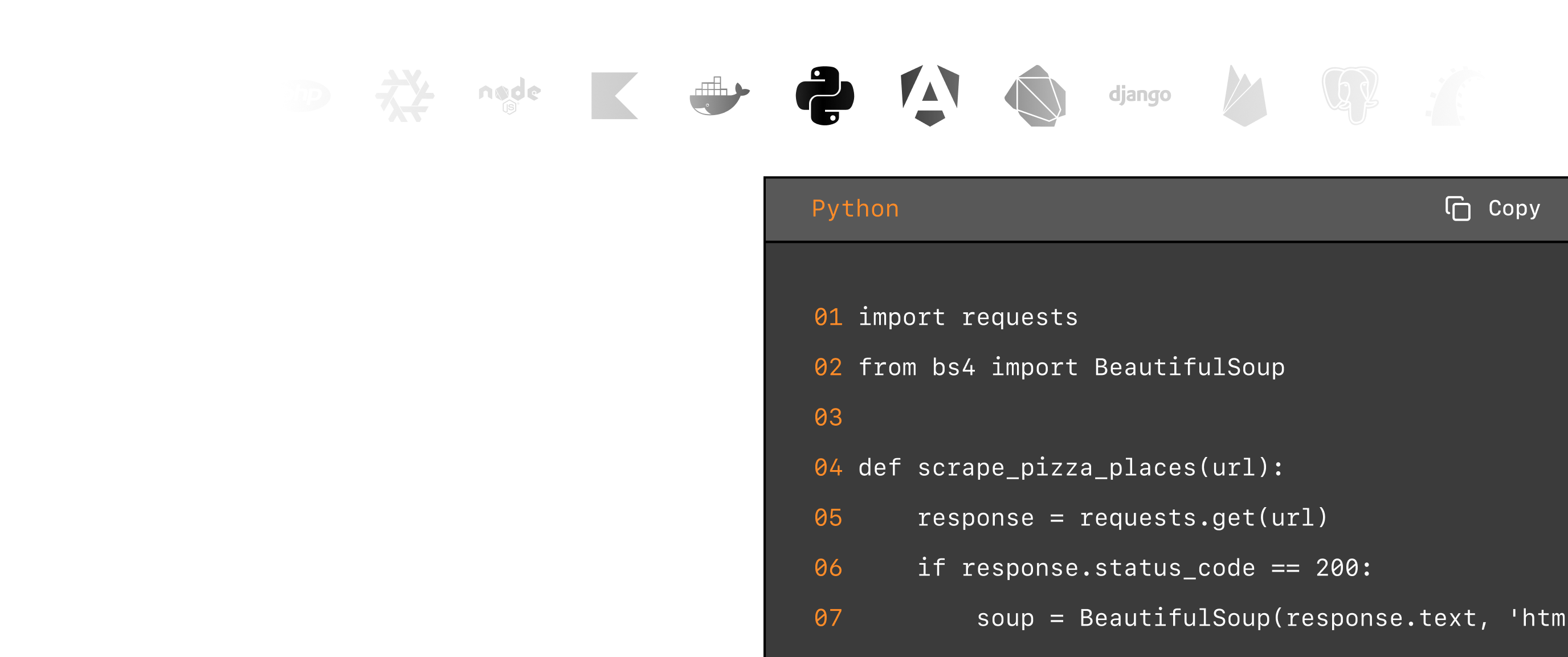
Code
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get(
'https://www.scrapingbee.com/blog',
params={
'extract_rules':{
"title" : "h1",
"subtitle" : "#subtitle",
"articles": {
"selector": ".card",
"type": "list",
"output": {
"title": ".post-title",
"link": ".post-title@href",
"description": ".post-description"
}
}
},
},
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.json())
const axios = require('axios');
axios.get('https://app.scrapingbee.com/api/v1/', {
headers: {
'Authorization': 'Bearer YOUR-API-KEY'
},
params: {
'url': 'https://www.scrapingbee.com/blog',
'extract_rules': {
"title": "h1",
"subtitle": "#subtitle",
"articles": {
"selector": ".card",
"type": "list",
"output": {
"title": ".post-title",
"link": ".post-title@href",
"description": ".post-description"
}
}
}
}
})
.then(function (response) {
console.log('Response HTTP Status Code: ', response.status);
console.log('Response HTTP Response Body: ', response.data);
});
<?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://app.scrapingbee.com/api/v1/?url=https://www.scrapingbee.com/blog&extract_rules={"title":"h1","subtitle":"#subtitle","articles":{"selector":".card","type":"list","output":{"title":".post-title","link":".post-title@href","description":".post-description"}}}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Authorization: Bearer YOUR-API-KEY'
));
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response = curl_exec($ch);
if (!$response) {
die('Error: "' . curl_error($ch) . '" - Code: ' . curl_errno($ch));
}
echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo 'Response HTTP Response Body: ' . $response . PHP_EOL;
curl_close($ch);
?>
{kind=link}
{kind=link}
{kind=link}
Response
# Response HTTP Status Code: 200
{
"title": "The ScrapingBee Blog",
"subtitle": "We help you get better at web-scraping: detailed tutorial, case studies and writing by industry experts",
"articles": [
{
"title": " Block ressources with Puppeteer - (5min)",
"link": "https://www.scrapingbee.com/blog/block-requests-puppeteer/",
"description": "This article will show you how to intercept and block requests with Puppeteer using the request interception API and the puppeteer extra plugin."
},
...
{
"title": " Web Scraping vs Web Crawling: Ultimate Guide - (10min)",
"link": "https://www.scrapingbee.com/blog/scraping-vs-crawling/",
"description": "What is the difference between web scraping and web crawling? That's exactly what we will discover in this article, and the different tools you can use."
},
]
}
Extraction from simple CSS selector
Nested extraction
Attribute extraction
Full page rendering
Output cleaning
Developer Experience
Top-rated support &
documentation
Our team is here to guide you when you need the extra assistance. And we're constantly working on new features to make your life easier.
{kind=link}
{kind=link}
👁 Image
{kind=link}
Knowledge base
Our extensive knowledge base covers the most frequent use cases with code samples.
{kind=link}
ScrapingBee helps us to retrieve information from sites that use very sophisticated mechanism to block unwanted traffic, we were struggling with those sites for some time now and I'm very glad that we found ScrapingBee.👁 Image
Anton R ★★★★★ CTO (see it on Capterra)
{kind=link}
ScrapingBee simplified our day-to-day marketing and engineering operations a lot. We no longer have to worry about managing our own fleet of headless browsers, and we no longer have to spend days sourcing the right proxy provider👁 Image
Mike Ritchie CEO @SeekWell
So easy to set-up, straightforward and performance. They are reachable and kind, they introduced us properly their tool and offered the best solution for our need.👁 Image
Maxime Y ★★★★★ Product Manager @ NordFolk (see it on Capterra)
{kind=link}
I'm a PhD candidate with absolutely no web scraping experience and needed to scrape some data for a dissertation project. ScrapingBee helped me get the job done quickly and easily. Excellent customer support too. Couldn't be happier!Sam ★★★★★ PhD candidate (see it on Capterra)
Great SaaS tool for legitimate scraping and data extraction. ScrapingBee makes it easy to automatically pull down data from the sites that publish periodic data in a human-readable format.👁 Image
Andy Hawkes Founder @Loadster
{kind=link}
Good experience. I found this proxy service more effective compared to previous ones that were being used. It is fast and efficient.Aayushi ★★★★★ Senior analyst (see it on Capterra)
Excellent service, glad we made the switch! We could always dedicate resources and build our own systems for everything... or we could simply call the scrapingBee API and focus on the data. It makes our work so much easier.Daniel L ★★★★★ Lead dev (see it on Capterra)
Simple, transparent pricing.
Cancel anytime, no questions asked!
API Credits
Concurrent requests
JavaScript rendering
Rotating & Premium Proxies
Geotargeting
Screenshots, Extraction Rules, Google Search API
Dedicated Scraping APIs
Priority Email Support
Dedicated Account Manager
Team Management
All prices are exclusive of VAT.
Need more monthly credits or higher concurrency?
Talk to Product ExpertNot sure which plan you need?
Try ScrapingBee with 1,000 free API credits.
Sign up
No credit card required.