
{kind=link}
Pricing
from $2.40 / 1,000 job-results
Workday Enterprise Jobs Scraper
Scrape public Workday career sites (*.myworkdayjobs.com) for enterprise job postings and turn them into clean, CSV-ready hiring-intelligence data - no login, cookies, or residential proxy required.
Pricing
from $2.40 / 1,000 job-results
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share
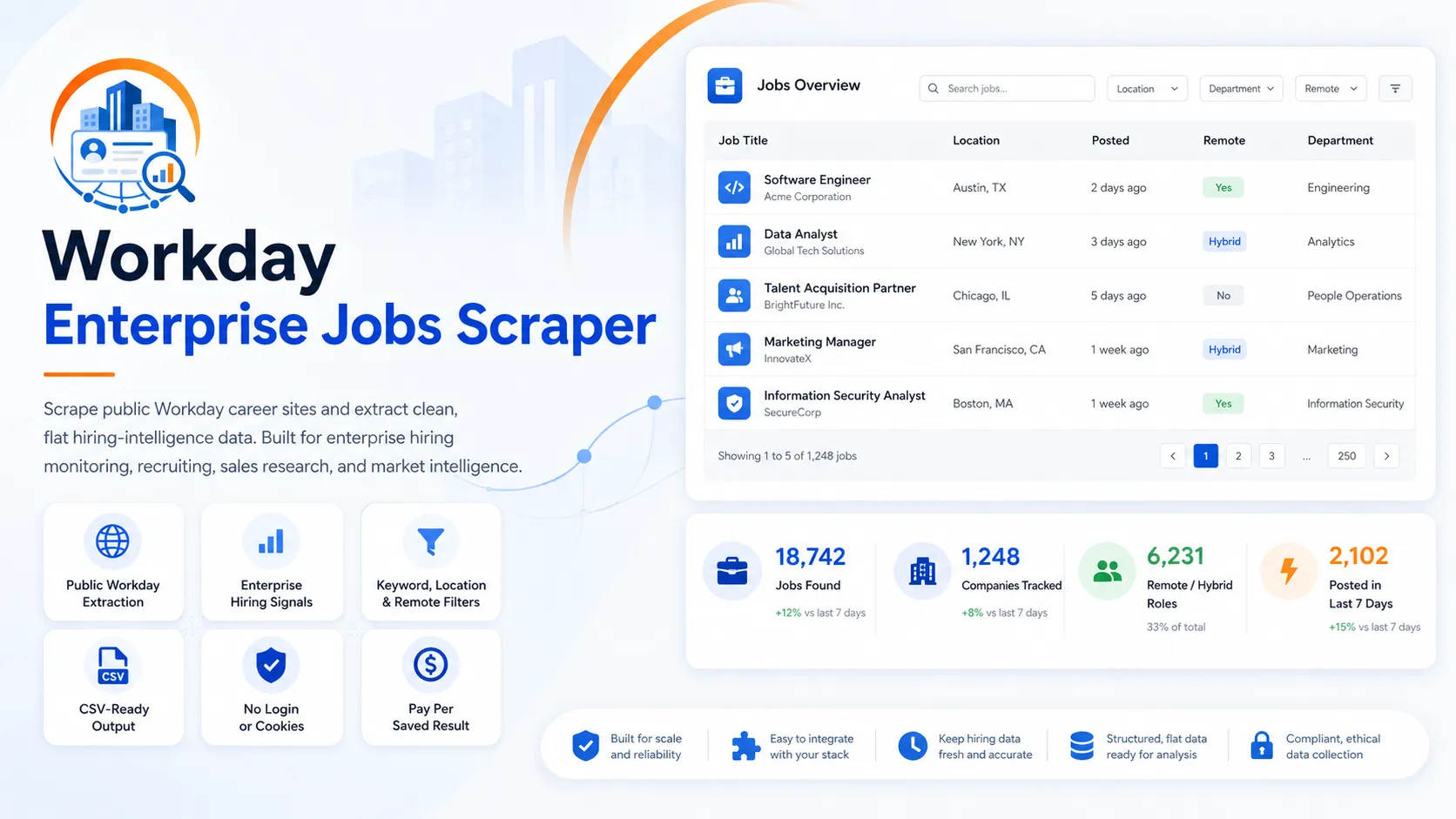
👁 Workday Enterprise Jobs Scraper
{kind=link}
Scrape public Workday career sites (*.myworkdayjobs.com) for enterprise job
postings and turn them into clean, flat, CSV-ready rows enriched with lightweight,
non-AI hiring-signal fields (remote/hybrid flags, location breakdown, seniority hint,
recency label, keyword hits, and signal tags).
It uses Workday's public, unauthenticated career-site JSON API ("CXS") over plain HTTP — no login, no cookies, no tenant credentials, no residential proxy. Output is a flat 28-field row per job, built for recruiters, sales teams, agencies, lead-gen, and market researchers.
✨ What it does
- Accepts one or more public Workday career/search/job URLs.
- Pages the public Workday listing endpoint and (optionally) fetches each job's public detail page for the full description, employment type, exact locations, posting date, and apply URL.
- Normalizes everything into a flat, stable, CSV-friendly schema.
- Deduplicates by Workday requisition ID and canonical job URL.
- Adds non-AI hiring-signal fields derived only from visible scraped data.
- Charges only for valid, unique, saved rows (pay-per-result).
🔗 Supported URLs
Any public Workday career site, for example:
Only *.myworkdayjobs.com URLs are supported. Other URLs are skipped and counted as
failed inputs (the run still succeeds).
📥 Input
| Field | Type | Default | Description |
|---|---|---|---|
startUrls | array of strings | NVIDIA example | Public Workday career/search/job URLs. Career/search URLs are paginated; /job/... URLs return that single posting. |
maxResults | integer | 500 | Max saved unique jobs across the whole run (1–5000). |
keywords | array of strings | [] | Keep only jobs whose title/department/job family/location/description contains one of these terms. |
locations | array of strings | [] | Keep only jobs whose location text contains one of these terms. |
remoteOnly | boolean | false | Keep only jobs that look remote or hybrid. |
postedWithinDays | integer / null | null | Keep only jobs posted within N days (1–365). |
strictDateFilter | boolean | false | When a recency filter is set, drop jobs whose date couldn't be parsed. |
includeJobDescription | boolean | true | Fetch each job's detail page for description + richer fields. Off = faster, fewer fields. |
includeDerivedSignals | boolean | true | Add signal_tags and keyword_hits. |
deduplicate | boolean | true | Remove duplicate jobs by requisition ID / canonical URL. |
proxyConfiguration | object | Apify Proxy | Datacenter, no-proxy, or custom proxy URLs. Apify Residential is rejected. |
Sample input — keyword + location filtering
Sample input — fast listing-only run (no descriptions)
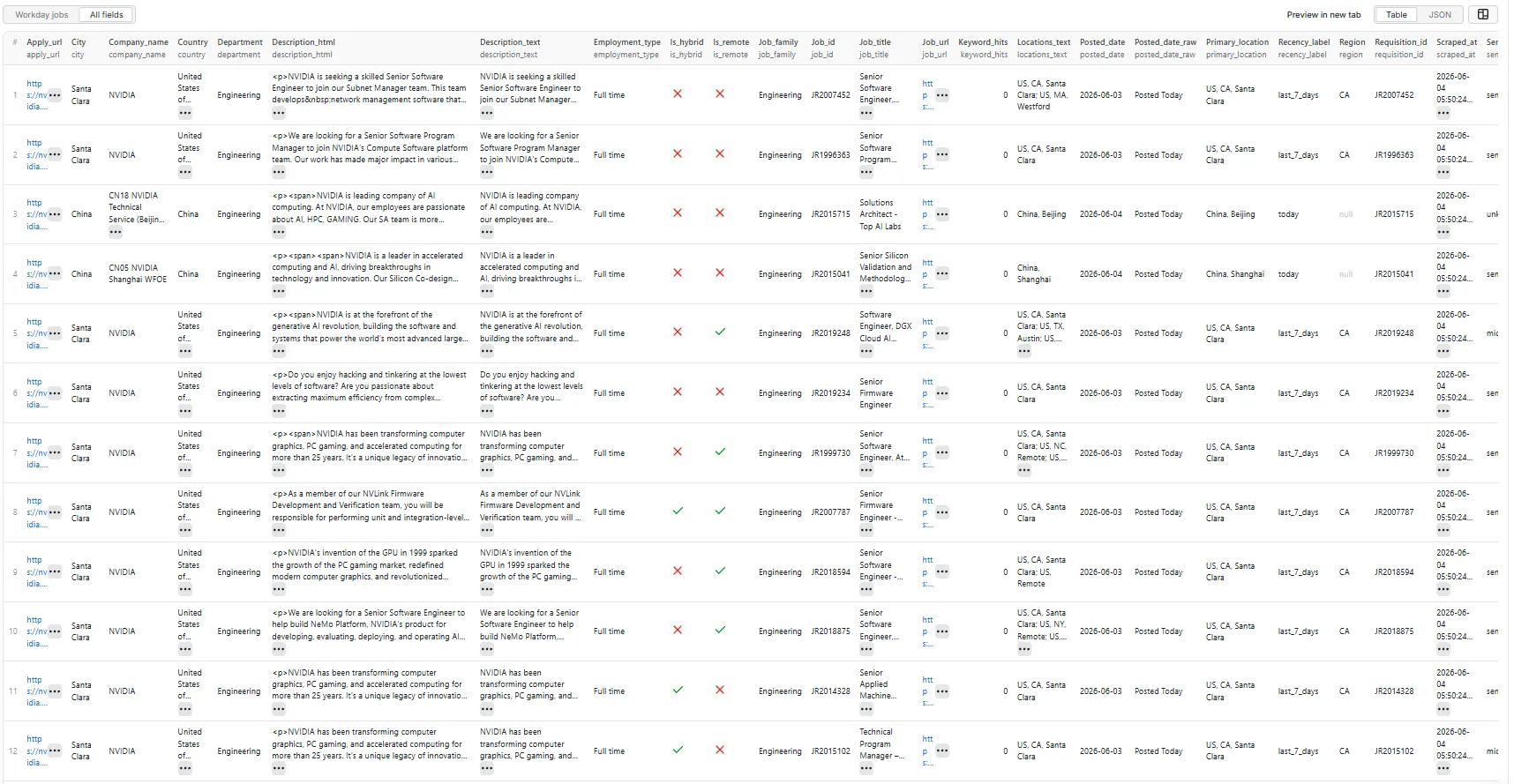
📤 Output
Each row is a flat object with these 28 fields:
job_id, requisition_id, job_title, company_name, workday_tenant, department,
job_family, employment_type, locations_text, primary_location, city, region,
country, is_remote, is_hybrid, posted_date, posted_date_raw, recency_label,
job_url, apply_url, description_text, description_html, seniority_hint,
keyword_hits, signal_tags, source_input_url, source_platform, scraped_at.
Output preview
👁 Workday Enterprise Jobs Scraper output — all fields
{kind=link}
Sample record
Sample from a real run.
keyword_hitsis0here because this run supplied nokeywords; setkeywordsto count and filter on your own terms.
regionanddescription_htmldepend on what a given Workday tenant exposes publicly and may benull.departmentandjob_familyare rarely published by Workday tenants; withincludeDerivedSignalson (default) they're filled from a title-inferred role category (e.g.Engineering,Data & Analytics) — an inferred label, not Workday's own classification. TurnincludeDerivedSignalsoff to keep them strictly source-only.
Run summary
A 14-field RUN_SUMMARY object is written to the default key-value store:
inputs_total, successful_inputs, failed_inputs, raw_results_found,
results_saved, duplicates_removed, filtered_out, charged_events,
blocked_requests, retry_count, detail_pages_requested, detail_pages_failed,
runtime_seconds, scraped_at.
💲 Pricing — Pay Per Result
This actor uses pay-per-event pricing with a single event:
| Event | Fires |
|---|---|
job-result | Once per unique job row that passed all filters and was successfully saved to the dataset. |
Duplicates, filtered-out rows, and failed requests are never charged. The per-event price is set on the Apify Store listing.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for public Workday career sites at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor fails at startup if
apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential
bandwidth (billed per GB) is charged to the developer, not the run user, so a single
bandwidth-heavy run could exceed the per-result revenue.
If you genuinely need residential routing, supply your own provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
⚙️ How it works
- Collection — for each search/career URL the actor POSTs the public Workday CXS
/jobsendpoint and pages by offset, building one row per posting. WhenincludeJobDescriptionis on, each kept job's public detail endpoint is fetched and the row is enriched in place. A directly-pasted/job/...URL is fetched as a single posting. - Finalize — keyword filters are applied, signal tags + keyword hits are computed,
the valid-row rule is enforced (
job_titleplus ajob_url/job_id/requisition_id), and each surviving row is pushed and charged.
No browser is used; everything runs over HTTP/JSON, so runs are fast and cheap.
🚫 Limitations
- Public data only — no login, cookies, internal Workday APIs, or candidate data.
- Fields are limited to what each tenant exposes publicly; some tenants expose less.
- Workday caps search results at ~10,000 per query; slice by site/keyword for more.
- No AI scoring, enrichment, salary normalization, or cross-site crawling in V1.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}