
{kind=link}
Pricing
$20.00 / 1,000 results
HuggingFace Papers Scraper
Scrape trending HuggingFace Papers by day, week, or month. Get titles, dates, submitters, organizations, upvotes, abstracts, summaries, PDFs, project links, and agent-ready commands for AI agents, RAG pipelines, research monitoring, and automation.
Pricing
$20.00 / 1,000 results
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Share
🤗 HuggingFace Papers Scraper
Track the latest AI research from HuggingFace Papers and turn trending papers into clean, structured data for agents, RAG systems, dashboards, and research workflows.
Choose a period (Daily, Weekly, or Monthly) plus an end date, and scrape up to 100 papers with titles, dates, submitter details, organizations, upvotes, abstracts, summaries, PDF links, project pages, and the HuggingFace CLI command agents can use to read the paper. The actor starts from the end date and paginates to older papers.
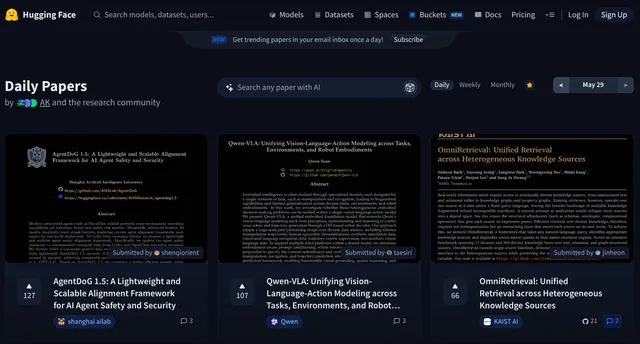{kind=link}
💡 Perfect For
- 🤖 AI Agents: Give agents fresh, structured research context with direct
pdf_url,project_url, andagent_commandfields. - 📚 RAG Pipelines: Index abstracts, summaries, metadata, and source URLs so assistants can answer questions about recent AI papers with citations.
- 🔬 Research Monitoring: Track emerging models, benchmarks, datasets, and methods across daily, weekly, or monthly HuggingFace trends.
- 📈 Trend Analysis: Compare upvotes, organizations, publication dates, and topics to spot fast-moving areas in AI.
- ⚙️ Automation Workflows: Feed new paper metadata into Slack bots, Discord alerts, newsletters, spreadsheets, or internal agent workflows.
✨ Why This Actor Matters
AI agents are only as useful as the context they can reliably access. HuggingFace Papers is one of the best places to discover what the AI community is reading right now, but agents and pipelines need structured fields, stable links, and normalized dates instead of raw HTML.
This actor turns that fast-moving research feed into data that is easy to search, rank, summarize, embed, and route into automated systems.
📦 What's Inside The Data?
For every paper, the actor returns:
- Core metadata:
url,title,published_date,submitted_date - Submitter details:
submitted_by,submitted_by_url - Organization details:
organization,organization_url - Engagement:
upvotes - Research content:
abstract,summary - Useful links:
pdf_url,project_url - Agent-ready command:
agent_command, for examplehf papers read 2605.29486
🚀 Quick Start
- Open the actor on Apify or run it locally.
- Choose the
period:Daily,Weekly, orMonthly. - Choose
end_date. If omitted or set in the future, the actor uses the current date. - Set
max_papersto the number of papers you want, up to 100. - Start the actor and export the results as JSON, CSV, Excel, or through the Apify API.
🧑💻 Tech Details
Input Example:
The actor builds the HuggingFace Papers URL from period and end_date, then paginates to older papers:
Daily+2026-06-01->https://huggingface.co/papers/date/2026-06-01Weekly+2026-06-01->https://huggingface.co/papers/week/2026-W23Monthly+2026-06-01->https://huggingface.co/papers/month/2026-06
Output Example:
Parameters:
| Parameter | Type | Required | Description |
|---|---|---|---|
period | string | No | HuggingFace Papers period to scrape: Daily, Weekly, or Monthly. Default: Daily. |
end_date | string | No | Latest date to scrape from. Format: YYYY-MM-DD. The actor paginates to older papers from this date. If omitted or in the future, the actor uses the current date. |
max_papers | integer | No | Number of papers to collect from the listing. Min 10, max 100, default 100. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}