
{kind=link}
📸 Instagram Profile Scraper — Email, Phone & Bio Leads
DeprecatedPricing
from $2.25 / 1,000 profiles
📸 Instagram Profile Scraper — Email, Phone & Bio Leads
DeprecatedScrape any Instagram profile by username or URL: email, phone, business location, bio, links, socials, engagement, followers, posts, verification & recent posts. No login, no API key. Bulk lead gen at $2.25/1,000 profiles, cheaper than the official scraper.
Pricing
from $2.25 / 1,000 profiles
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
2
Total users
1
Monthly active users
5 hours ago
Last modified
Categories
Share
📸 Instagram Profile Scraper — Email, Phone, Bio & Followers (No Login)
📊 Example output (real run)
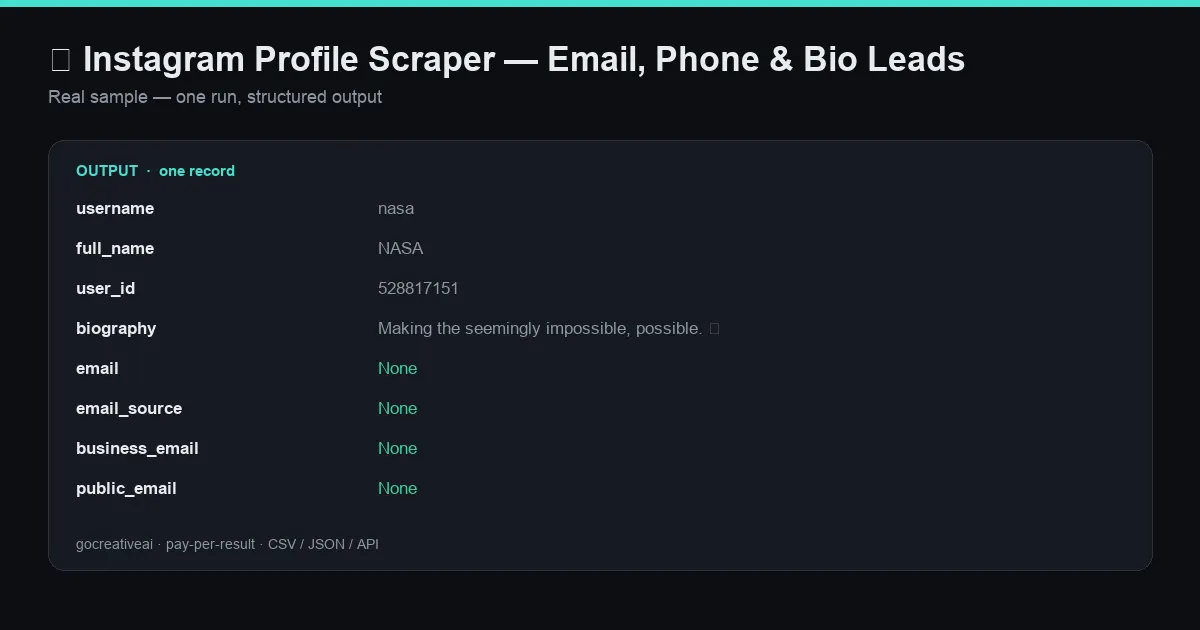{kind=link}
A real record from a live run — clean structured data, exported as CSV / JSON / Excel or via API.
Give it Instagram usernames or profile URLs and get back clean, structured profile data — including the email and phone from the bio, business location, follower stats and recent posts. No login, no cookies, no API key. Bulk lead generation at a flat $2.25 per 1,000 profiles — cheaper than the official Instagram scraper, and you only pay for profiles that scrape successfully.
instagram scraper · instagram profile scraper · instagram email scraper · instagram email extractor · scrape instagram followers · instagram bio scraper · instagram phone number scraper · influencer email finder · instagram lead generation · bulk instagram scraper · instagram contact scraper · instagram data scraper
👁 Instagram Profile Scraper — paste usernames in, get emails, phones, location & engagement out
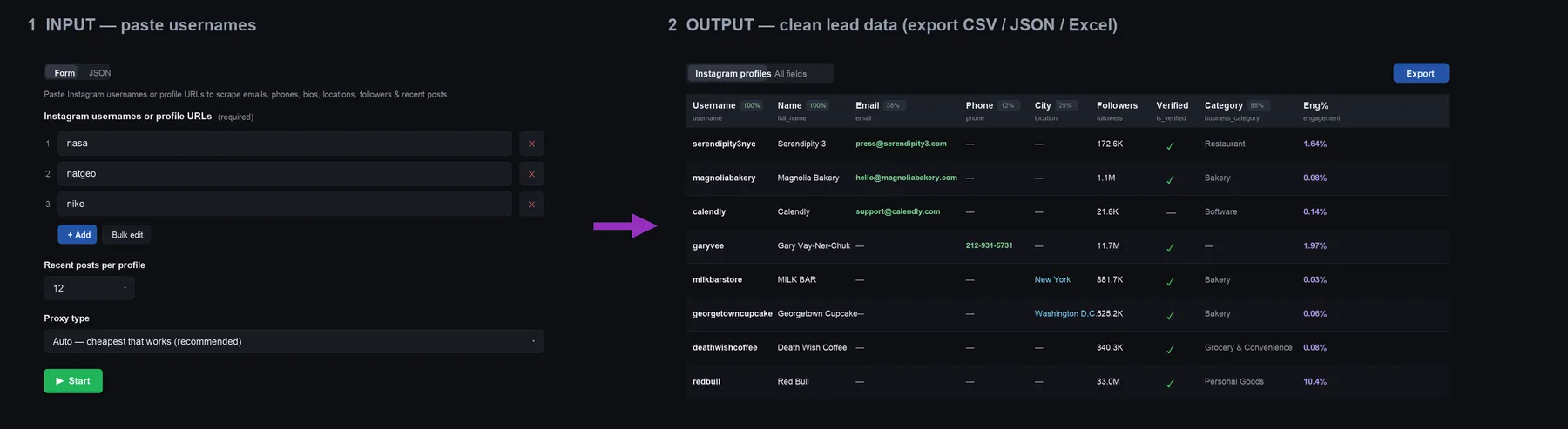{kind=link}
This actor calls Instagram's public web_profile_info endpoint over rotating proxies with a fresh IP per request (cheap datacenter first, residential fallback), so it stays reliable at scale (no session to break, no cookie-auth failures) and hits a high, real success rate. It's tuned for the lead-gen / email-finder buyer: it doesn't just dump follower counts — it returns the actual contact data most scrapers miss.
👀 See it in action
Step 1 — paste usernames in:
👁 Input: paste Instagram usernames or profile URLs
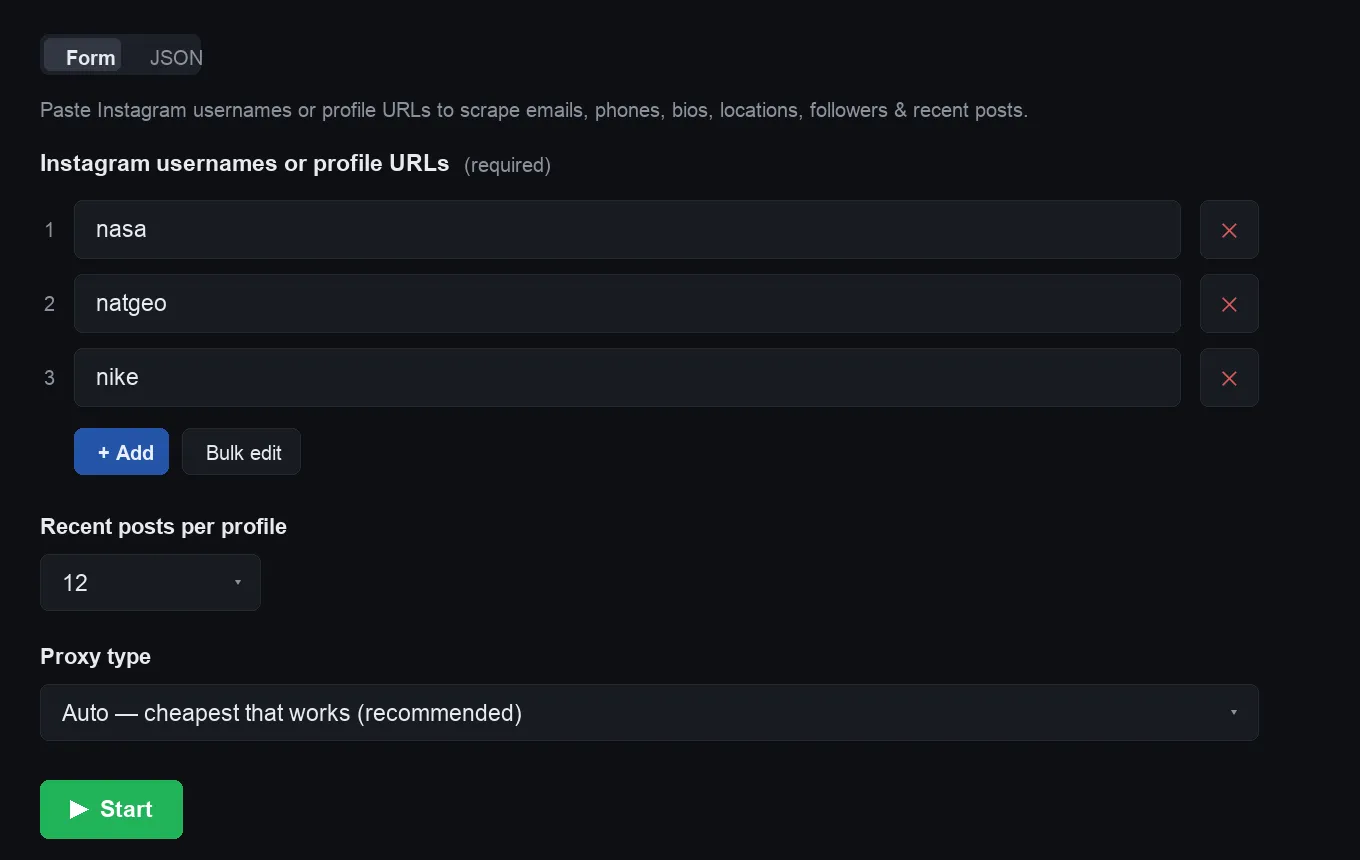{kind=link}
Step 2 — get clean lead data out (export to CSV, JSON or Excel):
👁 Output: username, followers, email, phone, engagement, verified
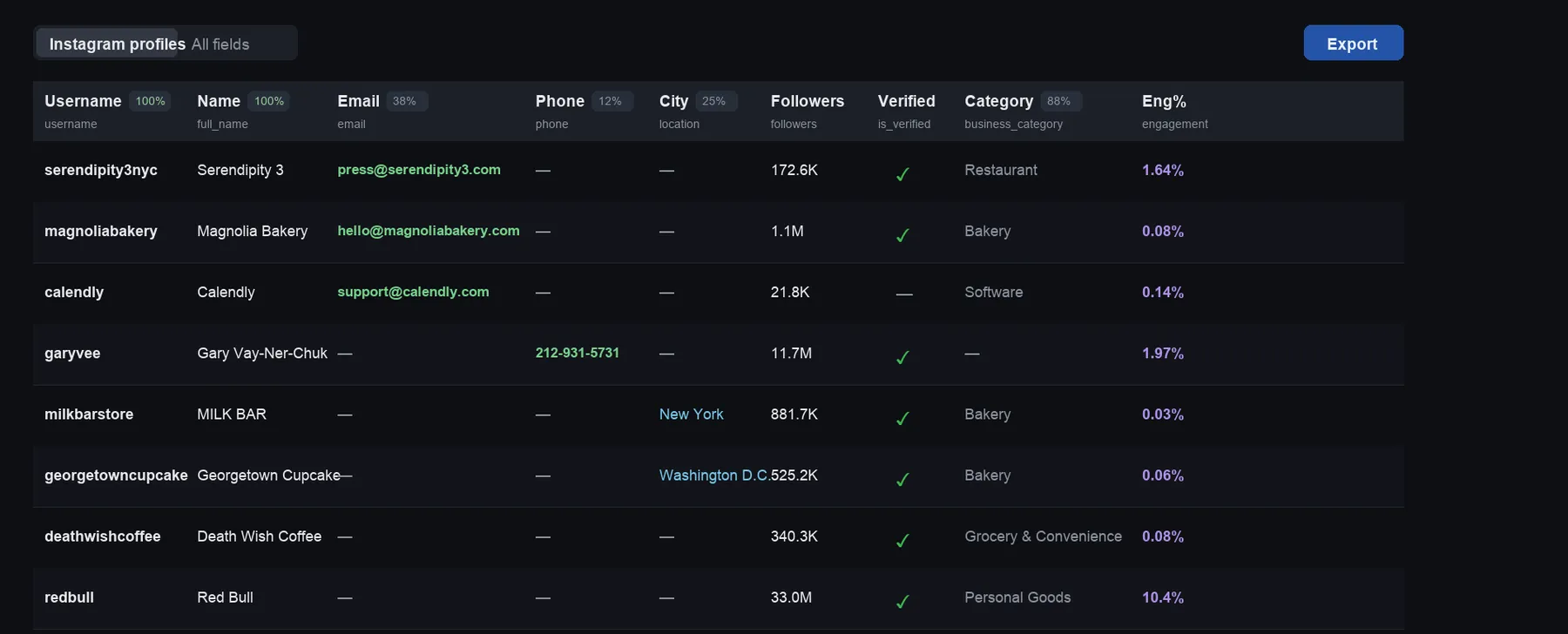{kind=link}
📦 What it extracts
| Field | Description |
|---|---|
username, full_name, user_id | Core identity |
email + email_source | Best email found, with where it came from (business_email · public_email · bio). Parses the business field and the bio text, including obfuscated forms (name [at] domain [dot] com) and mailto: links |
business_email, public_email | Raw Instagram contact-email fields, kept separately |
phone + phone_normalized + phone_source | Business/public phone, plus an E.164-style normalized number and its source (business_phone · public_phone · contact_phone · bio) |
location | Business address parsed into city, region, country, zip, street, latitude, longitude, instagram_location_id and a composite address |
external_url + bio_links + links | The link-in-bio: the single external URL and the full multi-link bio_links array, all un-wrapped from Instagram's l.instagram.com redirector, plus a deduped flat links list |
socials | The link-in-bio classified into platforms — Twitter/X, YouTube, TikTok, Facebook, LinkedIn, Linktree, WhatsApp, Telegram, Snapchat, Pinterest, Threads, Twitch, Spotify and more |
engagement | Computed from the recent posts: avg likes, avg comments, and engagement rate (%) — no extra cost, great for influencer vetting |
followers, following, posts_count | Audience & activity counts |
is_verified, is_business, is_professional_account, is_private, is_joined_recently | Trust & account-type flags for lead scoring |
business_category, category_name, account_type | Niche / segmentation |
fbid, connected_fb_page | Meta cross-platform IDs for enrichment & dedupe |
pronouns, highlight_reel_count, has_clips | Personalization & activity signals |
profile_pic_url | High-res profile picture |
recent_posts[] | Up to 12 latest posts: shortcode, url, caption, likes, comments, is_video, view_count, display_url, posted_at |
Export everything to CSV, Excel, JSON or via the API straight from the run.
🥇 Why this one
- Most complete on the Store. Email + phone + business location + classified social profiles + computed engagement stats + posts — in one call. We fold in what the email/phone scrapers, the "socials" scrapers, and the "engagement rate" scrapers each do separately.
- Real contact data, not just stats. Email + phone + business location + bio links — the lead-gen payload that pure "follower count" scrapers (even the popular ones) leave out entirely.
- Smart email extraction. A waterfall pulls emails from the Instagram business field, the newer public-email field, and the bio text — including obfuscated
name [at] domain [dot] compatterns andmailto:links — so you get a higher contact-fill rate. - Cheaper than the official scraper. A flat $2.25 per 1,000 profiles — just under Instagram's most popular scraper — and you're charged only for profiles that scrape successfully, never for blocked or not-found handles.
- Reliable & no login. Rotating proxies (cheap datacenter first, residential fallback) with a fresh IP per request — no cookies and no session token to break. Private and no-post accounts still return full profile + contact data (just empty
recent_posts). - Bulk & fast. Pure HTTP (no browser), fanned out concurrently — scrape thousands of handles in one run.
🚀 How to use it
- Open the actor and paste the Instagram usernames or profile URLs you want.
- (Optional) set how many recent posts to return per profile (
0–12). - Run it. Pull results as CSV / Excel / JSON or via the API.
Input:
You can mix bare handles (nasa), @handles, and full profile URLs — they're all normalized automatically and de-duplicated.
📤 What each row looks like
See the Output screenshot above for the at-a-glance view. Each profile comes back as a clean row with the key lead fields — here's a trimmed example (full output adds bio links, location lat/long, recent posts & more):
👥 Who it's for
- Agencies & founders building cold-email / DM outreach lists from Instagram business and creator accounts.
- Influencer marketers finding creator contact emails and vetting audience size + engagement before reaching out.
- Sales & lead-gen teams enriching a list of handles with email, phone and business location.
- Researchers & analysts pulling bios, links, categories and recent-post metrics for competitor or niche analysis.
❓ FAQ
Do I need an Instagram login, cookies, or an API key? No. The actor uses Instagram's public profile endpoint over rotating proxies (datacenter first, residential fallback) — nothing to log in to and no session to break.
Where does the email and phone come from?
Only from public data on the profile: the business/professional contact email & phone that the account owner chose to display, and any email/phone written in the public bio (we also catch obfuscated name [at] domain [dot] com forms and mailto: links). We cannot retrieve private emails that aren't public — no scraper can. So contact fields are populated for accounts that publish them (typically business/creator profiles) and are null otherwise.
Will it work on private accounts?
Yes — a private account still returns its full profile and any public business contact data; only recent_posts comes back empty. Use the is_private flag to filter.
How much does it cost? A flat $2.25 per 1,000 profiles ($0.00225 each), billed per result (pay-per-event). You're charged only for profiles that scrape successfully — never for blocked or not-found handles.
How fast is it / how many can I scrape? It's pure HTTP (no browser) and runs requests concurrently, so it handles thousands of handles per run. Each request uses a fresh IP to keep the success rate high.
Can I control the proxy / cost? Yes. The Proxy type input defaults to Auto — it tries Apify's cheap datacenter proxy first and falls back to residential, so you get a high success rate at the lowest cost. Force Residential for maximum reliability, or Datacenter for the absolute cheapest run.
What about export? Every run's results are available as CSV, Excel, JSON, or via the Apify API.
Is scraping Instagram legal? This actor only collects publicly available information that anyone can see without logging in, and it does not bypass any login or access controls. You are responsible for how you use the data — comply with Instagram's Terms, applicable laws (including data-protection laws like GDPR/CCPA when handling personal data such as emails), and anti-spam rules (e.g. CAN-SPAM, GDPR consent) for any outreach. Do not use scraped data for harassment or unlawful purposes. When in doubt, seek legal advice.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}