
{kind=link}
Pricing
from $8.90 / 1,000 results
Doxpop.com Scraper
Scrape Indiana & Michigan court case records from Doxpop.com. Extract case numbers, party names, filing dates, case type, status & disposition data. Perfect for US legal research, compliance monitoring & law firm analytics. Export to JSON, CSV or Excel via API.
Pricing
from $8.90 / 1,000 results
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
2
Total users
0
Monthly active users
3 months ago
Last modified
Categories
Share
{kind=link}
What does Doxpop Scraper do?
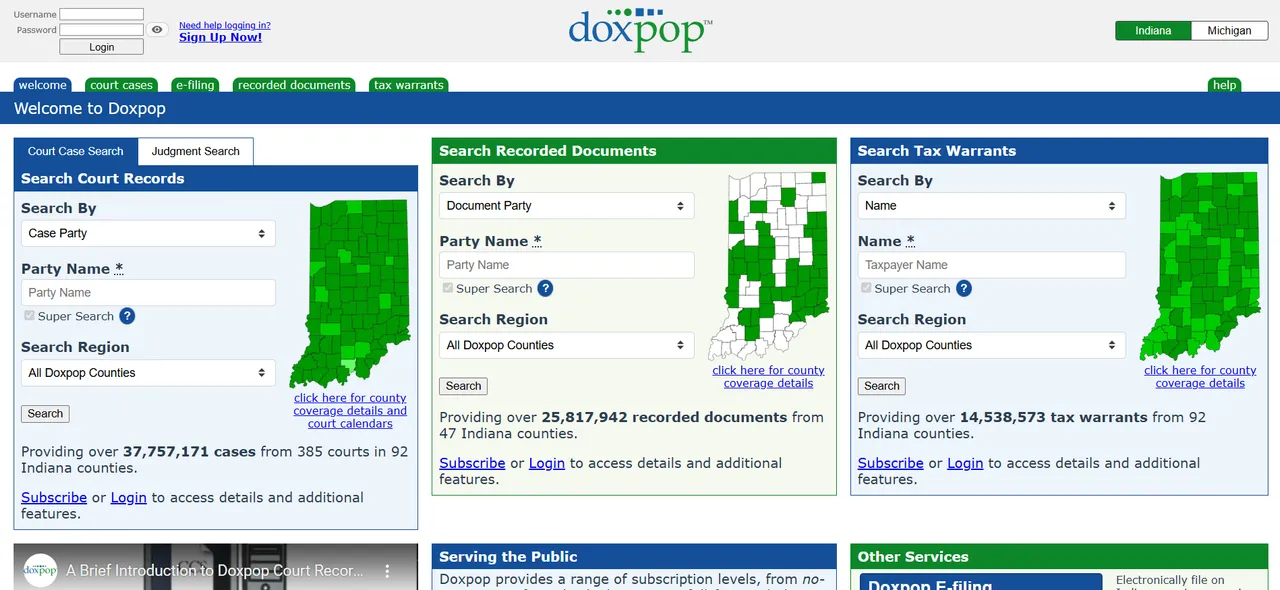
Doxpop Scraper helps you extract public court case search results from doxpop.com, a records platform that provides searchable access to court case records, recorded property documents, tax warrants, and judgments across Indiana and Michigan counties.
This actor is focused on Doxpop court case search pages. It accepts supported CaseSearch URLs, loads the public result data, and outputs normalized case records that you can download or consume through the Apify API.
Doxpop Scraper
Doxpop Scraper is designed for structured extraction of court case search results from Doxpop. The actor supports public result pages and returns a consistent dataset format, which makes it useful for monitoring filings, legal research workflows, analytics, and downstream integrations.
What does Doxpop Scraper do?
Doxpop Scraper helps you work with Doxpop court case search results without manually copying records from the website. It is intended for public result extraction only, and it normalizes the returned data into a stable output shape.
Basic result data appears publicly on Doxpop, while full record details, images, or document access may require a login or paid subscription depending on the county and record type.
Doxpop Scraper
Doxpop Scraper allows you to collect public court case result data from Doxpop search pages that include party name, case type, and regional filters. The actor is suitable for repeated monitoring runs because the output is standardized and limited to selected fields only.
What data can I extract from Doxpop with this web scraper?
With this web scraping tool, you can extract the following data from Doxpop:
| Case ID | Case number |
| Caption | Case type |
| Status | File date |
| Disposition date | Name |
| Actor ID | Birth date |
| Role | Case details URL |
Why scrape Doxpop?
Doxpop offers public search interfaces for court cases, judgments, recorded documents, and tax warrants across multiple Indiana and Michigan jurisdictions. For court case searches, it exposes useful summary-level records such as case number, filing dates, party names, case type, and status.
- Monitor case search results for specific names or patterns
- Build internal datasets for legal or compliance research
- Track filing and disposition activity over time
- Export public court search results into structured formats
- Reuse result data in reporting, dashboards, or pipelines
- Reduce manual lookup work across repeated searches
How to use Doxpop Scraper?
Doxpop Scraper is designed for a fast start, even if you have never worked with Apify actors before. Here is how to extract court case search data from Doxpop:
- Create a free Apify account using your email.
- Open Doxpop Scraper on the Apify platform.
- Click on the Try for free button.
- Enter one or more supported Doxpop court
CaseSearchURLs. - Set
maxItemsto control how many case records should be extracted per start URL. - Click on the Start button and wait for the data to be extracted.
- Download your data in JSON, CSV, Excel, HTML, or other supported formats.
Input
The actor accepts the following input parameters:
- startUrls (array of objects) - Required. Doxpop court
CaseSearchURLs to start with. - maxItems (integer) - Maximum number of case records to extract per start URL. Default: 5.
- proxyConfiguration (object) - Optional proxy settings. By default, the actor is configured to run without Apify Proxy.
Supported URL Types (examples)
This actor currently supports Doxpop court case search result URLs:
Search URL example:
Additional search URL example:
Unsupported pages:
- Other Doxpop search forms such as judgments, recorded documents, and tax warrants are not handled by this actor unless explicitly added later.
Example:
Note: The startUrls field is required
Output
The scraped data is saved as a dataset. Each item represents one normalized Doxpop court case search result. You can download the dataset in JSON, JSONL, CSV, Excel, HTML table, or NDJSON format.
Example output structure:
Notes and Limitations
- This actor currently supports only Doxpop court
CaseSearchURLs. - The actor outputs only a fixed set of approved fields to keep the dataset stable even if Doxpop adds extra attributes.
- Public search results are available without full account access, but deeper details or associated documents may require login or subscription.
- Search coverage and visible result details may vary by jurisdiction, county, and record type.
- If Doxpop changes its search flow or response format, the actor may need to be updated.
Looking to Scrape more Government Websites?
In addition to this actor, you can explore our broader set of website scrapers published by Lexis Solutions. These actors are tailored for specific websites and use cases so the output stays structured and reliable.
| Scraper | Country | Description |
|---|---|---|
| Praca.gov.pl Scraper | Poland | Extract up-to-date job postings from praca.gov.pl—the Polish government job portal. Gather detailed info on jobs, employers, salaries, and requirements. Ideal for market analysis, recruitment, and labor studies in Poland. Fast, flexible, and easy to use. |
| UK Business Licence Scraper | United Kingdom | Scrape UK business licence data from GOV.UK for compliance and regulatory insights. Automate permit research, extract requirements, and monitor updates—ideal for consultants, legal teams, and business planning. Fast, structured and comprehensive results. |
Explore these solutions to expand your data collection capabilities across different websites and industries.
Got feedback or need an extension?
Lexis Solutions is a certified Apify Partner. We can help you with custom solutions or data extraction projects.
Contact us over Email or LinkedIn
Image Credit: https://www.doxpop.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}