
{kind=link}
Pricing
from $2.90 / 1,000 results
Hi Jobs (HIJOBS) Scraper (/w EMAILS)
Scrape hijobs.net — Scotland's Highlands & Islands jobs board — via the official HIJOBS mobile API. Title, employer, salary, location, hours, sector, closing date, apply email + full description. Search by URL or filters, recency filter, 37 fields per row. JSON or CSV out.
Pricing
from $2.90 / 1,000 results
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
3
Total users
1
Monthly active users
13 days ago
Last modified
Categories
Share
Hi Jobs (HIJOBS) Scraper
Scrape hijobs.net — Scotland's Highlands & Islands jobs board — through the official HIJOBS mobile JSON API. The website itself sits behind Cloudflare's interactive challenge, but the HIJOBS iOS app talks to a clean, public JSON API (api.hijobs.co.uk) that is not Cloudflare-gated and needs no login. This actor uses that API directly — so you get structured JSON (not scraped HTML), fast, with richer fields than the website exposes. Newest-first by default, with an optional "posted within N hours" recency filter that early-stops pagination. JSON or CSV out.
How it works
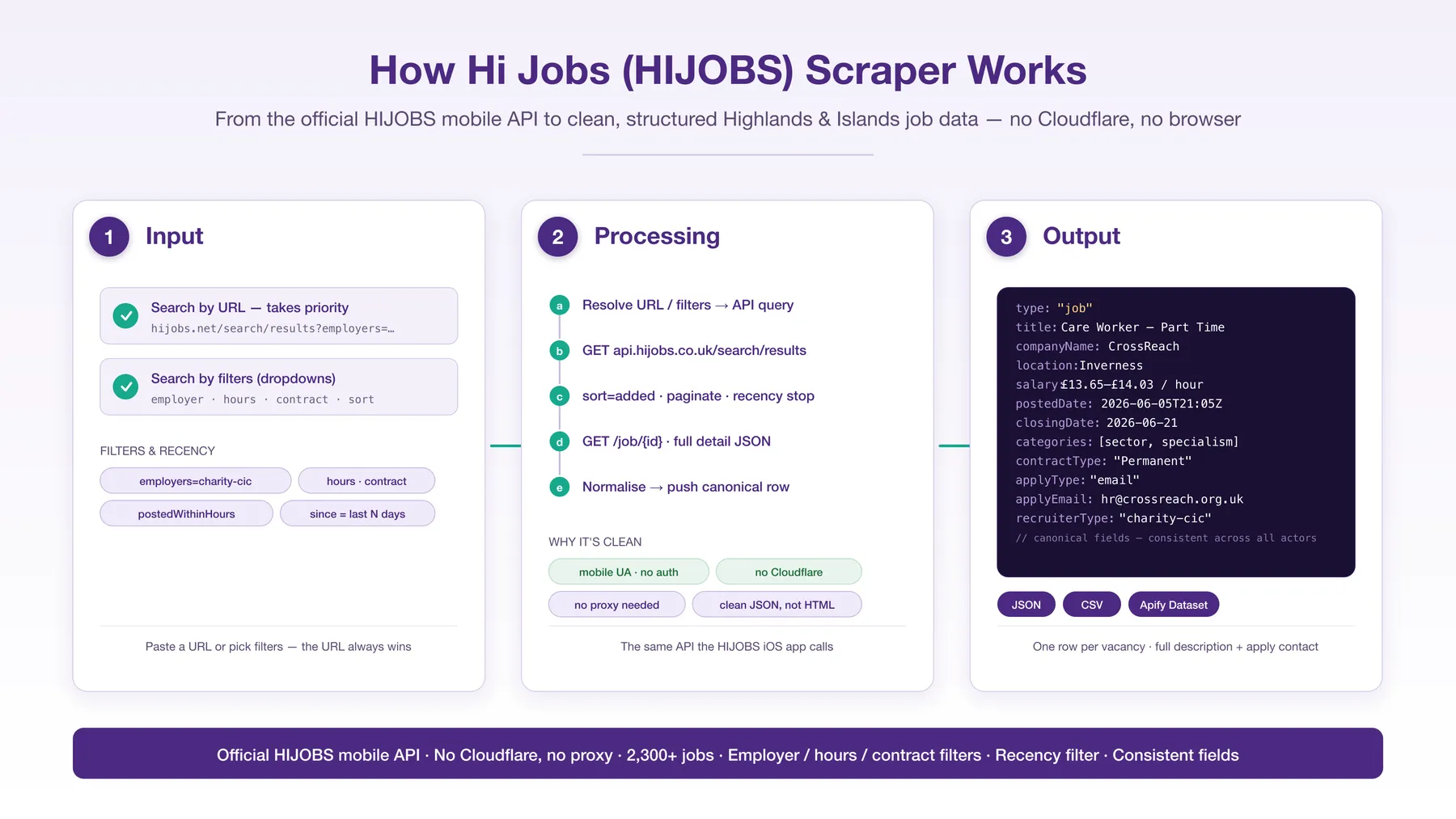{kind=link}
✨ Why use this scraper?
HIJOBS is the jobs board for the Scottish Highlands & Islands — Inverness, Oban, Skye, the Outer Hebrides, Argyll, Moray. ~2,300 live vacancies across care, hospitality, retail, public sector, trades, engineering, and community/third-sector roles.
- 🚀 Official mobile API, not HTML scraping. We reverse-engineered the HIJOBS iOS app and found its public JSON API (
api.hijobs.co.uk). It needs no auth and isn't behind Cloudflare — so every field comes back clean and structured, no brittle HTML parsing, no browser, no proxy required. - 🧱 Two endpoints, full coverage.
/search/resultsreturns paginated job lists (id, title, ISO posted time, closing date, salary, location, hours, contract, sector, recruiter, logo, badges)./job/<id>adds the full HTML description, the real apply contact (name + email) for direct employers, the external application URL, and the employer record. - ⏱️ Built-in recency filter.
postedWithinHours: 24returns only jobs added in the last day — and because results are sorted newest-first, it early-stops pagination the moment it passes the cutoff. Cheap, fast daily monitoring. - 💰 Proper salary ranges.
£42,600 to £64,000 per annum,£13.45 to £14.45 per hour→ structured{currency, min, max, unit, raw}. - 📧 Real apply contacts. Direct-employer jobs expose a genuine
applyEmail+contactName; agency/external jobs expose theexternalApplyUrl. - 🧭 Consistent field names. Emits the same canonical core columns (in the same order) as every other scraper in this collection — drop the rows straight into your existing mapping.
- 📤 Clean exports. One row per vacancy. JSON + CSV exported automatically.
🎯 Use cases
| Team | What they build |
|---|---|
| Highlands & Islands recruiters | Daily new-vacancy feeds across Inverness / Argyll / the Isles |
| Care & hospitality aggregators | Live regional vacancy boards for the sectors that dominate HIJOBS |
| Relocation / community sites | "Jobs in the Highlands" listings auto-populated each morning |
| Workforce & economic researchers | Rural Scotland labour-market datasets with salary + sector |
| Third-sector / public bodies | Track who's hiring across Highland charities and councils |
📥 Supported inputs
There are two ways to search, and Search-by-URL always wins when both are filled in:
1. Search by URL (startUrls) — paste any hijobs.net address. The easiest way: go to hijobs.net, click the filter chips you want (sector, location, employer type, salary, last-N-days…), then copy the address-bar URL straight in. Every chip is honoured.
| URL | Behaviour |
|---|---|
https://hijobs.net/search/results?employers=charity-cic&where=Scotland&sort=relevance&since=3 | Full filtered search — all chips honoured; since=3 → last-3-days recency |
https://hijobs.net/jobs | Newest-first listing |
https://hijobs.net/jobs/<location> | Location facet (e.g. /jobs/oban) |
https://hijobs.net/job/<id>/<slug> | Single job → GET /job/<id> |
https://api.hijobs.co.uk/search/results?... | Raw API search URL (params passed through) |
2. Search by filters — used only when startUrls is empty. Pick from dropdowns instead of building a URL:
| Field | Maps to | Values |
|---|---|---|
keywords | keyword search | free text (e.g. support worker) |
where | location | free text (e.g. Inverness, Scotland) |
employerType | recruiter type | Charity / CIC, Direct Employer, Agency, Recruitment Consultant, Local Government |
hours | working hours | Full Time, Part Time |
contractType | contract | Permanent, Contract, Interim, Graduate, Temporary, Casual, Student Placement, Volunteer |
sort | ordering | Newest first, Date, Highest salary, Relevance |
postedWithinHours | recency | e.g. 24 (last day), 72 (last 3 days) |
Leave everything empty for the newest-first feed.
Not supported: authenticated/recruiter features, the applicant flow, employer dashboards.
🔄 How it works
- Resolve input — turn
startUrls(website or API), orkeywords/where, into API queries (or direct job-IDs). - Paginate
GET /search/results?sort=added&size=25&pg=N(newest-first). - Parse each
Jobs[]item — id, title, ISOAdded(posted),Expires(closing), rate, location, hours, contract, sector, recruiter, logo, flags (Work-from-home / Immediate-start / Promoted), teaser. - Recency gate — with
postedWithinHoursset, skip older items and stop paginating once a whole page is past the cutoff. - Enrich (optional) —
GET /job/<id>for the full HTML description, apply contact (name + email), application URL, employer record. - Normalise + push — every row goes through the shared canonical normaliser so the column layout matches the rest of the collection.
⚙️ Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
startUrls | array | (empty) | Search by URL — takes priority. Any hijobs.net listing/search/facet/job URL. When set, the filter fields below are ignored. |
keywords | string | (none) | Keyword search (filter mode). |
where | string | (none) | Location / area (filter mode). |
employerType | string | Any | Recruiter type → employers (e.g. charity-cic). Filter mode. |
hours | string | Any | full-time / part-time. Filter mode. |
contractType | string | Any | permanent, contract, temporary, volunteer, … Filter mode. |
sort | string | added | added (newest), date, salary, relevance. |
enrichDetail | boolean | true | Fetch each /job/<id> for the full description + apply contact. Disable for list-only (faster, fewer calls). |
postedWithinHours | integer | (none) | Only return jobs added in the last N hours (24 = last day, 72 = last 3 days). Empty/0 = all. Early-stops pagination — ideal for daily monitoring. |
maxItems | integer | 1000 | Hard cap on rows pushed (~2,300 live jobs total). |
maxPages | integer | 120 | Safety cap on API pages walked (25 jobs/page). The recency filter usually stops far earlier. |
maxConcurrency | integer | 5 | Parallel /job/<id> detail fetches. |
proxy | object | (off) | Optional. The API is open, so a proxy isn't needed — left here for users who want one. |
📊 Output overview
Each scraped vacancy is one single dataset row of type: "job". List fields are always present; description (full HTML), applyEmail/contactName, and externalApplyUrl come from detail enrichment when enrichDetail is on.
📦 Output sample
🗂 Key output fields
| Group | Fields |
|---|---|
| Identifiers | type, source, sourceProvider (hijobs), jobId, slug, jobUrl, apiUrl, scrapedAt |
| Content | title, description (HTML, with enrichDetail), descriptionText, descriptionTeaser |
| Dates | postedDate (ISO, from Added), postedFriendly, closingDate (from Expires), modifiedDate |
| Employer | companyName, recruiterType (direct-employer / agency), recruiterSlug, companyLogo, contactName |
| Location | location, city, country, remote |
| Compensation | salary.{currency, min, max, unit, raw}, salaryRaw |
| Classification | categories[] (sector + specialism), employmentTypes[], contractType, hours |
| Apply flow | applyType (external / email / internal), applyUrl, applyEmail, externalApplyUrl |
| HIJOBS-specific | flags[] (Work-from-home / Immediate-start / Promoted / Popular), reference, requiresCv, numberVacancies |
❓ FAQ
How does this get past Cloudflare?
It doesn't have to. The HIJOBS website is Cloudflare-gated, but the HIJOBS iOS app talks to a separate, public JSON API on api.hijobs.co.uk that isn't behind Cloudflare and needs no login. We call that API directly — cleaner and faster than scraping the site. (A Cloudflare-bypass fallback exists for resilience but is rarely needed.)
Why is applyEmail sometimes null?
Direct-employer jobs publish a real contact email (you'll get applyEmail + contactName). Agency / "apply on the employer's site" jobs instead publish an externalApplyUrl, and applyType is external. Jobs with neither default to the on-site HIJOBS apply page in applyUrl.
Does postedWithinHours really save money?
Yes. Results are newest-first, so the actor stops paginating as soon as it hits a full page older than your cutoff. A postedWithinHours: 24 run typically touches 1–3 pages instead of all ~95.
Why is closingDate / full description sometimes null?
The full description + closing date come from the /job/<id> detail call. With enrichDetail: false those calls are skipped — the list still gives title, employer, posted time, salary, location, hours, sector, and the closing date (Expires).
Can I scrape a specific town or sector?
Set where (e.g. Inverness) and/or keywords, or paste a https://hijobs.net/jobs/<location> URL. The same row shape applies.
Can I scrape private pages or applicant data? No. Only the same public job listings + detail the HIJOBS app itself loads — no authenticated endpoints.
💬 Support
- For issues or feature requests, please use the Issues tab on the actor's Apify Console page.
- Author's website: https://muhamed-didovic.github.io/
- Email: muhamed.didovic@gmail.com
🛠 Additional services
- Custom output shape, additional fields, or one-off datasets: muhamed.didovic@gmail.com
- Mobile-API reverse-engineering for other Cloudflare-gated sites in your portfolio (same approach as here): drop an email.
- For API access (no Apify fee, just usage): muhamed.didovic@gmail.com
🔎 Explore more scrapers
See other scrapers at memo23's Apify profile — covering job boards, real estate, social media, and more.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by HIJOBS, HIJOBS Limited, hijobs.net, or any of their subsidiaries or affiliates. All trademarks mentioned are the property of their respective owners.
The scraper accesses only the public job-search and job-detail endpoints of the HIJOBS mobile API — the same data the HIJOBS app loads for any user — with no authenticated endpoints, recruiter-only features, applicant data, or content behind a login. Users are responsible for ensuring their use complies with HIJOBS's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organisation.
SEO Keywords
hijobs scraper, scrape hijobs.net, hijobs api, hijobs mobile api scraper, api.hijobs.co.uk, highlands and islands jobs scraper, scottish highlands jobs api, inverness jobs scraper, oban jobs scraper, skye jobs scraper, argyll jobs api, moray jobs scraper, outer hebrides jobs scraper, rural scotland jobs data, highland care jobs scraper, highland hospitality jobs api, scotland jobs board scraper, mobile app api scraper, reverse engineered job board api, highland third sector jobs api, asva alternative scraper, s1jobs alternative scraper, highlandjobs alternative scraper, scottish job board api
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![👁 Ashby Jobs [$0.9💰] API Scraper | Any Company (/w EMAILS) avatar](https://images.apifyusercontent.com/lyplOop0WzFs_Xh4Mb1yzcEeJc8YDkvFuy97Io9rRcU/rs:fill:76:76/cb:1/aHR0cHM6Ly9hcGlmeS1pbWFnZS11cGxvYWRzLXByb2QuczMudXMtZWFzdC0xLmFtYXpvbmF3cy5jb20vbmduOHZSRVNUa3NleVdFNnAtYWN0b3ItVHZoQXJlbGVjeER4clhMZ08tS3NDTnBlVm5pRi1Bc2hieS5qcGVn.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}