
{kind=link}
Pricing
from $0.90 / 1,000 results
SmartRecruiters Jobs Scraper & API
Scrape every open job from any company on SmartRecruiters. Give a company ID and get each role with full description, location, department, employment type and apply URL — via the public Posting API. Filter by title, location, remote. Handles huge boards. No proxy. JSON or CSV.
Pricing
from $0.90 / 1,000 results
Rating
0.0
(0)
Developer
{kind=link}
Actor stats
0
Bookmarked
4
Total users
3
Monthly active users
6 days ago
Last modified
Share
SmartRecruiters Jobs Scraper 🧭
Scrape every open job from any company hosted on SmartRecruiters (smartrecruiters.com) — title, full description, location, department, and apply URL — straight from SmartRecruiters's public Posting API. List + per-job detail gives the complete posting, including very large boards. No login, no anti-bot, no browser.
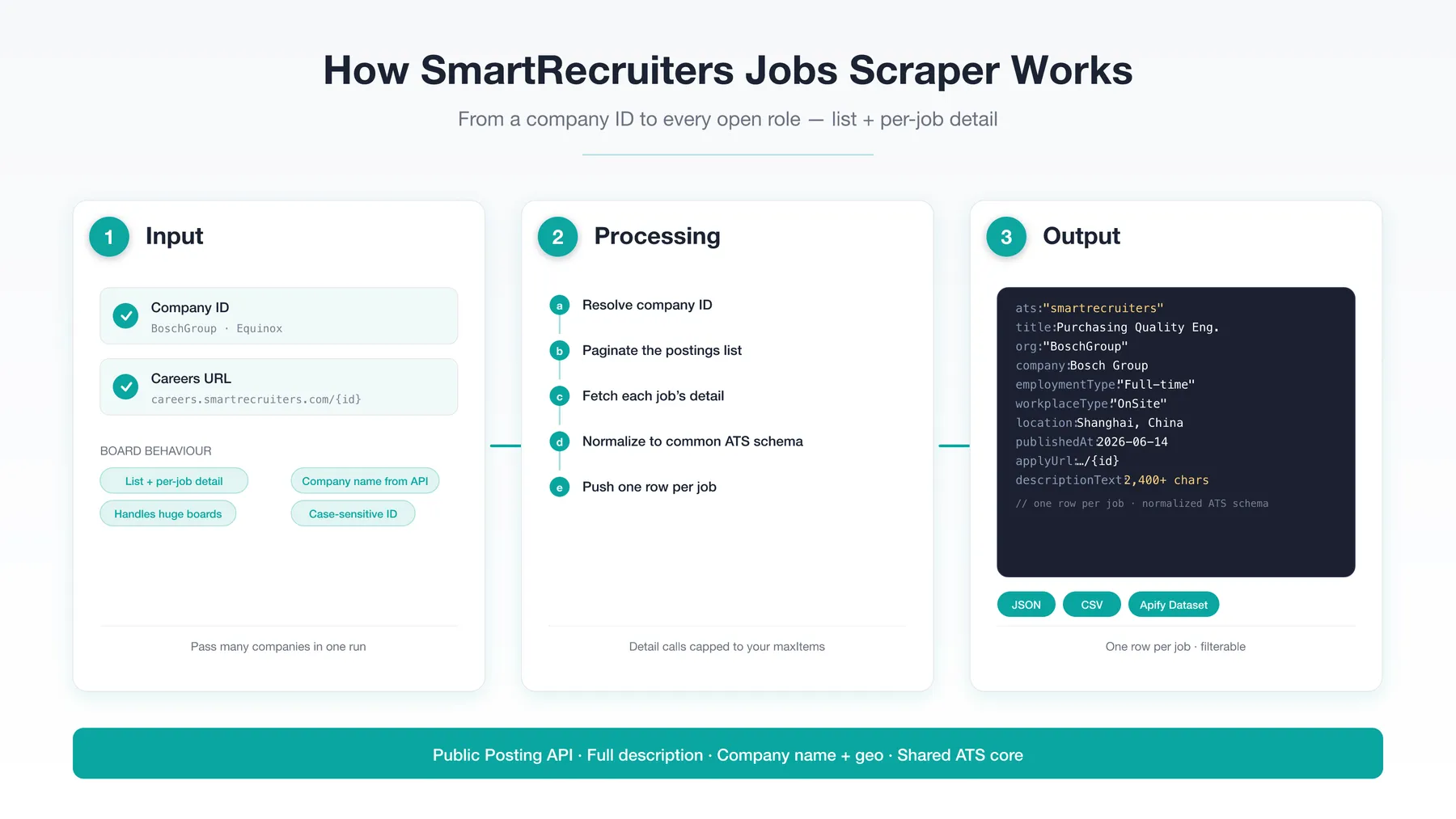
👁 How SmartRecruiters Jobs Scraper works
{kind=link}
Why use this scraper
- Handles huge boards. SmartRecruiters powers enterprise careers sites with thousands of roles — pagination and per-job detail are handled for you, capped to your maxItems.
- Full job detail, not just titles. Each row carries the entire job:
descriptionHtml+ plain text, location(s), employment type, workplace type, and the apply URL. - Fast and cheap. No proxies required (the API has no anti-bot), so runs are quick and your cost stays low.
- Normalized schema. Output uses a consistent ATS schema shared with our other ATS scrapers (Ashby, Lever, SmartRecruiters, Personio, BambooHR) — write one parser, reuse it across every ATS.
- Built-in filters. Narrow by title, location, department, employment type, remote, or posted date — applied before a row is emitted, so you only pay for matches.
Overview
SmartRecruiters is a widely-used recruiting platform. Large enterprises host their careers on SmartRecruiters at https://careers.smartrecruiters.com/{CompanyId}. This actor reads each company's jobs through SmartRecruiters's public Posting API and emits one clean, normalized row per open job.
Supported inputs
| Input type | Example | Notes |
|---|---|---|
| Company ID | BoschGroup, Equinox, Visa | CASE-SENSITIVE (BoschGroup, not bosch) |
| Careers URL | https://careers.smartrecruiters.com/BoschGroup | The company ID is extracted |
Provide them in Start URLs and/or Organization slugs. Mix as many companies as you like in one run.
Where's the Company ID? It's the segment after
smartrecruiters.com/in the careers URL, and it is case-sensitive.
Use cases
- Job boards & aggregators — ingest fresh, structured roles from many companies.
- Recruiting & sourcing tools — track who's hiring for what.
- Market & talent intelligence — hiring velocity, remote-vs-onsite mix.
- Lead generation — companies actively hiring are buying signals for many B2B products.
- Personal job search — pull every role across your target companies into one sheet.
How it works
- Resolve each input to a SmartRecruiters company ID.
- Paginate
api.smartrecruiters.com/v1/companies/{id}/postings(100/page). - Fetch each job's detail (
/postings/{id}) for the full description — capped tomaxItems, and skipped entirely whenincludeDescriptionis off. - Normalize to a common ATS schema and push one row per job.
Companies are processed in parallel with a sliding-window concurrency cap. No proxy is needed; you can supply one for IP rotation at very large scale.
Input configuration
| Field | Type | Default | Description |
|---|---|---|---|
startUrls | array | – | SmartRecruiters company IDs or careers URLs (strings or {url} objects). |
organizations | array | – | Bare SmartRecruiters company IDs (case-sensitive), e.g. ["BoschGroup","Equinox"]. |
maxItems | integer | 5000 | Max job rows emitted across the whole run. |
maxConcurrency | integer | 10 | How many companies to fetch in parallel. |
titleKeyword | string | – | Keep only jobs whose title contains this. |
location | string | – | Keep only jobs whose location contains this. |
department | string | – | Keep only jobs whose department contains this. |
employmentType | string | – | Keep only this employment type. |
remoteOnly | boolean | false | Keep only remote jobs. |
postedAfter | string | – | Keep only jobs published on/after this date (YYYY-MM-DD). |
language | string | – | Keep only jobs in this language. Prefix match on the language code — en keeps en, en-GB, en-US. (No translation — non-matching roles are excluded, not converted.) |
includeDescription | boolean | true | Include descriptionHtml + descriptionText. Off skips the per-job detail call entirely — much faster/cheaper for huge boards. |
excludeBoilerplate | boolean | false | Drop the Company Description + Additional Information sections from the combined descriptionHtml/descriptionText. The four sections are emitted as separate columns either way, so you can also clean them in Excel. |
includeRawJson | boolean | false | Attach the original SmartRecruiters payload under raw. |
proxy | object | – | Optional. Not required (no anti-bot); use only for IP rotation at scale. |
Example input
Output
One row per open job. Example (trimmed):
Key output fields
| Field | Description |
|---|---|
ats | Always "smartrecruiters" — the source platform. |
org | Company board identifier. |
company | Company display name. |
companyJobsTotal | Total open postings the company has on SmartRecruiters (board total, before maxItems/filters) — same value on every row of that company. |
inputOrder | 0-based position of this company in your input list. Sort by this to get the output in the same order as your input. |
globalId | Stable, unique key ats:org:jobId — use it to dedupe across runs. |
title | Job title. |
language / languageLabel | Language the posting was written in (code + label, e.g. en / English). Filter with the language input. SmartRecruiters does not translate — non-English roles stay in their original language. |
department / team | Org grouping as set by the company. |
employmentType | Full-time / Part-time / Intern / Contract / Temporary (as the ATS reports it). |
workplaceType / isRemote | Remote / Hybrid / OnSite + a boolean remote flag. |
location / locations | Primary location + every listed location. |
descriptionHtml / descriptionText | Full job description as HTML and plain text (honours excludeBoilerplate). |
companyDescription / jobDescription / qualifications / additionalInformation | The description split into its individual sections (plain text). Delete the columns you don't want at the Excel/cleaning stage. |
publishedAt | When the role was published (ISO). |
jobUrl / applyUrl | Public posting URL + application URL. |
Coverage report (which input links produced jobs)
Every run also writes a per-input coverage report to the run's key-value store, as both INPUT-COVERAGE (JSON) and INPUT-COVERAGE.csv (opens directly in Excel). It has one row per input link — in the order you supplied them — so you can verify exactly which links worked:
| Column | Description |
|---|---|
inputOrder | Position in your input list. |
input | The link / company ID exactly as you gave it. |
company | Resolved SmartRecruiters company ID. |
status | ok (jobs scraped) · no_jobs (valid company, no open roles) · filtered_out (had roles, all removed by your filters) · failed (fetch error) · unsupported (not a SmartRecruiters link) · duplicate · skipped_max_items. |
jobsFound / jobsScraped | Board total reported vs rows actually emitted for that company. |
error | Reason, when not ok. |
FAQ
Do I need a proxy? No. SmartRecruiters's Posting API is public with no anti-bot. The proxy field is available only for optional IP rotation at very large scale.
Why two requests per job? The SmartRecruiters list endpoint returns summaries only; the full description lives on each posting's detail endpoint. We fetch detail only up to maxItems, and not at all when includeDescription is off — keeping big-board runs fast and cheap.
Can it discover every company on SmartRecruiters? No — SmartRecruiters has no public directory of all boards (true for every ATS scraper). You supply the companies you care about.
How many jobs per company? Whatever they have open — use maxItems to cap total output and control cost.
How fresh is the data? Live — every run hits SmartRecruiters in real time.
Support
Found a bug or need a field added? Open an issue on the actor's Issues tab in the Apify Console.
Additional services
Need a different ATS or job board? We also build scrapers for Ashby, Greenhouse, Workday, Indeed, LinkedIn, Glassdoor, and many more. Check our Apify Store profile.
Explore more scrapers
- Ashby / Greenhouse / Lever Jobs Scrapers — open roles from those ATS platforms.
- Workday Jobs Scraper — jobs from any Workday career site.
- Indeed / LinkedIn / Glassdoor — the major job boards, fast and structured.
⚠️ Disclaimer
This actor collects only publicly available job-posting data exposed by SmartRecruiters's own public Posting API. It does not access private, authenticated, or personal data, and does not bypass any access control. You are responsible for using the scraped data in compliance with SmartRecruiters's terms, the source companies' terms, and all applicable laws (including GDPR/CCPA). Use the data ethically and lawfully.
SEO Keywords
SmartRecruiters scraper, SmartRecruiters jobs scraper, smartrecruiters.com scraper, SmartRecruiters Posting API, SmartRecruiters ATS scraper, scrape SmartRecruiters jobs, careers.smartrecruiters.com scraper, ATS job scraper, enterprise jobs scraper, job postings API, company careers scraper, hiring data, recruiting data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![👁 Lever Jobs [$0.99] Scraper & API — Any Company avatar](https://images.apifyusercontent.com/_O59p-0aJZTFwFCTm0uCphWnqZ64TLsp4-QoJcjUXFQ/rs:fill:76:76/cb:1/aHR0cHM6Ly9hcGlmeS1pbWFnZS11cGxvYWRzLXByb2QuczMudXMtZWFzdC0xLmFtYXpvbmF3cy5jb20vbmduOHZSRVNUa3NleVdFNnAtYWN0b3ItTU9EU2JIY0JqbUxKRnRqRnYtb1ZqU1BIZmRaaC1sZXZlci5wbmc.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
![👁 Ashby Jobs [$0.9💰] API Scraper | Any Company (/w EMAILS) avatar](https://images.apifyusercontent.com/lyplOop0WzFs_Xh4Mb1yzcEeJc8YDkvFuy97Io9rRcU/rs:fill:76:76/cb:1/aHR0cHM6Ly9hcGlmeS1pbWFnZS11cGxvYWRzLXByb2QuczMudXMtZWFzdC0xLmFtYXpvbmF3cy5jb20vbmduOHZSRVNUa3NleVdFNnAtYWN0b3ItVHZoQXJlbGVjeER4clhMZ08tS3NDTnBlVm5pRi1Bc2hieS5qcGVn.webp){kind=link}