 |
VOOZH | about |
|
VOOZH | about |
“More compute!” is a common refrain these days in discussions about enhanced LLM performance and capability. Just scan a few recent headlines to see the resources major companies are willing to pour into getting it. In a broad sense, this refers to more and better hardware used in model training. After training, though, inference time compute and test time compute come into play. Read on to demystify these concepts, clarify their differences and similarities, and understand how tools like PromptLayer can play a role in optimizing these stages.
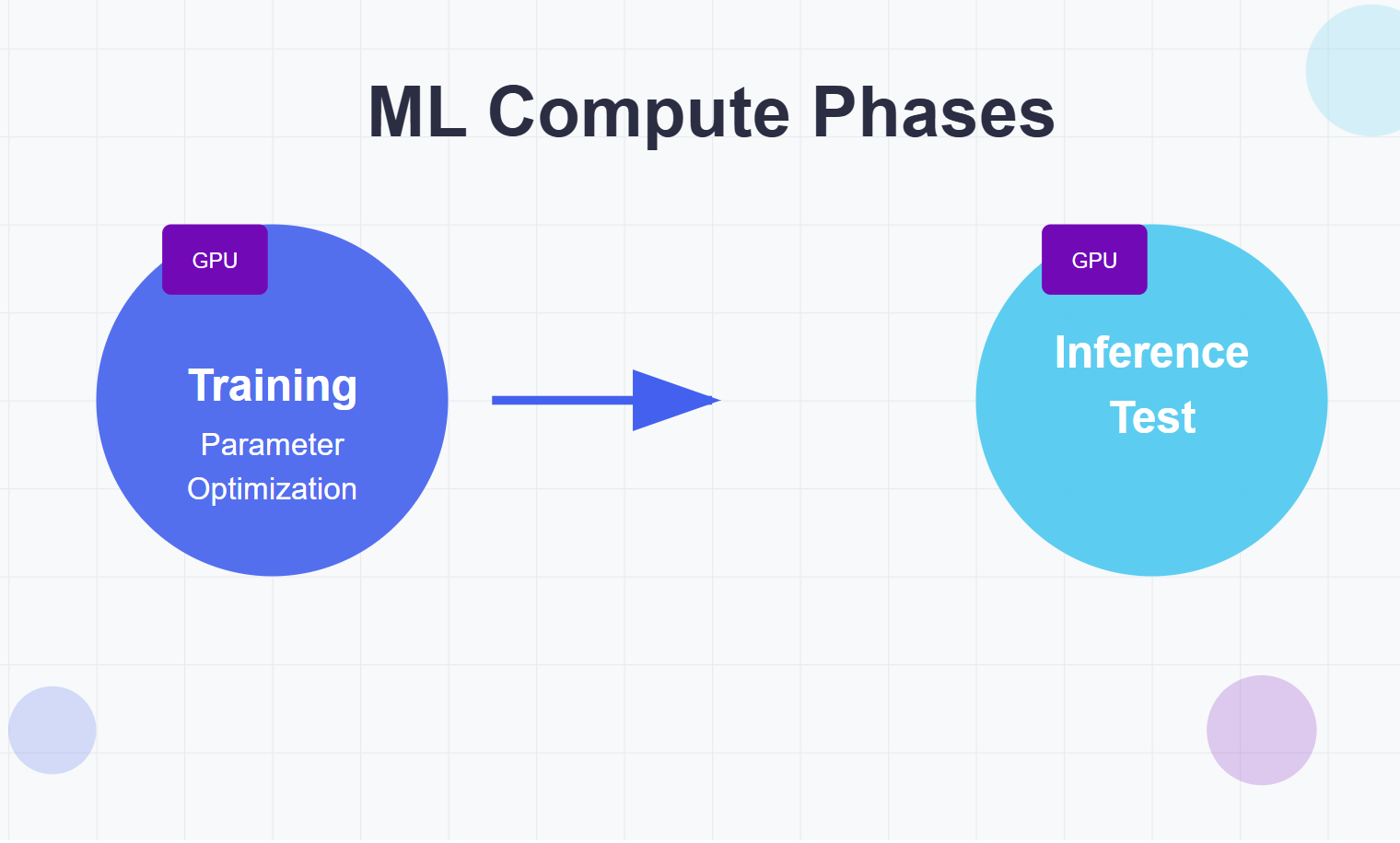
Every ML model goes through distinct phases:
The terms inference time and test time are often used interchangeably to refer to the post-training phase, but there is some nuance between the two. If you will humor my college football analogies, you can think of these loosely as game day (inference time) vs practice (test time) performance.
Inference time compute refers to the amount of computational power and time required for a trained model to make predictions on new data, such as end-user inputs. Think of it as game day performance. This is like if Coach Prime were to measure how long it takes Travis Hunter to react to an incoming pass, decide his path, and then make it to the end zone on game day after months of training.
Key impacts of inference time compute:
Test time compute generally means the computational effort expended when using or evaluating the model after training. Essentially, another way to describe inference-phase computation, but often in a more controlled environment. This is when Coach Prime is improving Travis Hunter’s performance in practice sessions and figuring out what to add to his training regimen–from new drills to weight training to nutrition–so that he does even better on game day.
Test time compute has gained particular traction in recent AI research, especially around large language models, to denote strategies that intentionally increase computation during inference to improve results. In other words, instead of just doing a single quick prediction, the model might do extra work to yield a better answer. In our football analogy, ideally, you don't want your wide receiver to take too much time to score since that leaves him vulnerable to the other team's defensive efforts, but even an extra couple of milliseconds spent looking for the best path to the end zone, and then doing what it takes to get there, can be worth it.
Key characteristics and uses of test time compute:
State-of-the-art reasoning models such as OpenAI's o-series with o1, o4, and o3, Gemini advanced with 1.5 Pro and 2.0, as well as DeepSeek r1 all aim to trade lower inference time compute for better, more robust answers. Rather than relying on a single forward pass and pattern recognition, these models take extra time and resources and use simulated "reasoning" through chain-of-thought to arrive at their answers. The difference extra compute can make is incredible. By allocating more compute at inference, sometimes even a smaller model can outperform a larger one by taking the time to refine its answer through multiple reasoning steps. The trade-off, of course, comes in latency and scaling considerations.
To that effect, some models like o3 mini allow the user to dial the inference effort up or down. o3-mini-high, for example, uses more (i.e. higher) reasoning than o3 mini. DeepSeek R1, meanwhile, uses a mixture-of-experts (MoE) architecture which lowers inference time while still delivering high-quality results. For an app where low-latency is paramount, a lower reasoning, lower inference time model is likely a better choice, especially as different models continue to shrink the gap between compute time and quality, robust results.
Optimizing inference isn’t only about the model’s code or weights. Crafting effective prompts (aka prompt engineering) can reduce the need for brute-force compute at inference by guiding the model to the answer more directly.
Here’s how a tool like PromptLayer can be beneficial:
Inference time compute and test time compute are two sides of the same coin – both concern the resources and strategies used when applying a machine learning model after it’s trained. Keeping inference efficient is vital for practical deployments, yet selectively increasing compute at test time (through clever algorithms or prompt strategies) can significantly boost results when needed.
© Copyright 2026 Magniv, Inc. All rights reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}